

fluem读取文件并写入到hadoop的hdfs
接上一章,本章介绍使用 crontab 像指定文件定时写入,使用fluem 读取并写入到hadoop的hdfs 前提准备已安装好fluem ,和hadoop(推荐单机即可毕竟做实验)
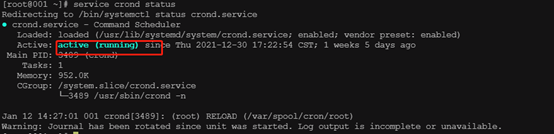
一、进入终端执行命令查看 crond 服务状态
service crond status
如下表示服务正常运行,如无服务或服务关闭,需自行安装启动(略)
二 、执行命令 crontab –e 配置定时任务
crontab –e
写入 如下内容(表示每分钟向opt/software/test.log 插入一条数据)
*/1 * * * * /bin/echo "test===================>flume" >> /opt/software/test.log

三、配置fluem agent配置文件 读取/opt/software/test.log 并写出到hdfs
进入job目录下创建file-flume-hdfs.conf
cd /usr/local/flume/job/
mkidr file-flume-hdfs.conf
添加如下内容
# example.conf: 一个单节点的 Flume 实例配置 # 配置Agent a1各个组件的名称 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 配置Agent a1的source r1的属性 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/software/test.log # 配置Agent a1的sink k1的属性 a1.sinks.k1.type = hdfs # 配置hdfs地址加要生成的目录和文件格式,此处按时间生成 a1.sinks.k1.hdfs.path = hdfs://10.0.2.66:9001/flume/%Y%m%d/%H # 文件前缀 a1.sinks.k1.hdfs.filePrefix = logs- # 滚动生成 a1.sinks.k1.hdfs.round = true # 每分钟 a1.sinks.k1.hdfs.roundValue = 1 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.batchSize = 100 a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.rollInterval = 30 a1.sinks.k1.hdfs.rollSize = 134217700 a1.sinks.k1.hdfs.rollCount = 0 # 配置Agent a1的channel c1的属性,channel是用来缓冲Event数据的 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 把source和sink绑定到channel上 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
四、启动flume agent(要确保hadoop在线并且网络通畅)
bin/flume-ng agent --conf conf/ --conf-file ../job/file-flume-hdfs.conf --name a1
执行成功,日志打印如下
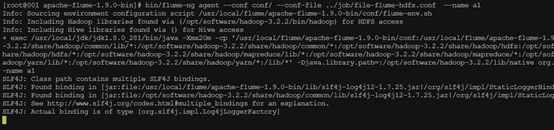
进入到flume安装目录的conf下查看flume.log,可以看到已经生成文件

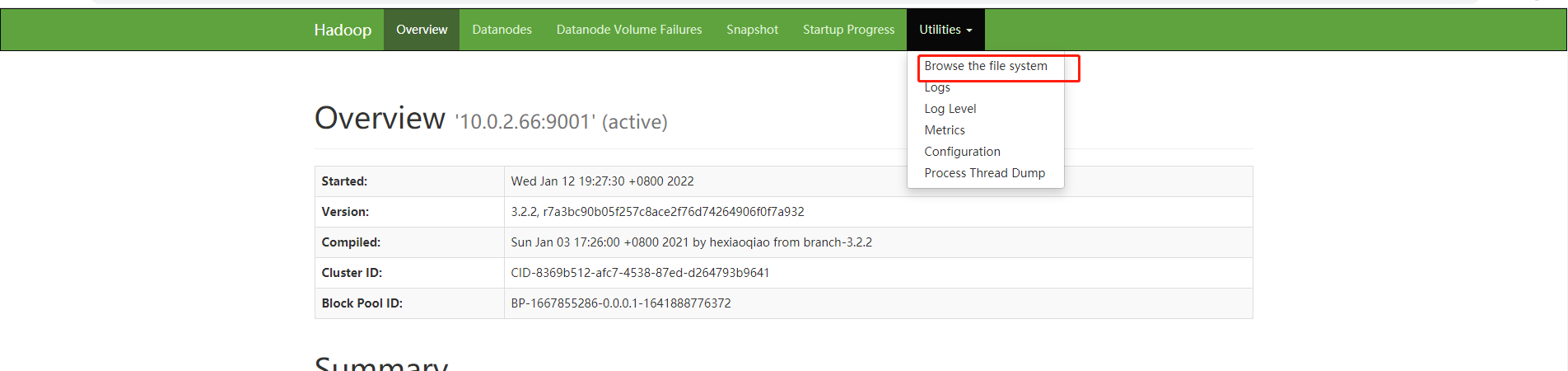
五、 访问hadoop的web控制台查看
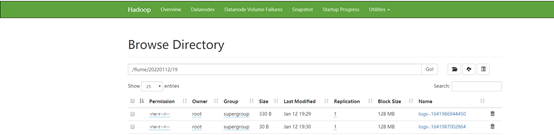
文件已生成,可下载查看
!!!

