

flume安装及使用
最近在学习hadoop大数据平台,但是却感觉无从下手,于是看了一些专业的书籍,觉得还是先从下往上为学习也就是从源数据——数据抽取——存储——计算——展示这个路线来学习比较容易一些,所以就先从非结构化数据传输工具flume开始。下面介绍flume 的安装及简单使用
Flume是一个分布式、高可靠、高可用的用来收集、聚合、转移不同来源的大量日志数据到中央数据仓库的工具,下面是官方给出的一个工作流程图:
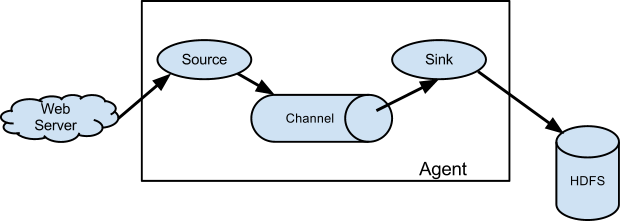
流程图中很清楚的描述了fluem的工作流程,落盘数据被读取到 agent的Source ,Source进入到指定的Channel ,然后发送到指定的Sink ,Sink发送到目标端。其中Source 可以对应多个Channel,但是sink只能绑定一个Channel。下面开始安装和初步试验。
前提准备:安装java JDK并配置好环境变量
一、官网下载安装包 https://flume.apache.org/ (不得不说,flume的官网真是技术官网典范)
二、将安装包上传到服务器 /opt/software/ 下 (无software的话需自行创建)
三、在/usr/local/下创建flume 文件夹
cd /usr/local/
mkdir flume
四、将压缩包解压到/usr/local/ flume 下(注意tar包名称和路径)
1 | tar -xzvf xxx.tar.gz -C ./ |

解压后的文件夹结构如下
五、进入conf目录修改flume启动文件
1 | cd conf/ |
重命名将 flume-env.sh.template 改为 flume-env.sh

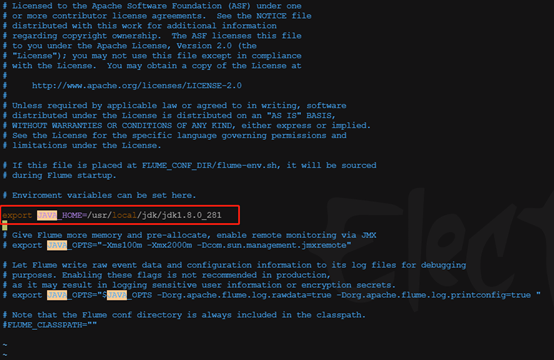
编辑flume-env.sh 配置JAVA_HOME 为jdk的安装目录
1 | vim flume-env.sh |
完毕!但是为了进一步验证flume工作是否正常,还需要做一个小场景的测试,就是使fluem 监听一个指定的端口,把从该端口收到的TCP协议的文本数据按行转换为Event,它能识别的是带换行符的文本数据,同其他Source一样,解析成功的Event数据会发送到channel中,然后在控制台打印,用到的source是 NetCat TCP Source,用到sink是Logger Sink 。
六、安装netcat (用于向指定端口发送数据)
1 | yum install –y nc |
七、创建flume agent 配置文件
在flume文件夹下创建 job文件夹(位置自定义),并在job文件夹下创建配置文件
1 | mkdir /usr/local/flume/job<br>cd job<br>touch netcat-flume-logger.conf |
编辑配置文件,添加如下配置
vim netcat-flume-logger.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # example.conf: 一个单节点的 Flume 实例配置# 配置Agent a1各个组件的名称a1.sources = r1a1.sinks = k1a1.channels = c1# 配置Agent a1的source r1的属性a1.sources.r1.type = netcata1.sources.r1.bind = localhosta1.sources.r1.port = 44444# 配置Agent a1的sink k1的属性a1.sinks.k1.type = logger# 配置Agent a1的channel c1的属性,channel是用来缓冲Event数据的a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# 把source和sink绑定到channel上a1.sources.r1.channels = c1a1.sinks.k1.channel = c1 |
八、Fluem安装目录下启动fluem agent 指定conf ,指定配置文件名,指定agent名称
1 | bin/flume-ng agent --conf conf/ --conf-file ../job/netcat-flume-logger.conf --name a1 -Dflume.root.logger=INFO,console |
控制台打印 本机监听在44444端口,启动成功
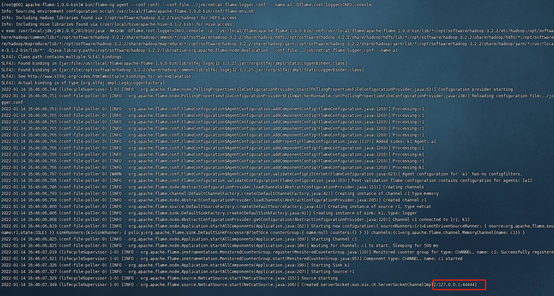
九、使用netcat像fluem发送消息
重新开启一个终端 执行命令连接到44444端口,并发送消息
1 | nc localhost 44444 |
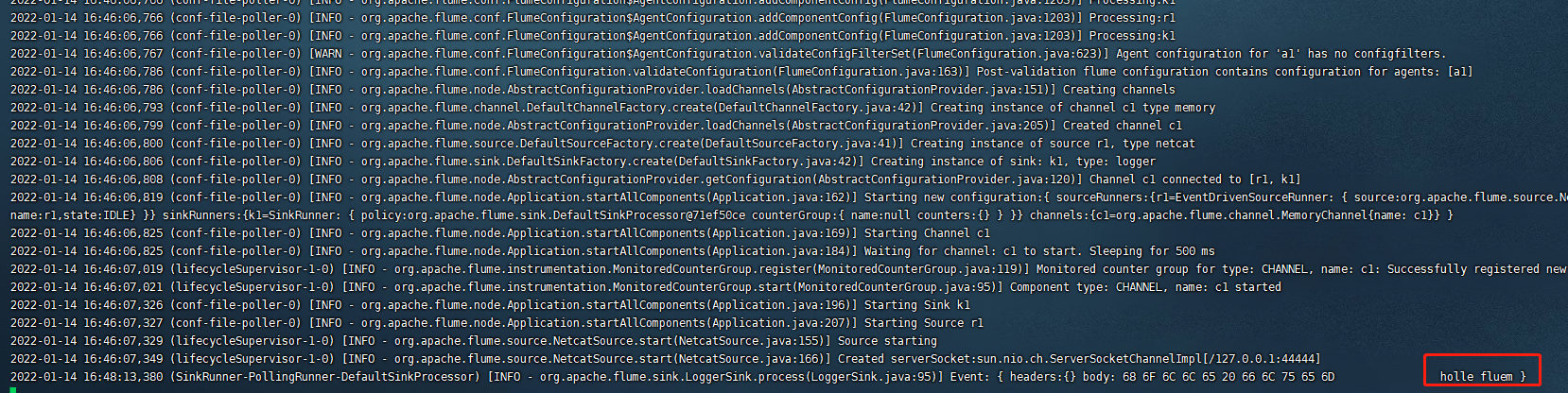
发送消息 holle flume

控制台成功接收并打印
下一章记录如和配合hadoop平台使用,读取文件内容并发送到hdfs


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具