HashMap与ConcurrentHashMap的区别
从JDK1.2起,就有了HashMap,HashMap不是线程安全的,因此多线程操作时需要格外小心。
在JDK1.5中,Doug Lea给我们带来了concurrent包,从此Map也有安全的了。
ConcurrentHashMap具体是怎么实现线程安全的呢,肯定不可能是每个方法加synchronized,那样就变成了HashTable。
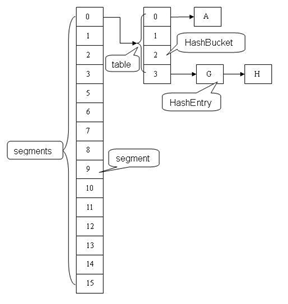
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中:
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁,可以简单理解成把一个大的HashTable分解成多个,形成了锁分离。
ConcurrentHashMap(整个Hash表),Segment(桶),HashEntry(节点)
测试程序:
ConcurrentHashMap中默认是把segments初始化为长度为16的数组。
根据ConcurrentHashMap.segmentFor的算法,3、4对应的Segment都是segments[1],7对应的Segment是segments[12]。
(1)Thread1和Thread2先后进入Segment.put方法时,Thread1会首先获取到锁,可以进入,而Thread2则会阻塞在锁上:
(2)切换到Thread3,也走到Segment.put方法,因为7所存储的Segment和3、4不同,因此,不会阻塞在lock():
以上就是ConcurrentHashMap的工作机制,通过把整个Map分为N个Segment(类似HashTable),可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。
|
作者:(奎恩)quinns 出处:https://www.cnblogs.com/quinnsun/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号