数学基本概念
1、素数:质数(prime number)又称素数,有无限个。在大于1的自然数中,除了1和它本身以外不再有其他因数。
欧拉函数:对正整数n,欧拉函数是小于n的正整数中与n互质的 数 的数目。

从上式来看,要先找到 x 的所有的质因数。然后才能用上式求其欧拉函数。
注意:每种质因数只一个。 比如12=2*2*3那么φ(12)=12*(1-1/2)*(1-1/3)=4
2、极大似然估计:
极大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
3、欧氏距离:
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
二维空间的公式
三维空间的公式
4、最小二乘法(最小平方法):
https://blog.csdn.net/bitcarmanlee/article/details/51589143
最小二乘估计法,又称最小平方法,是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘估计法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。
假设身高是变量X,体重是变量Y,我们都知道身高与体重有比较直接的关系。生活经验告诉我们:一般身高比较高的人,体重也会比较大。但是这只是我们直观的感受,只是很粗略的定性的分析。在数学世界里,我们大部分时候需要进行严格的定量计算:能不能根据一个人的身高,通过一个式子就能计算出他或者她的标准体重?
接下来,我们肯定会找一堆人进行采用(请允许我把各位当成一个样本)。采样的数据,自然就是各位的身高与体重。(为了方便计算与说明,请允许我只对男生采样)经过采样以后,我们肯定会得到一堆数据(x1,y1),(x2,y2),⋯,(xn,yn),其中x是身高,y是体重。
得到这堆数据以后,接下来肯定是要处理这堆数据了。生活常识告诉我们:身高与体重是一个近似的线性关系,用最简单的数学语言来描述就是y=β0+β1x。于是,接下来的任务就变成了:怎么根据我们现在得到的采样数据,求出这个β0与β1呢?这个时候,就轮到最小二乘法发飙显示威力了。
为了计算β0,β1的值,我们采取如下规则:β0,β1
应该使计算出来的函数曲线与观察值的差的平方和最小。用数学公式描述就是:
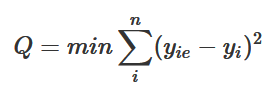
其中,yie表示根据y=β0+β1x估算出来的值(估计值),yi是观察得到的真实值。
求导,结束。
5、机器学习之 正则化 项
https://www.cnblogs.com/jianxinzhou/p/4083921.html
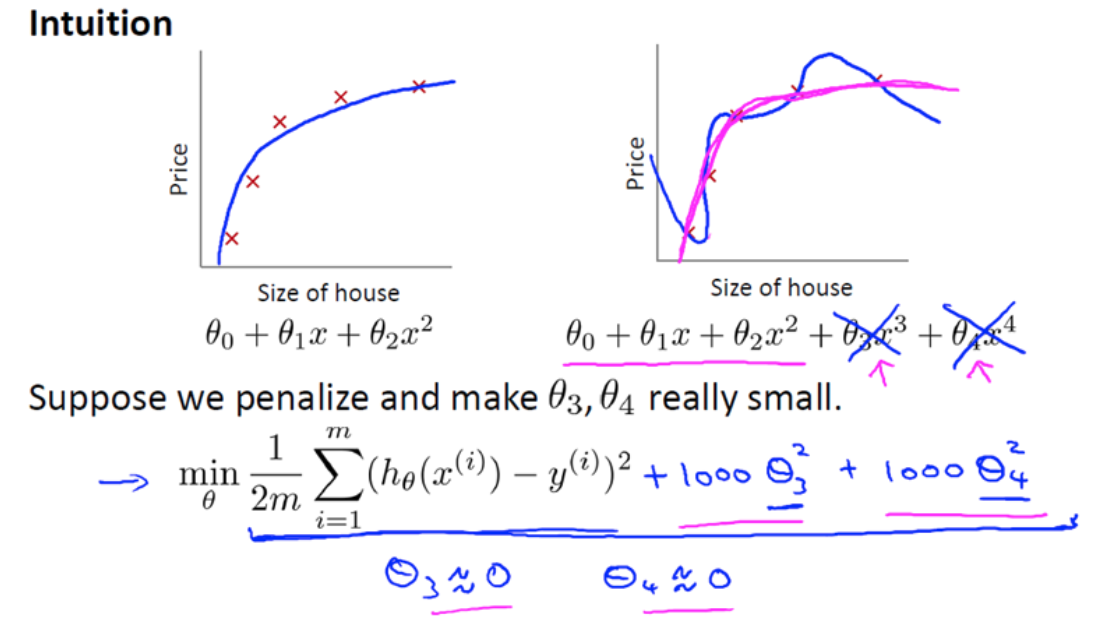
正则化项:
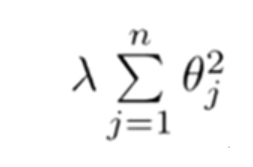
为正则化参数。
因此,我们最终恰当地拟合了数据,我们所使用的正是二次函数加上一些非常小,贡献很小项(因为这些项的 θ3、 θ4 非常接近于0)。显然,这是一个更好的假设。
实际上,这些参数的值越小,通常对应于越光滑的函数,也就是更加简单的函数。因此 就不易发生过拟合的问题。
顺便说一下,按照惯例,我们没有去惩罚 θ0,因此 θ0 的值是大的。这就是一个约定从 1 到 n 的求和,而不是从 0 到 n 的求和。但其实在实践中
这只会有非常小的差异,无论你是否包括这 θ0 这项。但是按照惯例,通常情况下我们还是只从 θ1 到 θn 进行正则化。
λ 要做的就是控制在两个不同的目标中的平衡关系。
6、全概率公式
P(A)=P(B1)P(A|B1)+P(B2)P(A|B2)+P(B3)P(A|B3)+⋯
可以发现,虽然P(A)P(A)本身不好求,但我们可以根据它散落的“碎片”间接地将其求出。但不是所有情况都是能这样求出的——我们必须保证B1B1,B2B2,B3B3,⋯⋯是一个完备事件群。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号