R 分组计算描述性统计量
统计学区内各个小区的房价均值
数据格式
|
id|community_name|house_area|house_structure|house_total|house_avg|agency_name|house_floor_curr|house_floor_total|house_floor_type 6328500962692431872|尚东花园|77.0|3室2厅|285.0|37013.0|利众置业|5|5|多层 6328500979813580800|赛世香樟园|93.0|2室2厅|265.0|28495.0|苏商房产仙林店|9|11|小高层 |
导入数据
|
house<- read.table("house_data.txt", header = TRUE, sep='|',fileEncoding ="UTF-8", stringsAsFactors = FALSE, colClasses = c("character","character","numeric", "character","numeric","numeric","character", "numeric","numeric","character")) houseXQ<- sqldf("select * from house where community_name!='东郊小镇' ",row.names=TRUE) |
选择列
|
selectedColumns<- c("community_name","house_avg") |
将小区名转换成因子
communityFactor<- factor(houseXQ$community_name, order=FALSE)
|
将因子列整合到数据框中
houseXQ <-cbind(houseXQ, communityFactor)
|
重新选择列
selectedColumns<- c("communityFactor","house_avg")
|
看一下数据
head(houseXQ[selectedColumns])
|
按小区名分组计算均值
aggregate(houseXQ[selectedColumns], by=list(communityFactor=houseXQ$communityFactor),mean)
|
结果:
自定义函数计算统计量
|
funcMystats<- function(x, na.omit= FALSE){ if(na.omit){ x<- x[!is.na(x)] } m<- mean(x) n<- length(x) s<- sd(x) skew<- sum((x-m)^3/s^3)/n kurt<- sum((x-m)^4/s^4)/n-3 return (c(n=n,mean=m, stdev=s, skew=skew, kurtosis=kurt)) }
funcDstats <- function(x) sapply(x, funcMystats)#对于每个X调用 funcMystats 函数
by(houseXQ[selectedColumns], houseXQ$community_name, funcDstats)
|
结果(部分)
houseXQ$community_name: 东方天郡 communityFactor house_avg n 51 51.0000000 mean NA 38255.8039216 stdev 0 2145.6443696 skew NA -0.4395676 kurtosis NA 0.6015383 ------------------------------------------------------------
houseXQ$community_name: 康桥圣菲 communityFactor house_avg n 9 9.0000000 mean NA 34359.0000000 stdev 0 1567.1059313 skew NA -0.9804274 kurtosis NA -0.8342473 ------------------------------------------------------------
houseXQ$community_name: 南师大茶苑 communityFactor house_avg n 1 1 mean NA 31691 stdev NA NA skew NA NA kurtosis NA NA ------------------------------------------------------------
houseXQ$community_name: 赛世香樟园 communityFactor house_avg n 3 3.0000000 mean NA 28938.3333333 stdev 0 1654.1733081 skew NA 0.2487582 kurtosis NA -2.3333333 ------------------------------------------------------------
houseXQ$community_name: 三味公寓 communityFactor house_avg n 2 2.0000 mean NA 28662.0000 stdev 0 576.9991 skew NA 0.0000 kurtosis NA -2.7500 ------------------------------------------------------------
houseXQ$community_name: 尚东花园 communityFactor house_avg n 1 1 mean NA 37013 stdev NA NA skew NA NA kurtosis NA NA ------------------------------------------------------------
|
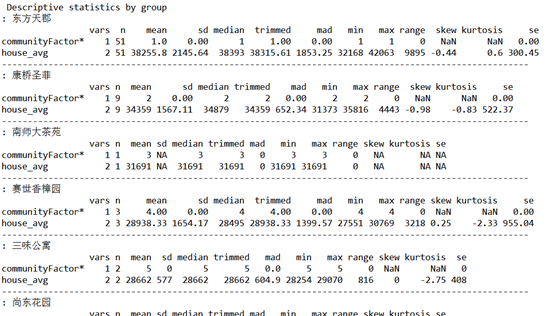
使用 psych 包中的 describeBy()分组计算概述统计量
library(psych)
selectedColumns<- c("communityFactor","house_avg")
describeBy(houseXQ[selectedColumns], list(houseXQ$communityFactor))
|
结果如下(部分)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号