2019寒假训练营第二次作业
学习视频课程(20')
程序题(80'+50')
热身题(20')
学习基本的文件读写
读提供的文件Request.txt
把里面的内容写到output.txt
基本题(60')
根据提供请求的输入Request.txt,把所有请求和对应的信息大小都存下来。
统计每个发送方的总请求大小S,S超过T的就认定为黑客,把他们的名字存进你的黑名单里。
输出黑客的个数,和这些黑客的名字。
开放题(50')
现在你已经暂时恢复了服务。但你发现,1的方法很笨,例如:把所有请求都存下来,再统计总值,花费了你大量的存储空间。这里面包含了很多不必要的操作,有很多缺点。
吐槽1方法,找到这个方法的问题。给出你的方法,不一定是完美的,说出方法的优缺点,只要能自圆其说。(可以从速度、占用的空间、准确率等方面思考)
选做:实现你的方法
思路
热身题:
建立结构体,定义数组,打开并读写文件,最后关闭文件。运行效果如下:
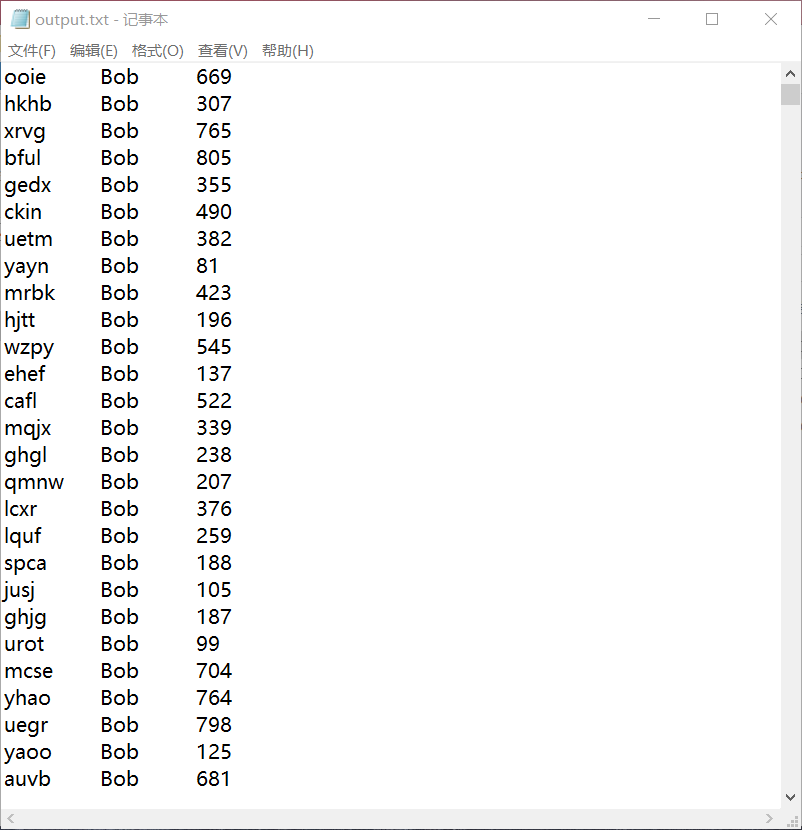
基础题:
在热身题的基础上进行改动,再定义一个结构体数组,同时计算出相同名字的发送方的信息大小的和,然后判断是否大于1500并进行是否重复的判断,若满足条件则加入新建立的结构体,最后输出即可。运行效果如下:
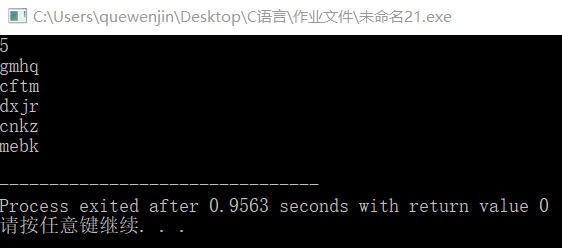
开放题:
吐槽:
- 该方法要求储存所有请求和信息,当信息量比较大时,耗时而且占用的临时内存较大。
- 判断方式不够完善,单纯以信息量总和是否大于1500进行判断,可能导致顾客被误加入黑名单或者黑客无法被全部加入黑名单,准确度不够高。且当信息量较大时,更容易发生误杀。
- 灵活性低总信息量超出int范围和用户名超出定义的数组范围都将影响程序运行。
改进:
- 正常人发送消息速度有限,频率太高应该就是黑客没错,可以先对所有所有信息按用户名排序,再筛选出短时间内发送消息频率较高的用户列入黑名单。
- 黑客发的骚扰信息信息量比较小只是数量多,我觉得应该设定单次发送信息量的下限和上限,储存时跳过信息量不达标的信息,这样能节省一定的运行时间和内存。
- 适当调整定义的数据范围,保证程序的正常运行,如果可以的话我还想适当调大T的大小,感觉1500有点小。
优点:提高了一定的准确度,节省了一定的运行时间和内存。
缺点:对单次信息量大小进行限制也可能会造成误杀。
实现:暂时没有实现

