【python基础之可变和不可变数据类型】--- python之堆的介绍
【一】堆
-
堆--简介:一种基于树的数据结构
堆是满足堆特性的完全二叉树,即树中每个节点的值大于或等于其子节点的值。
有两种类型的堆:
1. 最大堆:在最大堆中,每个节点的值都大于或等于其子节点的值,并且根节点在树中具有最大值。
2. 最小堆:在最小堆中,每个节点的值都小于或等于其子节点的值,并且根节点在树中具有最小值。
堆排序如何工作
堆排序是一种基于比较的排序算法,它使用堆数据结构对元素列表进行排序。它的工作原理是从输入列表构建一个堆,然后重复提取根元素(最大值或最小值)并将其放在排序列表的末尾。重复此过程,直到堆为空并且列表已完全排序。
简单来说,有两个步骤:
1. 构建堆
2. 从堆中提取元素
如何在 Python 中表示堆?
首先,我们需要知道如何在构建堆之前正确地表示它。
鉴于堆是一棵完全二叉树,我们可以直接使用 Python 列表来表示堆。
树的列表表示意味着真正的树在我们的脑海中。我们总是在真实代码中操作列表。
它之所以起作用,是因为列表和树之间存在以下特殊关系:
树的根始终是 index 处的元素0。
index 处节点的左孩子i存储在 index2i+1中,右孩子存储在 index2i+2中。
因此,我们总是可以通过列表的索引轻松访问树的节点。
例如,这是一个名为 的输入列表arr。
它的元素是[5, 2, 7, 1, 3]。
它代表一个原始的完全二叉树,我们需要将它转换为一个堆,如下所示:

- 树的根是arr[0]
- 根的左孩子是arr[20+1],右孩子是arr[20+2]。
如何建堆?
从列表构建堆的过程称为 heapify。
原始列表已经是二叉树的表示(树在我们的脑海中),如上所示。我们需要做的是将原始树转换为堆。
由于最大堆和最小堆具有相似的思想。下面就说说如何建立最大堆吧。
思路是自下而上遍历二叉树的非叶子节点构造一个最大堆,对于每个非叶子节点,将其与其左右子节点进行比较,将最大值与父节点交换这个子树。
为什么从非叶节点而不是最后一个节点开始?
因为叶子节点下面没有子节点,所以不需要操作。
为什么从下往上遍历而不是从上往下遍历?
如果我们从底部往上走,肯定会将最大值放入根节点(类似于冒泡排序的思想)。
堆的实现
- 下文实现的是大顶堆。若要将其转换为小顶堆,只需将所有大小逻辑判断取逆
基于数组的实现
(1)堆的存储与表示
- 我们在二叉树章节中学习到,完全二叉树非常适合用数组来表示。
- 由于堆正是一种完全二叉树,我们将采用数组来存储堆。
- 当使用数组表示二叉树时,元素代表节点值,索引代表节点在二叉树中的位置。
- 节点指针通过索引映射公式来实现。
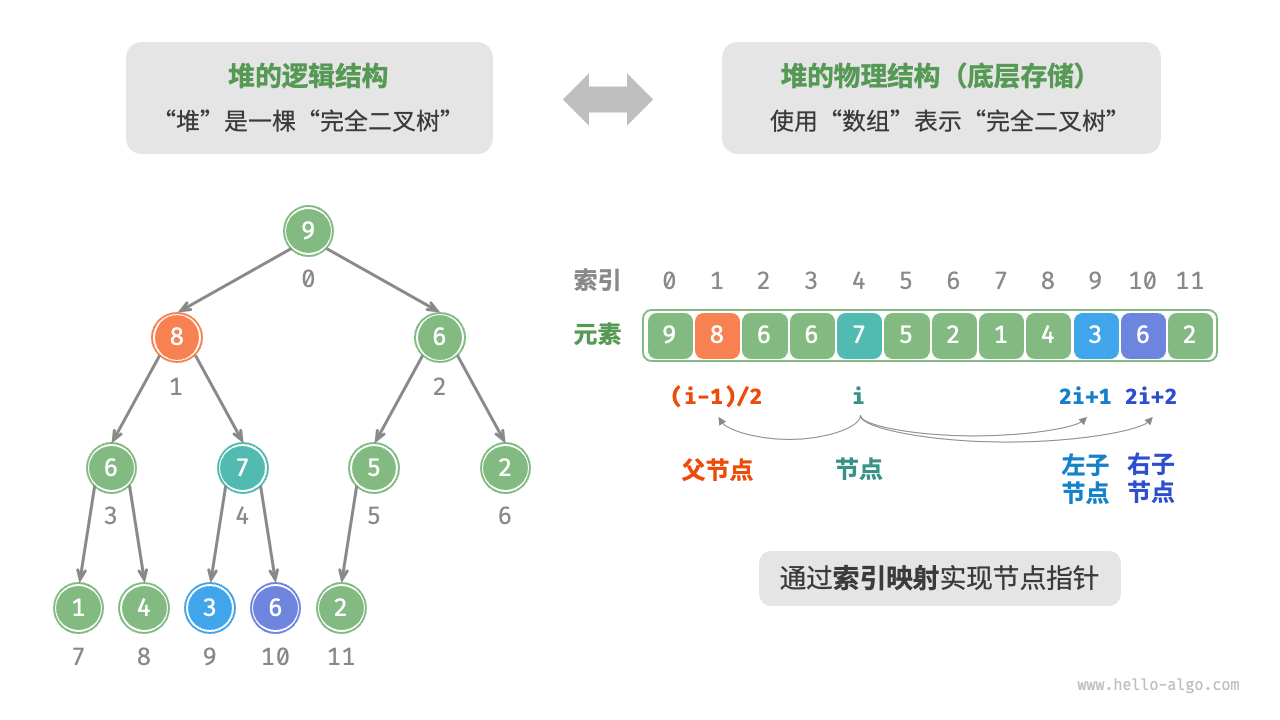
- 我们可以将索引映射公式封装成函数,方便后续使用。
def left(self, i: int) -> int:
"""获取左子节点索引"""
return 2 * i + 1
def right(self, i: int) -> int:
"""获取右子节点索引"""
return 2 * i + 2
def parent(self, i: int) -> int:
"""获取父节点索引"""
return (i - 1) // 2 # 向下整除
(2)访问堆顶元素
- 堆顶元素即为二叉树的根节点,也就是列表的首个元素。
def peek(self) -> int:
"""访问堆顶元素"""
return self.max_heap[0]
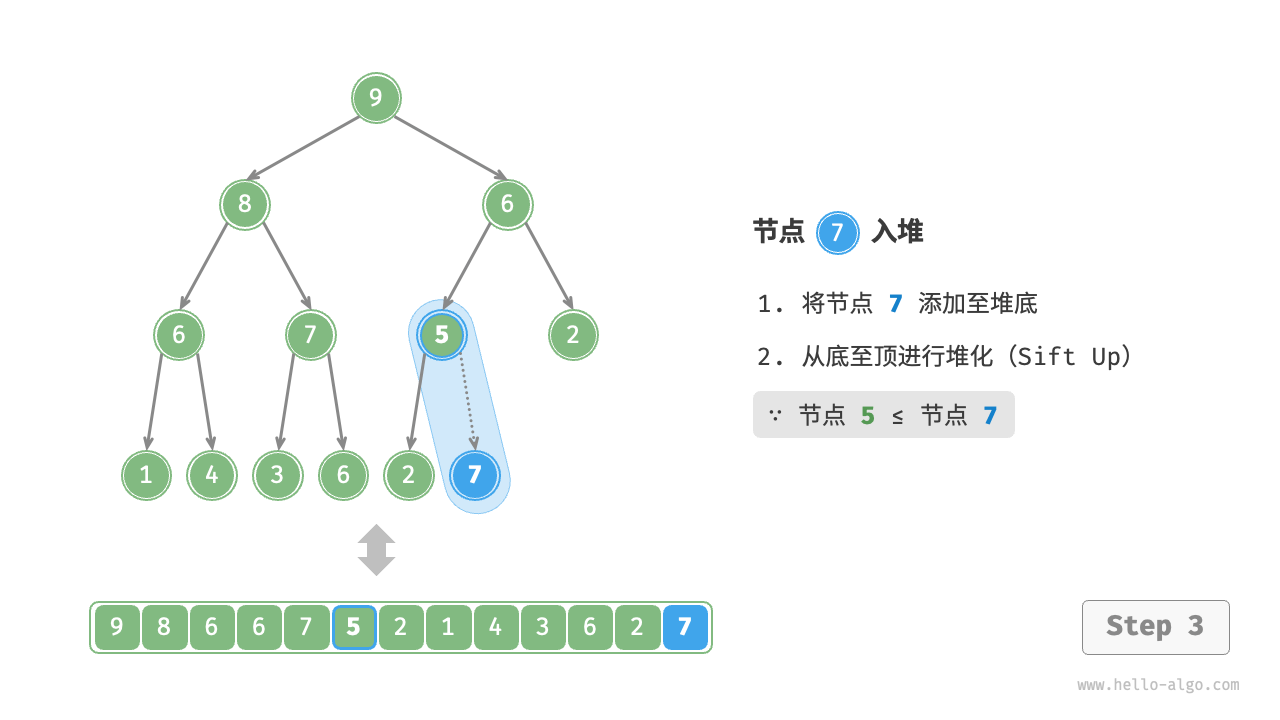
(3)元素入堆
- 给定元素
val,我们首先将其添加到堆底。添加之后,由于 val 可能大于堆中其他元素,堆的成立条件可能已被破坏。- 因此,需要修复从插入节点到根节点的路径上的各个节点,这个操作被称为「堆化 heapify」。
- 考虑从入堆节点开始,从底至顶执行堆化。
- 如图 8-3 所示,我们比较插入节点与其父节点的值,如果插入节点更大,则将它们交换。
- 然后继续执行此操作,从底至顶修复堆中的各个节点,直至越过根节点或遇到无须交换的节点时结束。
def push(self, val: int):
"""元素入堆"""
# 添加节点
self.max_heap.append(val)
# 从底至顶堆化
self.sift_up(self.size() - 1)
def sift_up(self, i: int):
"""从节点 i 开始,从底至顶堆化"""
while True:
# 获取节点 i 的父节点
p = self.parent(i)
# 当“越过根节点”或“节点无须修复”时,结束堆化
if p < 0 or self.max_heap[i] <= self.max_heap[p]:
break
# 交换两节点
self.swap(i, p)
# 循环向上堆化
i = p
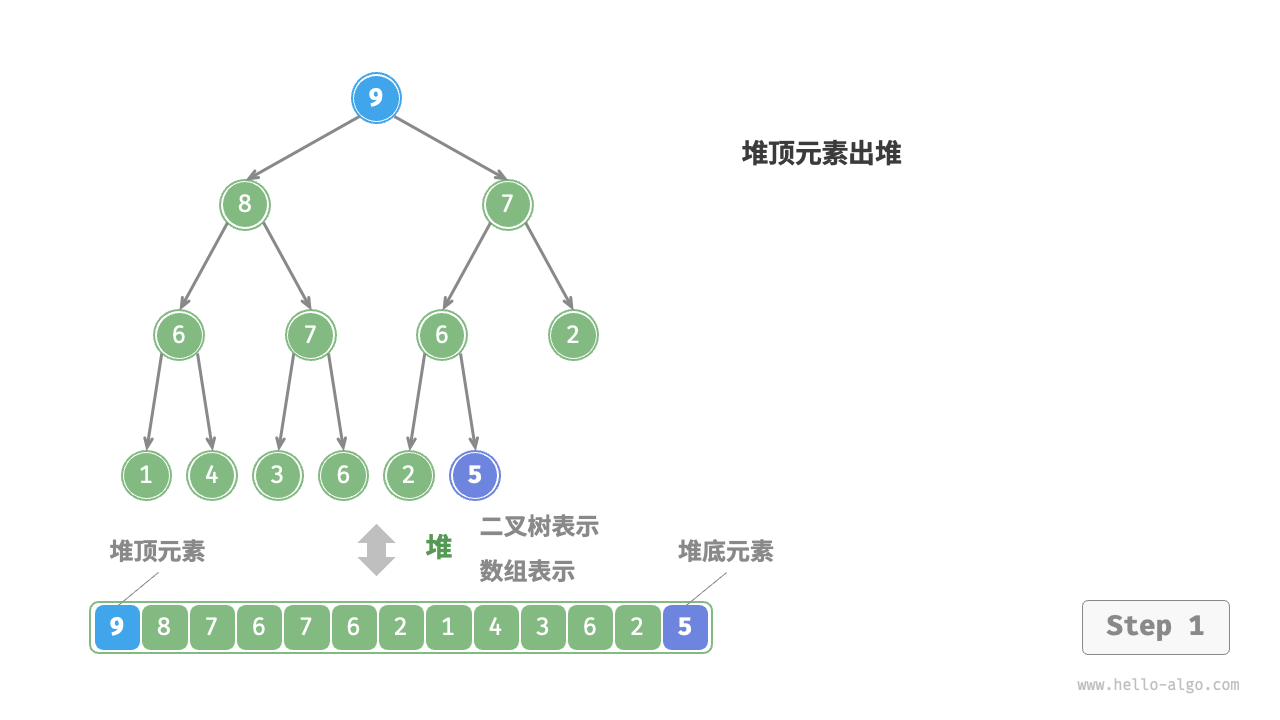
(4)堆顶元素出堆
- 堆顶元素是二叉树的根节点,即列表首元素。如果我们直接从列表中删除首元素,那么二叉树中所有节点的索引都会发生变化,这将使得后续使用堆化修复变得困难。为了尽量减少元素索引的变动,我们采用以下操作步骤。
- 交换堆顶元素与堆底元素(即交换根节点与最右叶节点)。
- 交换完成后,将堆底从列表中删除(注意,由于已经交换,实际上删除的是原来的堆顶元素)。
- 从根节点开始,从顶至底执行堆化。
- 如图 8-4 所示,“从顶至底堆化”的操作方向与“从底至顶堆化”相反,我们将根节点的值与其两个子节点的值进行比较,将最大的子节点与根节点交换。然后循环执行此操作,直到越过叶节点或遇到无须交换的节点时结束。
def pop(self) -> int:
"""元素出堆"""
# 判空处理
if self.is_empty():
raise IndexError("堆为空")
# 交换根节点与最右叶节点(即交换首元素与尾元素)
self.swap(0, self.size() - 1)
# 删除节点
val = self.max_heap.pop()
# 从顶至底堆化
self.sift_down(0)
# 返回堆顶元素
return val
def sift_down(self, i: int):
"""从节点 i 开始,从顶至底堆化"""
while True:
# 判断节点 i, l, r 中值最大的节点,记为 ma
l, r, ma = self.left(i), self.right(i), i
if l < self.size() and self.max_heap[l] > self.max_heap[ma]:
ma = l
if r < self.size() and self.max_heap[r] > self.max_heap[ma]:
ma = r
# 若节点 i 最大或索引 l, r 越界,则无须继续堆化,跳出
if ma == i:
break
# 交换两节点
self.swap(i, ma)
# 循环向下堆化
i = ma
提取一个元素后如何更新堆?
把原来的链表转成堆后,剩下的就简单了。我们只需要反复提取堆的根元素,也就是最大/最小元素,放到需要返回的排序列表的末尾即可。
但是,我们需要做一件事——在提取根节点后更新整个堆。
它需要两个步骤:
用堆中的最后一个元素替换根节点:删除根节点(在最大堆中具有最大值或在最小堆中具有最小值)并将其替换为堆中的最后一个元素。
再次堆化整个堆。
在 Python 中实现堆排序
话不多说,让我们看看代码:
Def heap_sort(arr):
#build a max heap from the input list
Heaping(arr)
#Extract the root element (the maximum value) and place it at the end of the sorted list
sorted_arr = []
while arr:
sorted_arr.append(heappop(arr))
# Return the sorted list
return sorted_arr
def heapify(arr):
#start from the last non-leaf node and heapify all nodes from bottom to top
n = len(arr)
for i in range(n//2 -1,-1,-1):
heapify_node(arr,i,n)
def heapify_node(arr,i,n):
#Heapify the node at index i and its children
left = 2*i + 1
right = 2*i +2
largest =i
if left < n and arr[left] > arr[larfest]:
largest = left
arr[i],arr[largest] = arr[largest],arr[i]
heapify_node(arr,largest,n)
def heappop(arr):
#Extract the root element (the maximum value) from the heap
root = arr[0]
arr[0] = arr[-1]
del arr[-1]
heapify(arr)
return root
print(heap_sort([5,2,7,2077,3,99,4,54,20]))
#[2077,99,54,20,7,5,4,3,2]
关键功能是heapify和heapify_node。它们用于从原始列表构建堆。
使用 Python 的 heapq 模块
幸运的是,我们不需要每次都实现构建堆的基本功能。Python 有一个名为heapq.
该heapq模块提供了处理堆的功能,包括:
heappush(heap, elem):将一个元素压入堆中,保持堆属性。
heappop(heap):从堆中弹出并返回最小的元素,保持堆属性。
heapify(x):在线性时间内将常规列表就地转换为堆。
nlargest(k, iterable, key=None):返回一个列表,其中包含指定迭代器中的 k 个最大元素并满足堆属性。
nsmallest(k, iterable, key=None):返回一个列表,其中包含指定可迭代对象中的 k 个最小元素并满足堆属性。
heapq模块实现为堆队列,即优先级队列实现为堆。它是高效排序和搜索列表和其他可迭代对象的有用工具。
现在,让我们用它来做堆排序:
import heapq
def heap_sort ( arr ):
\# 建立一个堆
heapq.heapify(arr)
\# 从堆中逐一提取元素
sorted_arr = []
while arr:
sorted_arr.append(heapq.heappop(arr))
return sorted_arr
\# 测试堆排序函数
arr = [ 5 , 21 , 207 , 19 , 3 ]
print (heap_sort(arr))
\# 输出:[3, 5, 19, 21, 207]
既简单又优雅
堆常见应用
- **优先队列**:堆通常作为实现优先队列的首选数据结构,其入队和出队操作的时间复杂度均为O(log n),而建队操作为 O(n) ,这些操作都非常高效。
- **堆排序**:给定一组数据,我们可以用它们建立一个堆,然后不断地执行元素出堆操作,从而得到有序数据。然而,我们通常会使用一种更优雅的方式实现堆排序,详见后续的堆排序章节。
- **获取最大的 k 个元素**:这是一个经典的算法问题,同时也是一种典型应用,例如选择热度前 10 的新闻作为微博热搜,选取销量前 10 的商品等。
堆排序的时空复杂度
堆排序的时间复杂度为O(n*logn),其中n是列表中元素的个数。这是因为该heapify函数需要O(logn)时间来堆化单个节点,并且它被调用了O(n)次(堆中的每个节点一次)。该heappop函数还需要O(logn)时间从堆中提取根元素并恢复堆属性,它被调用O(n)times(对列表中的每个元素一次)。
堆排序的空间复杂度为O(1),因为排序是就地完成的,不需要额外的空间。这也是堆排序的一大优势。因为它节省了大量内存使用,尤其是当原始数据集很大时。
本文来自博客园,作者:Unfool,转载请注明原文链接:https://www.cnblogs.com/queryH/p/17875657.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号