数据结构复习---顺序表和链表
1.前言:
最近比较浮躁,想学习一门新的技术却总是浅尝辄止,遇到不懂的地方就想跳过去,时间一长,心态就有点崩了。有一位鸡汤博主感动到了我:"无专注,无风景。不要太贪心,一次只做一件事,而且只做最重要的事。".于是乎,我把家里翻了个底朝天,找到了我垫在床底下的《数据结构》这本书,觉得自己是时候静下心来好好复习一下基础了。今天刚看到顺序表和链表,把我的学习心得记录在这里。也希望自己能坚持,老老实实的把这本书复习完。
2.数据结构的重要性:
讲一门知识之前,通常流程都是要是先吹一波这个东西的重要性,数据结构和算法虽然已经被吹上天了,我还是觉得有必要:众所周知,数据结构是计算机专业中最重要的课程之一,可是为什么呢?用处太多难以列举,总结成一句话就是:可以让你的程序跑更快。今天主要一下顺序表和单链表的原理和实现
3.顺序表:
顺序表是最简单,最常用,最基本的数据结构
特点:1.结构中的元素存在1对1的线性关系,这种1对1的关系指的是数据元素之间的关系
2.位置有先后关系,除第一个位置的元素外,其他位置的元素前面都只有一个数据元素,相反除最后一个位置的数据元素外,其他位置的数据元素后面都只有一个元素。
CLR中的实现:List<T>
顺序表存储结构:

c#实现顺序表(代码中只实现了顺序表的基本功能,没有去做健壮性处理):


/// <summary> /// 顺序表 /// </summary> /// <typeparam name="T"></typeparam> public class ListDS<T> : IListDS<T> { #region 初始化--2019年1月6日23:20:11 /// <summary> ///存储数据 /// </summary> private T[] Data; /// <summary> /// 表示存储了多少数据 /// </summary> private int Count; /// <summary> /// 构造函数 /// </summary> /// <param name="size">数据大小</param> public ListDS(int size) { Data = new T[size]; Count = 0; } public ListDS() : this(10) { } #endregion #region 索引器--2019年1月6日23:20:06 /// <summary> /// 索引器 /// </summary> /// <param name="index"></param> /// <returns></returns> public T this[int index] => GetEle(index); #endregion #region 添加--2019年1月6日23:20:03 /// <summary> /// 添加方法 /// </summary> /// <param name="item">添加的元素</param> public void Add(T item) { if (Count == Data.Length) { Console.WriteLine("当前顺序表已存满"); return; } Data[Count] = item; Count++; } #endregion #region 清空--2019年1月6日23:19:58 /// <summary> /// 清空 /// </summary> public void Clear() { Count = 0; } #endregion #region 插入数据--2019年1月6日23:19:54 /// <summary> /// 插入数据 数组向后移动 /// </summary> /// <param name="item"></param> /// <param name="index"></param> public void Insert(T item, int index) { for (int i = Count - 1; i >= index; i--) { Data[i + 1] = Data[i]; } Data[index] = item; Count++; } #endregion #region 删除--2019年1月6日23:19:51 /// <summary> /// 删除 删除数据后 数组从后往前移动 /// </summary> /// <param name="index"></param> /// <returns></returns> public T Delete(int index) { T temp = Data[index]; for (int i =index+1 ; i < Count; i++) { Data[i - 1] = Data[i]; } Count--; return temp; } #endregion #region 根据索引获取顺序表元素--2019年1月6日23:19:46 /// <summary> /// 根据索引获取顺序表元素 /// </summary> /// <param name="index"></param> /// <returns></returns> public T GetEle(int index) { //判断元素是否存在 if (index >= 0 && index <= Count - 1) { return Data[index]; } return default(T); } #endregion #region 获取数组长度--2019年1月6日23:19:43 /// <summary> /// 获取数组长度 /// </summary> /// <returns></returns> public int GetLength() { return Count; } #endregion #region 是否为空--2019年1月6日23:19:40 /// <summary> /// 是否为空 /// </summary> /// <returns></returns> public bool IsEmpty() { return Count == 0; } #endregion #region 根据元素获取索引--2019年1月6日23:19:36 /// <summary> /// 根据元素获取索引 /// </summary> /// <param name="value"></param> /// <returns></returns> public int Locate(T value) { for (int i = 0; i < Count-1; i++) { if (Data[i].Equals(value)) { return i; } } return -1; } #endregion }
4.链表
顺序表使用地址连续的存储单元顺序存储线性表中的各个数据元素,逻辑上想来的数据元素在物理位置上也相邻,因此,在顺序表中查找任何一个位置上的数据元素非常方便,这是顺序表的有点,BUT,顺序表插入/删除时,需要通过移动数据元素,影响了运行效率,线性表的另外一种存储结构--链式存储(Linkend Storage)这样的线性表叫链表。因此,对链表进行插入和删除时,不需要移动数据元素,但同时也失去了顺序表可随机存储的优点
CLR中的实现:LinkedList<T>
链式存储结构:

c#实现单链表节点:
/// <summary> /// 单链表节点 /// </summary> class Node<T> { #region 初始化 public T data;//存储数据 public Node<T> next;//指针 指向下一个元素 public Node(T _data) { this.data = _data; next = null; } public Node(T _data,Node<T> _node) { this.data = _data; next = _node; } public Node() { this.data = default(T); this.next = null; } public T Data { get { return data; } set { data = value; } } public Node<T> Next { get { return next; } set { next = value; } } #endregion }
c#实现单链表:
/// <summary> /// 单链表 /// </summary> /// <typeparam name="T"></typeparam> public class LinkList<T> : IListDS<T> { #region 初始化 /// <summary> /// 头节点 /// </summary> private Node<T> _head; public LinkList() { _head = null; } #endregion #region 索引器 /// <summary> /// 索引器 /// </summary> /// <param name="index"></param> /// <returns></returns> public T this[int index] => GetEle(index); #endregion #region 添加 /// <summary> /// 添加 /// </summary> /// <param name="item"></param> public void Add(T item) { //1. 创建一个新节点 //2. 如果头节点为空,赋值给头节点 return //3.1 如果头节点不为空 //3.2 创建一个节点指向头节点 //3.3 循环找到尾节点 //3.4 新节点放在尾部 Node<T> newNode = new Node<T>(item); if (_head == null) { _head = newNode; return; } Node<T> temp = _head; while (true) { if (temp.Next != null) { temp = temp.Next; } else { break; } } temp.Next = newNode; } #endregion #region 清空 /// <summary> /// 清空 /// </summary> public void Clear() { //清空头节点,垃圾回收器自动回收所有未引用的对象 _head = null; } #endregion #region 删除 /// <summary> /// 删除 /// </summary> /// <param name="index"></param> /// <returns></returns> public T Delete(int index) { //1.如果是头节点,讲指针指向下一个元素 //2.如果不是头节点,找到要删除节点的前一个节点和要删除的节点 //3.将引用指向要删除的节点的后一个节点 T data = default(T); //删除头节点 if (index == 0) { data = _head.Data; _head = _head.Next; return data; } Node<T> temp =_head; for (int i = 1; i < index - 1; i++) { temp = temp.Next; } Node<T> preNode = temp;//要删除的节点的前一个节点 Node<T> currentNode = temp.Next;//要删除的节点 data = currentNode.Data; Node<T> nextNode = temp.Next.Next; preNode.Next = nextNode; return data; } #endregion #region 根据索引访问 /// <summary> /// 根据索引访问 /// </summary> /// <param name="index"></param> /// <returns></returns> public T GetEle(int index) { Node<T> temp = _head; for (int i = 1; i <=index; i++) { temp = temp.Next; } return temp.Data; } #endregion #region 获取长度 /// <summary> /// 获取长度 /// </summary> /// <returns></returns> public int GetLength() { if (_head == null) { return 0; } int count = 1; Node<T> temp = _head; while (true) { if (temp.Next != null) { count++; temp = temp.Next; } else { break; } } return count; } #endregion #region 插入 /// <summary> /// 插入 /// </summary> /// <param name="item">数据</param> /// <param name="index">位置</param> public void Insert(T item, int index) { //1. 创建一个新节点 //2. 如果索引为0(头节点) 赋值给头节点 return //3.1 如果不是头节点,找到要插入的节点的前一个节点和要插入的节点 //3.2 前一个节点指向新节点 //3.3 新节点指向前一个节点 Node<T> newNode = new Node<T>(item); if (index== 0) { newNode.Next = _head; _head = newNode; return; } Node<T> temp = new Node<T>(); for (int i = 1; i < index-1; i++) { temp = temp.Next; } Node<T> preNode = temp;//要插入的节点的前一个节点 Node<T> curentNode = temp.Next;//要插入的节点 preNode.next = newNode; newNode.Next = curentNode; } #endregion #region 清空 /// <summary> /// 清空 /// </summary> /// <returns></returns> public bool IsEmpty() { return _head == null; } #endregion #region 根据数据访问索引 /// <summary> /// 根据数据访问索引 /// </summary> /// <param name="value"></param> /// <returns></returns> public int Locate(T value) { Node<T> temp = _head; if (temp.Data == null) { return -1; } int index = 0; while (true) { if (temp.Data.Equals(value)) { return index; } else { if (temp.Next != null) { temp = temp.Next; } else { break; } } } return -1; } #endregion }
4.1 双向链表:
单链表允许从一个节点直接访问它的后继节点,所以,找直接后继节点的时间复杂度是O(1),但是,要找某个节点的直接前驱节点,只能从标的头引用开始遍历各节点,时间复杂度是O(n),n是单链表的长度。我们可以在结点的引用于中保存直接前驱节点的地址而,在结点中设两个引用域,一个保存前驱节点(prev),一个保存后继节点(next),这样的链表就是双向链表(Doubly LinkedList)

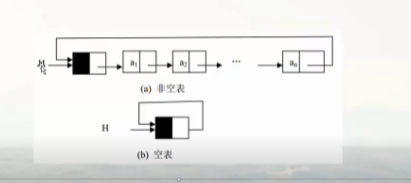
4.2 循环链表:
有些应用不需要链表中有明显的头尾节点.在这种情况下,可能需要方便地从最后一个节点访问到第一个节点。此时,最后一个结点的引用域不是空引用,二十保存第一个结点的地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号