
Nutch搜索引擎(第1期)_ Nutch简介及安装
1、Nutch简介
 Nutch是一个由Java实 现的,开放源代码(open-source)的web搜索引擎。主要用于收集网页数据,然后对其进行分析,建立索引,以提供相应的接口来对其网页数据进行 查询的一套工具。其底层使用了Hadoop来做分布式计算与存储,索引使用了Solr分布式索引框架来做,Solr是一个开源的全文索引框架,从 Nutch 1.3开始,其集成了这个索引架构。
Nutch是一个由Java实 现的,开放源代码(open-source)的web搜索引擎。主要用于收集网页数据,然后对其进行分析,建立索引,以提供相应的接口来对其网页数据进行 查询的一套工具。其底层使用了Hadoop来做分布式计算与存储,索引使用了Solr分布式索引框架来做,Solr是一个开源的全文索引框架,从 Nutch 1.3开始,其集成了这个索引架构。
Nutch目前最新的版本为version2.3。
1.1 Nutch的目标
Nutch 致力于让每个人能很容易,同时花费很少就可以配置世界一流的Web搜索引擎。为了完成这一宏伟的目标,Nutch必须能够做到:
-
每个月取几十亿网页
-
为这些网页维护一个索引
-
对索引文件进行每秒上千次的搜索
-
提供高质量的搜索结果
-
以最小的成本运作
1.2 Nutch的优点
-
透明度
Nutch是开放源代码的,因此任何人都可以查看他的排序算法是 如何工作的。商业的搜索引擎排序算法都是保密的,我们无法知道为什么搜索出来的排序结果是如何算出来的。更进一步,一些搜索引擎允许竞价排名,比如百度, 这样的索引结果并不是和站点内容相关的。因此Nutch对学术搜索和政府类站点的搜索来说,是个好选择。因为一个公平的排序结果是非常重要的。
-
扩展性
你是不是不喜欢其他的搜索引擎展现结果的方式呢?那就用 Nutch 写你自己的搜索引擎吧。 Nutch 是非常灵活的,他可以被很好的客户订制并集成到你的应用程序中。使用Nutch 的插件机制,Nutch 可以作为一个搜索不同信息载体的搜索平台。当然,最简单的就是集成Nutch到你的站点,为你的用户提供搜索服务。
-
对搜索引擎的理解
我们并没有google的源代码,因此学习搜索引擎Nutch是个不错的选择。了解一个大型分布式的搜索引擎如何工作是一件让人很受益的事情。 在写Nutch的过程中,从学院派和工业派借鉴了很多知识:比如:Nutch的核心部分目前已经被重新用 Map Reduce 实现了。Map Reduce 是一个分布式的处理模型,最先是从 Google 实验室提出来的。并且 Nutch 也吸引了很多研究者,他们非常乐于尝试新的搜索算法,因为对Nutch 来说,这是非常容易实现扩展的。
1.3 Nutch与Lucene关系
Lucene是一个Java高性能全文索引引擎工具包可以方便的嵌入到各种实际应用中实现全文索引搜索功能。它提供了一系列API,能够对文档进行预处理、过滤、分析、索引和检索排序。在保持高效和简单的特点之外,还保证了开发者可以自由定制和组合各种核心功能。Nutch是一个应用程序,是一个以Lucene为基础实现的搜索引擎应用,Lucene为Nutch 提供了文本搜索和索引的API,Nutch不仅提供搜索,而且还有数据抓取的功能。
简单的说:
-
Lucene 不是完整的应用程序,而是一个用于实现全文检索的软件库。
-
Nutch 是一个应用程序,可以以 Lucene 为基础实现搜索引擎应用。
一个常见的问题是:我应该使用Lucene还是Nutch?
最简单的回答是:如果你不需要抓取数据的话,应该使用Lucene。
常见的应用场合是:你有数据源,需要为这些数据提供一个搜索页面。在这种情况下,最好的方式是直接从数据库中取出数据并用Lucene API建立索引。
在你没有本地数据源,或者数据源非常分散的情况下,应该使用Nutch。
2、Nutch安装
我们现在进行的是Nutch的单机版安装以及配置。
2.1 环境介绍
本次安装Nutch的环境介绍:
-
操作系统:CentOS6.0(机器名:TSlave.Hadoop)
-
JDK版本:jdk-6u31-linux-i586.bin
-
Nutch版本:apache-nutch-1.4-bin.tar.gz
-
Tomcat版本:apache-tomcat-7.0.27.tar.gz
下面是软件的下载地址:
-
Nutch官网:http://nutch.apache.org/
-
Tomcat官网:http://tomcat.apache.org/
当所需软件准备好之后,我们用"FTPFlash"软件把上面上传到Linux服务器,为下面准备安装做好准备。

2.2 安装JDK
首先用root身份登录"TSlave.Hadoop:192.168.1.11"后在"/usr"下创建"java"文件夹,再把用FTP上传到"/home/hadoop/"下的"jdk-6u31-linux-i586.bin"复制到"/usr/java"文件夹中。
mkdir /usr/java
cp /home/hadoop/ jdk-6u31-linux-i586.bin /usr/java
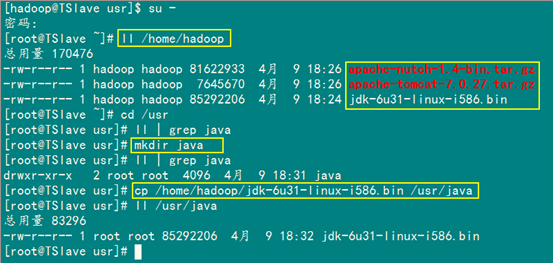
接着进入"/usr/java"目录下通过下面命令使其JDK获得可执行权限,并安装JDK。
chmod +x jdk-6u31-linux-i586.bin
./jdk-6u31-linux-i586.bin
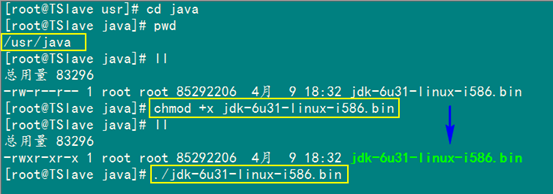
按照上面几步进行操作,最后点击"Enter"键开始安装,安装完会提示你按"Enter"键退出,然后查看"/usr/java"下面会发现多了一个名为"jdk1.6.0_31"文件夹,说明我们的JDK安装结束,删除"jdk-6u31-linux-i586.bin"文件,进入下一个"配置环境变量"环节。

接着配置JDK环境变量,编辑"/etc/profile"文件,在后面添加Java的"JAVA_HOME"、"CLASSPATH"以及"PATH"内容。在"/etc/profile"文件的尾部添加以下内容:
# set java environment
export JAVA_HOME=/usr/java/jdk1.6.0_31
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin

保存并退出,执行下面命令使其配置立即生效。
source /etc/profile

最后验证一下JDK是否安装成功。
java -version

2.3 安装Tomcat
首先进入"/home/hadoop"目录,把"apache-tomcat-7.0.27.tar.gz"复制到"/usr"下面,然后解压。
cp /home/hadoop /apache-tomcat-7.0.27.tar.gz /usr
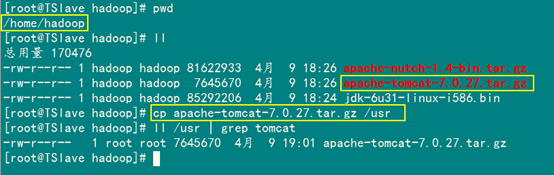
用下面命令进行解压Tomcat安装包。
tar –zxvf apache-tomcat-7.0.27.tar.gz
![]()
解压完之后,然后删除安装包,并对"apache-tomcat-7.0.27"重命名为"tomcat",把该文件夹授权于普通用户"hadoop"。
rm -rf apache-tomcat-7.0.27.tar.gz
mv apache-tomcat-7.0.27 tomcat
chown -R hadoop:hadoop tomcat
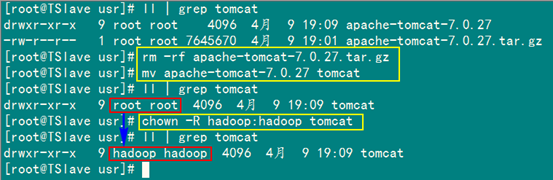
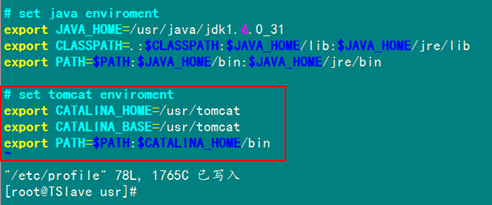
接着添加Tomcat环境变量,为了在以后系统启动后就配置好Tomcat所需的环境变量,要在"/etc/profile"文件中设置,并用"source /etc/profile"命令使其立即有效。
# set tomcat environment
export CATALINA_HOME=/usr/tomcat
export CATALINA_BASE=/usr/tomcat
export PATH=$PATH:$ CATALINA_HOME /bin
此时用"reboot"命名重启电脑,用普通"hadoop"登录Linux系统,执行下面命令启动我们刚才配置的Tomcat。
startup.sh
备注:别用root用户使用该命令,因为用最高用户启动Tomcat后,会在Tomcat的日志文件中生成相应的日志,但是日志的创建者是root,此时在转到普通用户启动Tomcat时,由于刚才创建的日志的用户是最高用户,其他用户无法对这些日志文件进行写,导致启动tomcat失败。还有记得把防火墙关掉。

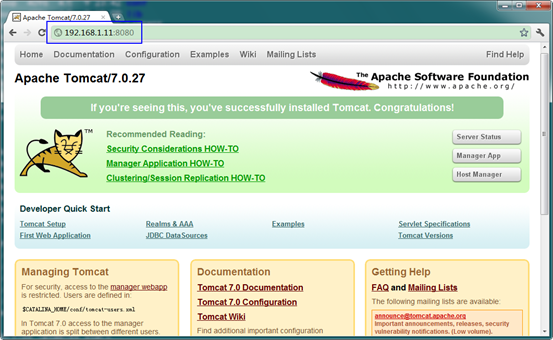
在浏览器输入"192.168.1.11 :8080",查看是否已经启动成功。
额外执行操作,如果端口发生冲突时,或者出现中文乱码时,修改"server.xml"配置文件,该文件位于"/usr/tomcat/conf"目录下面。
Apache http服务器的端口是 80,Apache Tomcat服务器端口是8080。二者不冲突,若有冲突,修改如下:
<!-- Define a non-SSL HTTP/1.1 Connector on port 8080 -->
<Connector port="8080" maxHttpHeaderSize="8192"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
c disableUploadTimeout="true"
URIEncoding="UTF-8" useBodyEncodingForURI="true" />
默认服务端口为8080,若有冲突(如Apache),则可通过此配置文件更改端口(蓝色);如果配置后nutch出现中文乱码问题,则增加编码配置(红色)。
2.4 安装Nutch
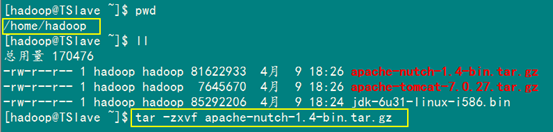
我们用普通用户"hadoop"把Nutch安装在"/home/hadoop"下面。用下面命令进行解压和重名。
tar -zxvf apache-nutch-1.4-bin.tar.gz
mv apache-nutch-1.4-bin nutch

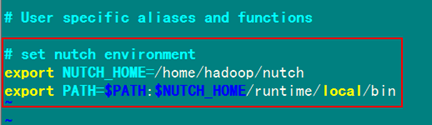
添加Nutch的环境变量,在"/home/hadoop/.bashrc"文件中添加如下内容。
# set nutch environment
export NUTCH_HOME=/home/hadoop/nutch
export PATH=$PATH:$ NUTCH _HOME /runtime/local/bin
添加完之后用"source .bashrc"使其立即生效。
然后在输入"nutch"命令测试是否配置成功,结果出现下面错误,当然这个错误网上说不一定出现。
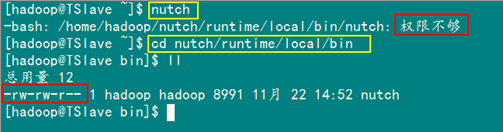
这时我们查看"/home/hadoop/nutch/runtime/local/nutch"这个文件时发现没有执行权限。用下面命令添加执行权限。
chmod +x nutch
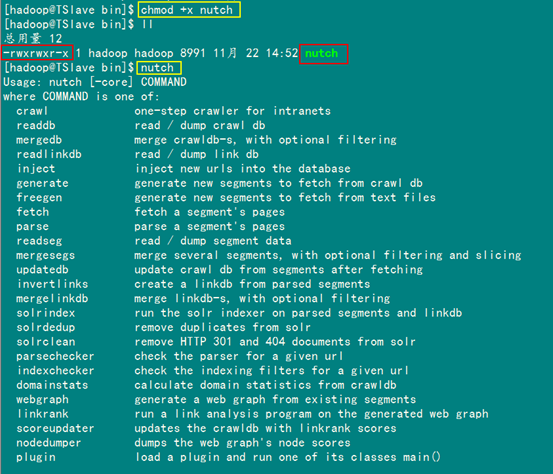
当给该文件添加执行权限后,我们再次查看,发现该文件的颜色发生了变化,再次执行"nutch"命令时,下面出现了该命名的参数列表。到此为止我们的单机版Nutch已经安装完毕。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号