
如何用协程扒光一部小说
郑重声明
以下代码是我跟着视频一个一个敲的,如有相同,只能说看的是一个视频,还有,过程完全是自己一个一个字打的,如有雷同,纯属巧合。
视频出处: https://www.bilibili.com/video/BV1uN4y1W7Du/?p=66&share_source=copy_web&vd_source=b743161248f2812166d8471922edab74
前言
本次爬取的小说对象是《西游记》,如标题所示,利用协程来完成,为何利用协程?
协程(Coroutine)是一种轻量级的程序执行单元,它可以在一个线程内实现多个任务的并发执行。
通过协程我可以更快的爬取小说的内容和下载小说的内容。相比于我之前所写的单线程来说,效率提高了n倍。虽然我所爬取的小说内容可能还不够大,但一旦你想要爬取的小说有几十本上百本并且一本小说有几千章那,这差别可就大了。
过程
1.先找一个心仪的网站,我所找的网站是百度小说: https://dushu.baidu.com
2.找到想要下载的书的页面后(《西游记》的地址:https://dushu.baidu.com/pc/detail?gid=4306063500 ),
接着有条不紊的点击鼠标右键,选择检查。
然后找到network,初次打开是没东西的,刷新一下就有东西了。
3.进入第一回,通过第一章页面上面的网址研究参数
看到这么一个玩意
https://dushu.baidu.com/pc/reader?gid=4306063500&cid=1569782244
后面多了cid这么一个参数并且前面也有一些变化,其中detail变成reader
然后尝试修改cid的值之后发现,cid每增加1,就进入下一回
与次同时查看network下的Fetch/XHR
一个个查看这些玩意,
找到其中一个的玩意里面包含了所有章节的cid以及标题,打开这个玩意的url:https://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"}
和想的一样,包含了所有的标题以及cid信息
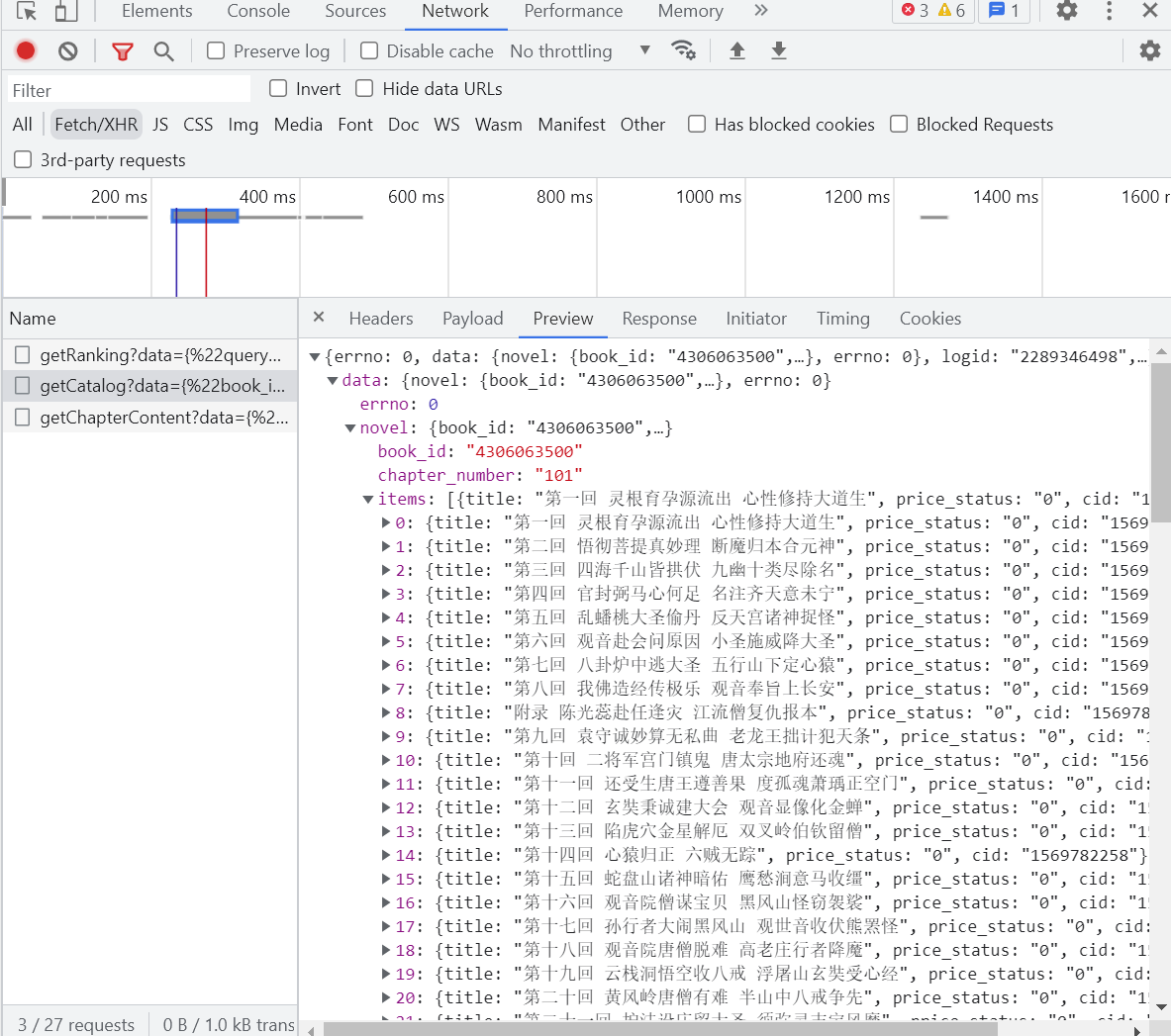
一般来说第一个玩意一般都挺有用的吧,既然这个页面已经是小说里面的内容,可以猜想,这第一个可能是第一回小说的内容,当然我所说的第一个玩意是指第一个生成出来的玩意,所以应该是最底下的内容,得到其url
https://dushu.baidu.com/api/pc/getChapterContent?data={"book_id":"4306063500","cid":"4306063500|1569782244","need_bookinfo":1}
打开一看,果然是第一回的内容,接下来和之前一样,分析参数的含义,第一个book_id显然是书本的id,从之前的url对比可以看出来,第二个cid,这次包含俩个数字,俩个都不难发现,第一个是book_id,第二个则是第一章的的cid,后面那玩意,目前也看不出什么门道。
接下来就是正式写代码了
python代码部分
"""西游记所有章节的id
https://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"}
西游记章节内部内容(这里以其中一章为例)
https://dushu.baidu.com/api/pc/getChapterContent?data={"book_id":"4306063500","cid":"4306063500|1569782245","need_bookinfo":0}
"""
引入的模块
import requests
import asyncio
import aiohttp
import aiofiles
import json
"""
1.异步操作:访问getCatalog 拿到所有的章节的cid和名称
2.同步操作:f访问getChapterContent 下载所有的文章内容
"""
aiodownload函数
async def aiodownload(cid,book_id,title):
data={
"book_id": f"{book_id}",
"cid": f"{book_id}|{cid}",
"need_bookinfo": 1,
}
data=json.dumps(data)
url=f"https://dushu.baidu.com/api/pc/getChapterContent?data={data}"
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
dic=await resp.json()
async with aiofiles.open(f"book/{title}",mode="w",encoding="utf-8") as f:
await f.write(dic['data']['novel']['content']) #把小说内容写出
# dic=['data']['novel']['content']
getCatalog函数
resp=requests.get(url)
dic=resp.json()
# print(dic)
tasks=[]
for item in dic['data']['novel']['items']:#item就是对应的每一个章节的名称和cid
title=item['title']
cid=item['cid']
print(cid,title)`
#准备异步任务
tasks.append(aiodownload(cid,book_id,title))
await asyncio.wait(tasks)
main函数
if __name__ == '__main__':
book_id="4306063500"
url='https://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"'+book_id+'"}'
asyncio.run(getCatalog(url))```
