
查询数据库中的重复数据——MySQL数据库
1、建表语句
DROP TABLE IF EXISTS `t_people`;
CREATE TABLE `t_people` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`people_no` varchar(18) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`people_name` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 11 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
2、插入数据
INSERT INTO `t_people` VALUES (1, '100', '张三');
INSERT INTO `t_people` VALUES (2, '100', '张三');
INSERT INTO `t_people` VALUES (3, '100', '张三');
INSERT INTO `t_people` VALUES (4, '101', '李四');
INSERT INTO `t_people` VALUES (5, '101', '李四');
INSERT INTO `t_people` VALUES (6, '102', '王五');
INSERT INTO `t_people` VALUES (7, '103', '赵六');
INSERT INTO `t_people` VALUES (8, '104', '田七');
INSERT INTO `t_people` VALUES (9, '100', '嘻嘻');
INSERT INTO `t_people` VALUES (10, '100', '小粉丝');
3、查询 people_no 重复的记录
SELECT *
FROM t_people
WHERE people_no IN (
SELECT people_no FROM t_people GROUP BY people_no HAVING COUNT(people_no) > 1
);

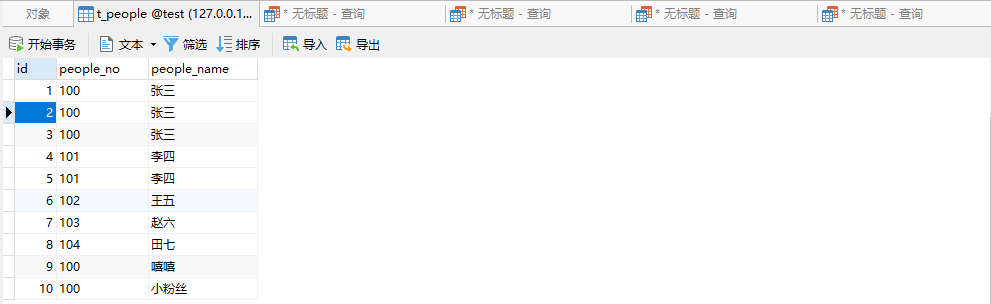
4、查询 people_no 重复且不包含 id 最小的记录
SELECT *
FROM t_people
WHERE people_no IN (
SELECT people_no FROM t_people GROUP BY people_no HAVING COUNT(people_no) > 1
) AND id NOT IN (
SELECT MIN(id) FROM t_people GROUP BY people_no HAVING COUNT(people_no) > 1
);
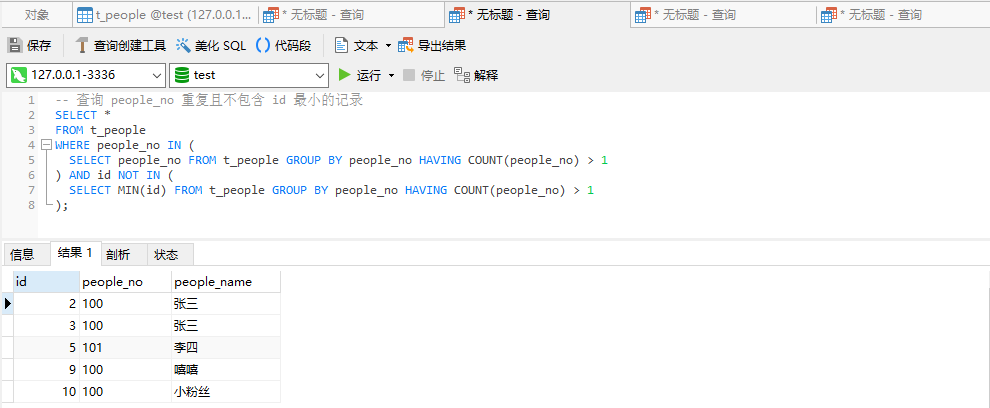
5、查询 people_no 和 people_name 重复的记录
SELECT *
FROM t_people
WHERE (people_no, people_name) IN (
SELECT people_no, people_name FROM t_people GROUP BY people_no, people_name HAVING COUNT(*) > 1
);
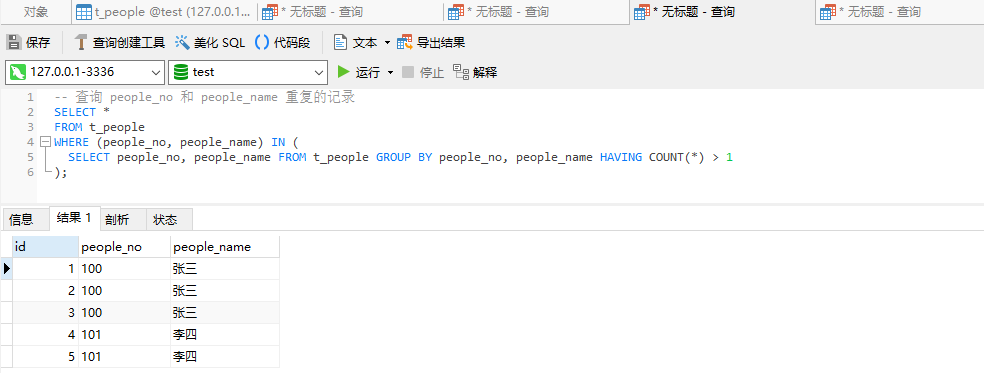
6、查询 people_no 和 people_name 重复且不包含 id 最小的记录
SELECT *
FROM t_people
WHERE (people_no, people_name) IN (
SELECT people_no, people_name FROM t_people GROUP BY people_no, people_name HAVING COUNT(*) > 1
) AND id NOT IN (
SELECT MIN(id) FROM t_people GROUP BY people_no, people_name HAVING COUNT(*) > 1
);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号