
摘要:
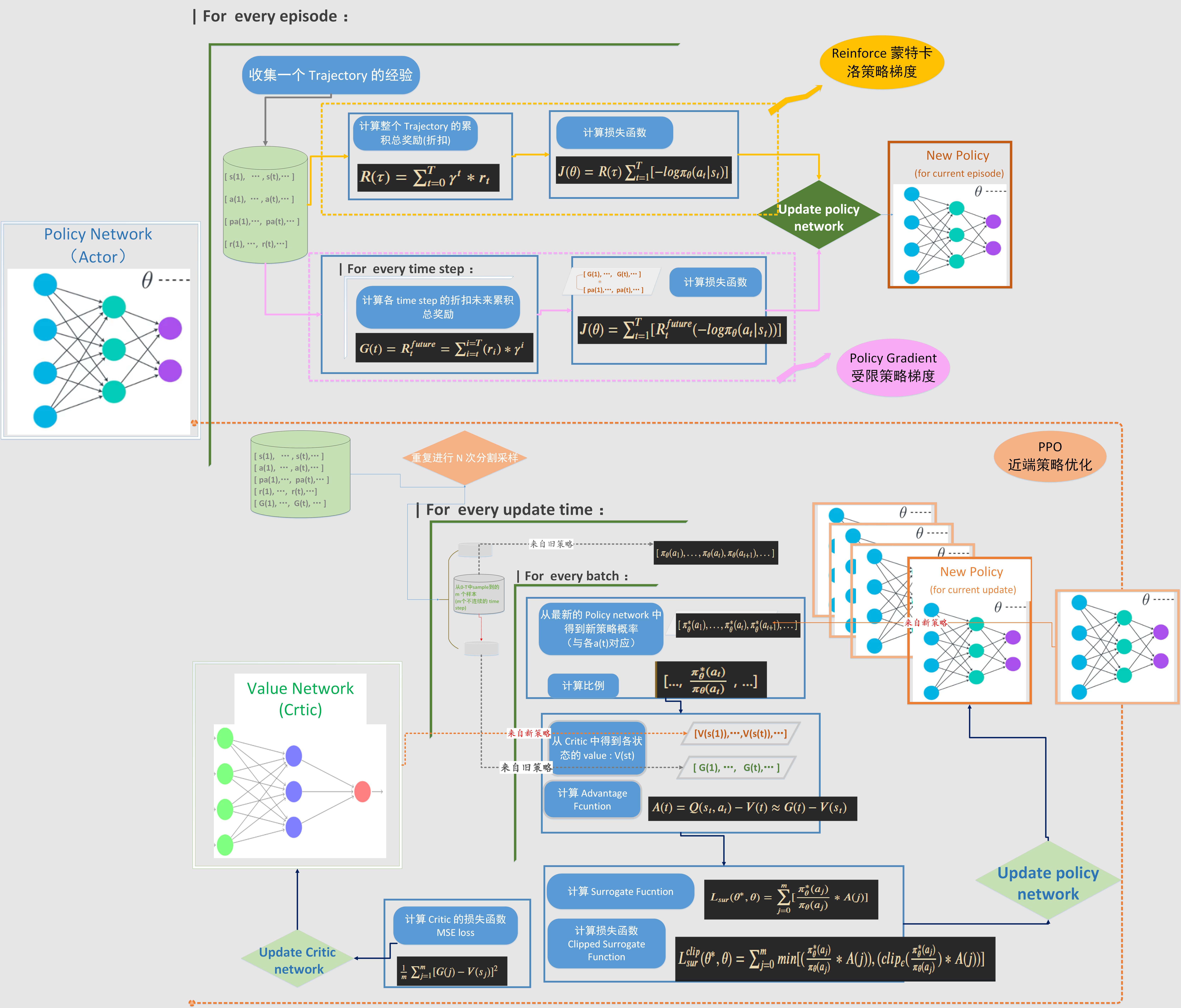 Policy Gradient 类的算法是通过梯度计算去更新策略网络的参数,因此目标函数就直接设计成期望累积奖励。这个期望值有多种表达方式,也就对应着不同的具体算法对损失函数的不同计算方法。这里总结的Policy Gradient 类的算法包括:Reinforce,受限策略梯度,PPO1 和 PPO2。对这几种算法的损失函数设计和流程做了归纳和对比。 阅读全文
Policy Gradient 类的算法是通过梯度计算去更新策略网络的参数,因此目标函数就直接设计成期望累积奖励。这个期望值有多种表达方式,也就对应着不同的具体算法对损失函数的不同计算方法。这里总结的Policy Gradient 类的算法包括:Reinforce,受限策略梯度,PPO1 和 PPO2。对这几种算法的损失函数设计和流程做了归纳和对比。 阅读全文
Policy Gradient 类的算法是通过梯度计算去更新策略网络的参数,因此目标函数就直接设计成期望累积奖励。这个期望值有多种表达方式,也就对应着不同的具体算法对损失函数的不同计算方法。这里总结的Policy Gradient 类的算法包括:Reinforce,受限策略梯度,PPO1 和 PPO2。对这几种算法的损失函数设计和流程做了归纳和对比。 阅读全文