
深度强化学习-策略梯度类算法梳理笔记
策略梯度 Policy Gradient 类下的算法详解
1. 核心设计:Policy Gradient 的损失函数
Policy Gradient 类的算法是通过梯度计算去更新策略网络的参数,因此目标函数就直接设计成期望累积奖励。这个期望值有多种表达方式,也就对应着不同的具体算法对损失函数的不同计算方法。
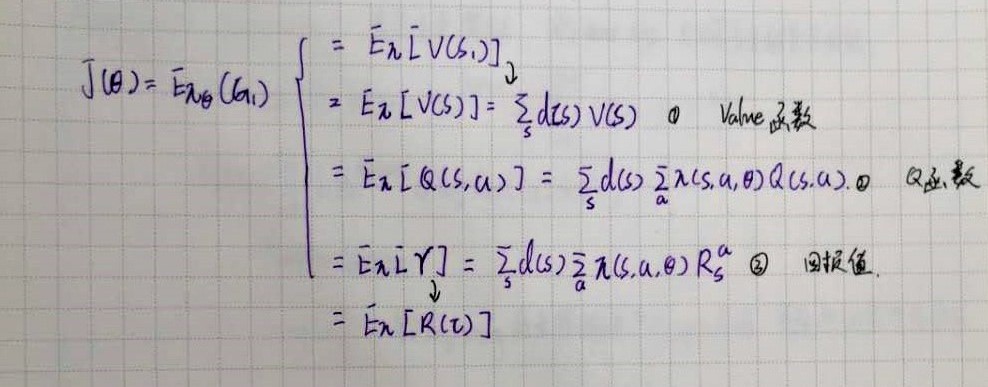
但因为累积奖励的期望值无法直接计算,需要采用蒙特卡洛方法,多次采样取近似的平均值。每次采样都会生成一个 Trajectory,在不断迭代运行,获取了大量的 Trajectory 后,使用一定的变换和近似去计算累积奖励,作为用于梯度更新的损失函数。
在进行梯度计算时,往往采用 log probablity 的形式,这更易于计算(在Pytorch等框架中也很容易实现)。相关近似计算的推到过程如下:

2. 算法种类和演化:从Reinforce 到 PPO
原始形式 — Reinforce
最早的 Policy Gradient 算法就是蒙特卡洛策略梯度(Reinforce),基本思想就是前面说的随机采样,然后用近似的平均累积奖励去代替期望值。
计算损失函数的时候把每个trajectory的累积奖励作为一个整体 \(R(\tau)=\sum_{t=0}^T \gamma^{t}*r_t\)
损失函数可以写成: \(J(\theta)=R(\tau) \sum_{t=1}^T [-log \pi_{\theta}(a_t|s_t)]\)
Credit Assigment
原始形式的损失函数计算了从 0-T 的所有累积奖励总和,但对于每个 time step , 当前采取的 action 只会对 >t 的时刻以后的状态产生影响,因此可以只计算未来的累积奖励,忽略过去的奖励。
对每个时间步 t,对应的未来累积奖励为: \(G(t)=R_t^{future}=\sum_{i=t}^{i=T} (r_i)* \gamma^i\)
则损失函数为 : \(J(\theta)=\sum_{t=1}^T [R_t^{future}(-log \pi_{\theta}(a_t|s_t))]\)
Importance Sampling
前面两种计算方法都相当于是均匀采样,即在计算期望时简单的取了平均,并没有考虑到每个 Trajectory 的采样概率不同。当引入采样概率时,目标函数就可以写成: \(\sum_\tau P(\tau;\theta) f(\tau)\)
其中 \(f(\tau)\) 为单个 Trajactory 的目标函数, \(f(\tau)=\sum_{t=1}^T [R_t^{future}(-log \pi_{\theta}(a_t|s_t))]\)
类似于 DDPG 中的 Memory Buffer,对旧的经验进行循环再利用。可以用以前的 old_policy 下采样得到的 trajectory ,更新当前的新 policy 参数。因此在目标函数中引入 reweighting factor:


上面的公式称为 Surrogate Function,基本思想是__利用新旧策略的比例__来计算目标函数。跟直接计算 log 概率的方式相比(比如 Reinforce),可以让更新的步子更平缓,避免梯度震荡等问题。
这也是更高级的算法,比如 PPO 计算损失函数的基础。但 Surrogate Function 存在一个问题,从前面的推到过程也能看出来,一个关键的近似计算是在__新旧策略相差不大__这个基础上进行的。但如果新旧策略差别较大,就会带来问题,为了考虑到这种情况,需要采取一些办法对策略更新的幅度进行限制,保证比例近似为1。这就引出了后面的 PPO。
PPO
- KL 散度

KL 散度衡量了两个分布之间的差异程度,用新旧策略各自对应分布之间的 KL 散度作为惩罚项,可以对 Surrogate Function 进行约束,限制策略更新的幅度。
$J(\theta) $ = $ L_{sur}(\theta',\theta) - \beta KL(\theta,\theta') $
但 KL 散度在实践中较难计算,所以又衍生出了第二种 PPO 的版本。
-
Clipped Surrogate function
当 Policy 函数在更新过程中出现突变,Surrogate Function 对于 reward 的估计就会不准确
The big problem is that at some point we hit a cliff, where the policy changes by a large amount. From the perspective of the surrogate function, the average reward is really great. But the actually average reward is really bad!
用简单的裁剪法代替 KL 散度,也可以起到很有效的限制更新幅度的作用。
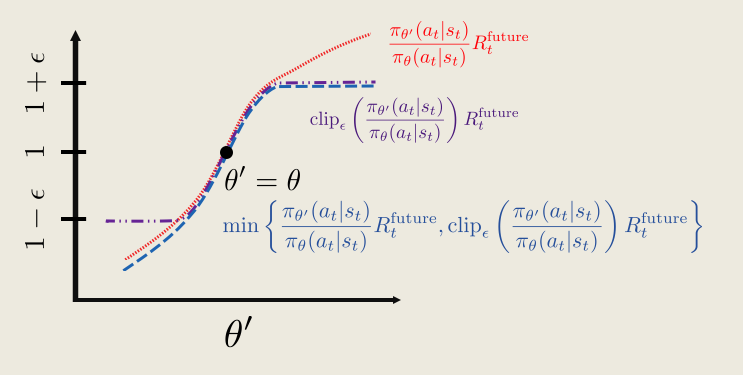
加入了 CLIP 裁剪后,Surrogate function 就可以写为:
\(L^{clip}_{sur}(\theta^*,\theta)=\sum^m_{j=0} min [( \frac{\pi_{\theta}^*(a_j)}{\pi_{\theta}(a_j)}*A(j)),(clip_{\epsilon}(\frac{\pi_{\theta}^*(a_j)}{\pi_{\theta}(a_j)})*A(j))]\)
这也就是第二种 PPO 算法的损失函数计算式,也是更常用的一种。
3. 三种主要策略梯度类算法的流程对比
这里对三种常用的 Policy Gradient 类算法的流程进行了总结和对比。
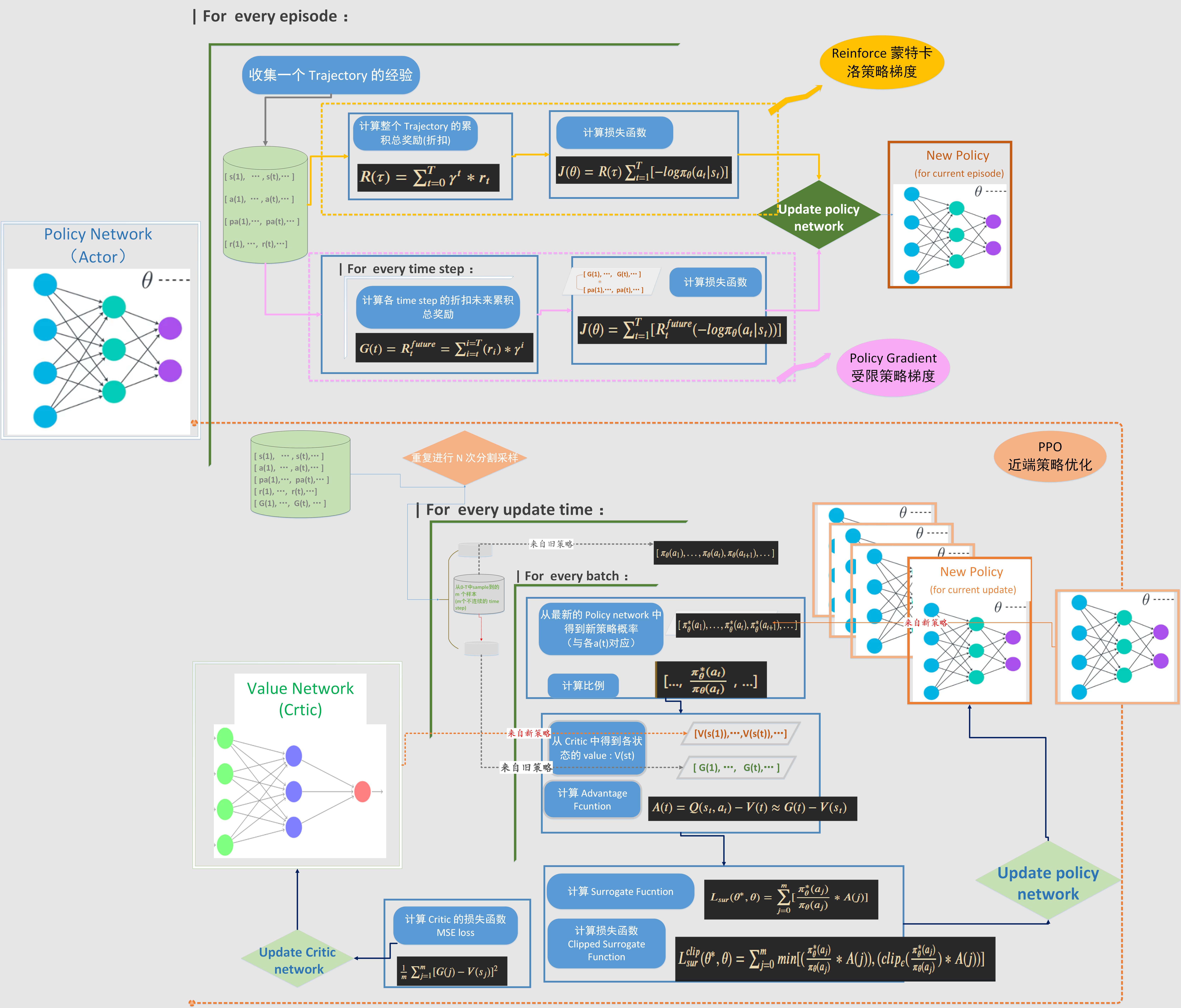
Reinforce 比较简单,受限策略梯度是在 Reinforce 的基础上对损失函数进行了改进。这两种都是每次采样完一整个 Trajectory 的数据后,再进行策略更新,属于 on policy 的更新方式。
而 PPO 则不同于前面两种,采用的是 off policy 离线策略更新。每次重复进行 N 个 Trajectory 的连续采样,然后把这些数据存入 memory buffer,更新的时候把多个 Trajectory 的样本打乱,按照 mini-batch 取用,然后进行多次迭代更新。而每次更新,策略参数就是改变,计算最新策略和旧策略(采样时的行动策略)的概率之比。而这时用于更新的策略和用于行动的策略就不是同一个了,对于一个固定的采样批次,行动策略是保持不变的,而更新的策略则在不停变化。因此是典型的离线策略更新。
如果用 Advantage 去计算损失函数,那么还需要一个 Critic 网络生成 value function , 这时 PPO 的结构就类似于 Actor-Critic,但是 Critic 输出的是 V 而不是 Q,更新相对简单。
近端策略优化算法 PPO
PPO 伪代码

4. 算法关键点
-
优势函数:Actor-Critic结构 ,Advantage 的计算
- 直接用 \(A=G-V\)
- 使用 GAE 方法计算 ✳
-
Clipped Surrogate function ,off policy 离线策略更新
- 加入 entropy 项作为对 new policy 的限制 ✳
-
policy 更新的问题
- 更新的时机:跑完一个episode再更新,还是收集固定数量的 exp 就可以更新
- 更新的频率,更新前后两个 \(\theta\) 的差异程度,对梯度计算的影响
- 是否引入梯度剪裁 clip_grad_norm_
- Policy Loss 的最终形式 ✳
-
Critic 网络更新的问题
- 损失函数计算:\(L_c = MSE(G-V)\)
- Critic 与 Actor 同步更新,对自身损失函数的影响,是否会导致梯度不稳定
-
Actor 和 Critic 网络结构和超参数配置对学习的影响
5. PPO 在连续控制场景中的应用关键点(contiounus action space)
-
由于 PPO 属于随机策略 stochastic policy,网络不能直接输出连续动作的取值(与DDPG不同),而是需要输出action 的概率分布
-
policy 网络包含两个输出层,分别对应着动作概率分布的均值 和方差 ,每个输出层的维度与 action 的维度一致
-
action 的生成需要从动作概率分布中采样,既先把当前 state 输入 policy 网络,得到动作概率分布,再从中采样得到随机动作值
def act(self,state): state = torch.from_numpy(state).float().unsqueeze(0).to(device) with torch.no_grad(): (mu, sigma) = self.policy(state) # 2d tensors dist = Normal(mu, sigma) action = dist.sample() action_log_prob = dist.log_prob(action) return action.numpy()[0], action_log_prob.numpy()[0] -
Surrogate function 中 ratio 的计算 ✳
(mus, sigmas) = self.policy(states) dists = Normal(mus, sigmas) new_probs=dists.log_prob(actions) ratios = torch.exp(new_probs - old_probs) -
引入 entropy 项

 浙公网安备 33010602011771号
浙公网安备 33010602011771号