
摘要:
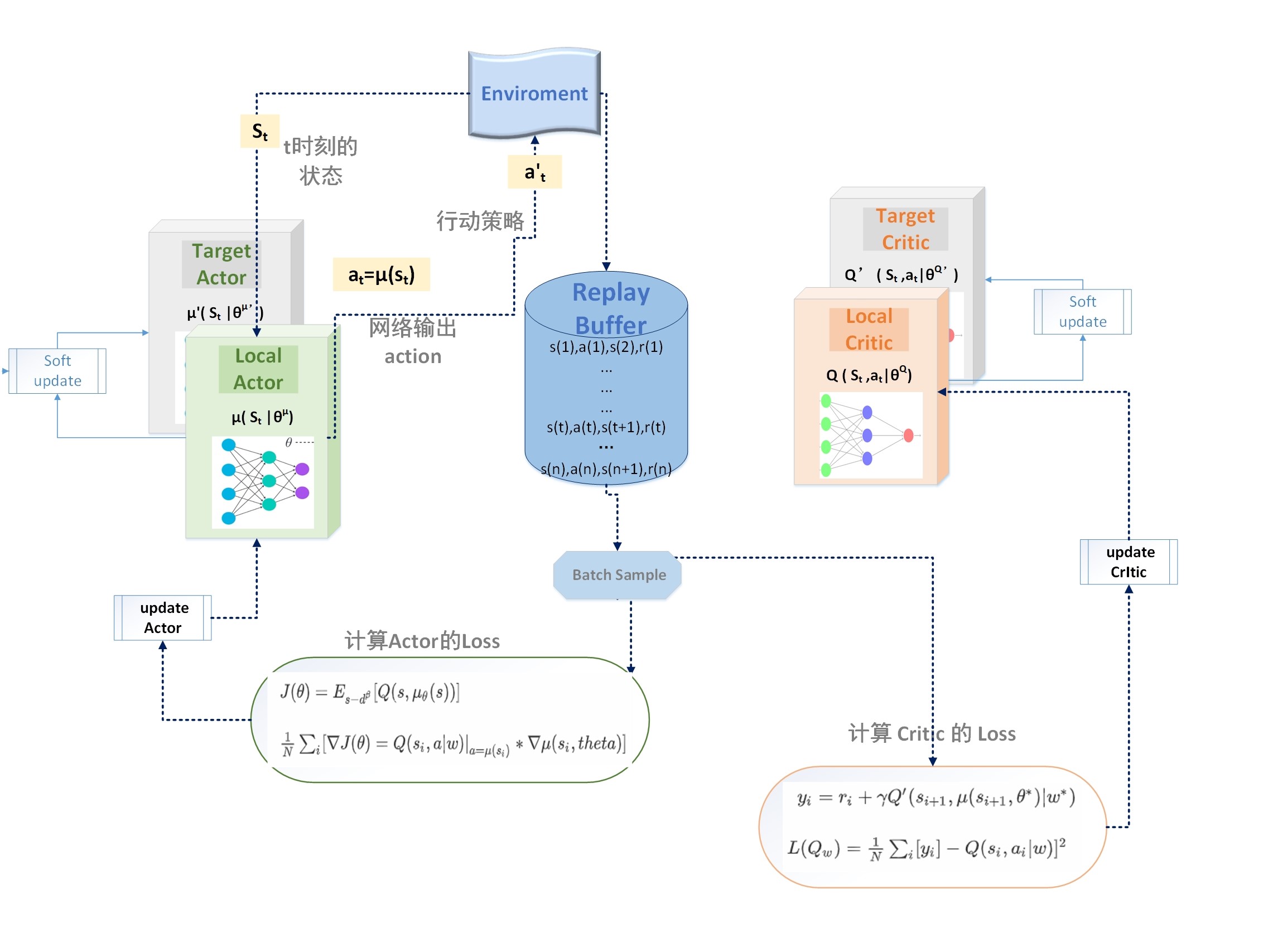 确定性策略梯度算法属于 Actor-Critic 类,综合了 value based 方法和 policy based 方法的优点,在很多任务上的表现能吊打 PG 类算法,比如 gym 的经典难题 BipedalWalker 项目。这里介绍的有两种: DDPG 和它的升级版:TD3,后续还会加入 D4PG 等更多变体的介绍。 阅读全文
确定性策略梯度算法属于 Actor-Critic 类,综合了 value based 方法和 policy based 方法的优点,在很多任务上的表现能吊打 PG 类算法,比如 gym 的经典难题 BipedalWalker 项目。这里介绍的有两种: DDPG 和它的升级版:TD3,后续还会加入 D4PG 等更多变体的介绍。 阅读全文
确定性策略梯度算法属于 Actor-Critic 类,综合了 value based 方法和 policy based 方法的优点,在很多任务上的表现能吊打 PG 类算法,比如 gym 的经典难题 BipedalWalker 项目。这里介绍的有两种: DDPG 和它的升级版:TD3,后续还会加入 D4PG 等更多变体的介绍。 阅读全文
posted @ 2020-05-21 16:18
Quantum-Cheese
阅读(531)
评论(0)
推荐(0)
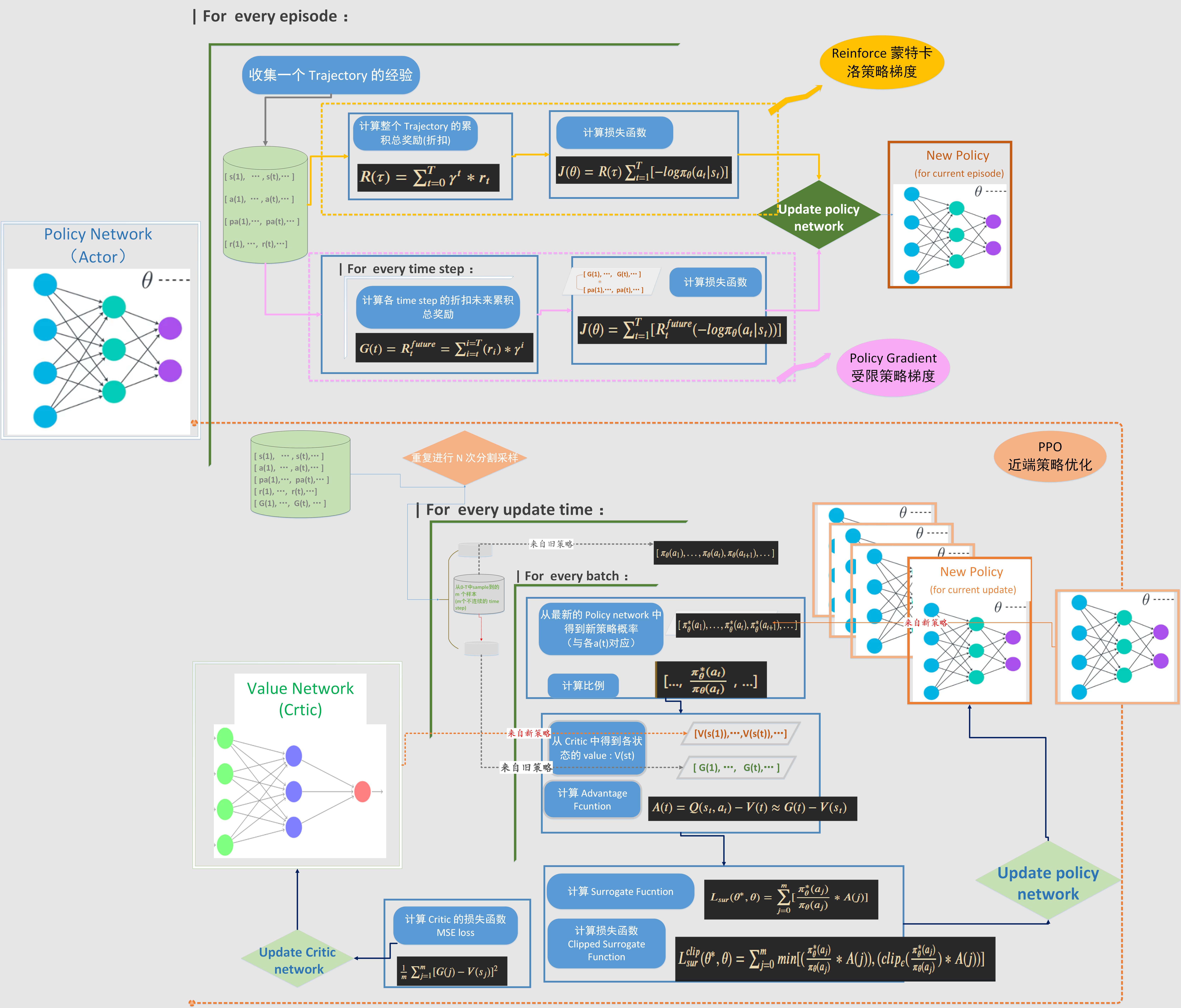 Policy Gradient 类的算法是通过梯度计算去更新策略网络的参数,因此目标函数就直接设计成期望累积奖励。这个期望值有多种表达方式,也就对应着不同的具体算法对损失函数的不同计算方法。这里总结的Policy Gradient 类的算法包括:Reinforce,受限策略梯度,PPO1 和 PPO2。对这几种算法的损失函数设计和流程做了归纳和对比。
Policy Gradient 类的算法是通过梯度计算去更新策略网络的参数,因此目标函数就直接设计成期望累积奖励。这个期望值有多种表达方式,也就对应着不同的具体算法对损失函数的不同计算方法。这里总结的Policy Gradient 类的算法包括:Reinforce,受限策略梯度,PPO1 和 PPO2。对这几种算法的损失函数设计和流程做了归纳和对比。  浙公网安备 33010602011771号
浙公网安备 33010602011771号