
【学习】java基础整理(三)
传送门
101. 你是如何调用 wait()方法的?使用 if 块还是循环?为什么?
如果是需要先判断条件再使用wait()方法的情况下,应该使用循环调用wait()方法。
原因是:线程使用wait放弃锁后,线程会停在wait方法的位置,等到被notify唤醒,并重新获得锁,线程会继续执行wait方法后面的操作。如果使用if语句块,线程重新获取锁并执行完if块中的语句后,不会再判断一次if条件,而是直接执行if外的语句,从而引起错误的执行流程。
102. 什么是线程局部变量?
线程局部变量是局限于线程内部的变量,属于线程自身所有,不在多个线程间共享。Java 提供 ThreadLocal 类来支持线程局部变量,是一种实现线程安全的方式。但是在管理环境下(如 web 服务器)使用线程局部变量的时候要特别小心,在这种情况下,工作线程的生命周期比任何应用变量的生命周期都要长。任何线程局部变量一旦在工作完成后没有释放,Java 应用就存在内存泄露的风险。
103. Java 中 sleep 方法和 wait 方法的区别?
虽然两者都是用来暂停当前运行的线程,但是 sleep() 实际上只是短暂停顿,因为它不会释放锁,而 wait() 意味着条件等待,这就是为什么该方法要释放锁,因为只有这样,其他等待的线程才能在满足条件时获取到该锁。
104. 什么是不可变对象(immutable object)?Java 中怎么创建一个不可变对象?
不可变对象指对象一旦被创建,状态就不能再改变。任何修改都会创建一个新的对象,如 String、Integer 及其它包装类。
105. 我们能创建一个包含可变对象的不可变对象吗?
是的,可以创建一个包含可变对象的不可变对象的,你只需要谨慎一点,不要共享可变对象的引用就可以了,如果需要变化时,就返回原对象的一个拷贝。
final Person[] persons = new Persion[]{}
// 此时persons是不可变对象,但是数组中存放的每一个元素都是可变的Person实例
106. Java 中应该使用什么数据类型来代表价格?
如果不是特别关心内存和性能的话,使用 BigDecimal,否则使用预定义精度的double 类。
double PI = 3.14159265358979323;
double area = PI*r*r;
DecimalFormat df = new DecimalFormat("#0.0000000");//精度定义,小数点后几个0,表示保留几位小数
System.out.print(df.format(area));
BigDecimal不推荐使用BigDecimal(double)因为同样会有精度问题,推荐用BigDecimal(String)。
107. 怎么将 byte 转换为 String?
可以使用 String 接收 byte[] 参数的构造器来进行转换,需要注意的点是要使用的正确的编码,否则会使用平台默认编码,这个编码可能跟原来的编码相同,也可能不同。
// 这里编码不写则为平台默认编码,如果出现乱码则自定义编码
String str = new String(InputByte, "UTF-8")
108. 我们能将 int 强制转换为 byte 类型的变量吗?如果该值大于 byte 类型的范围,将会出现什么现象?
可以,但是 Java 中 int 是 32 位的,而 byte 是 8 位的,所以,如果强制转化,int 类型的高 24 位将会被丢弃,byte 类型的范围是从 -128 到 128。
109. 存在两个类,B 继承 A,C 继承 B,我们能将 B 转换为C 么?如 C = (C) B;
//C 继承 B, B 继承 A
C c = new C();
B b = c; // 可以,因为是C一定是B
B b = new B();
C c = (C)b; // 不可以,是B不一定是C
B b = new C(); // 已经声明了一个C类型的B
C c = (C)b; // 可以,因为声明的就是C类型
A a = new C();
a 是 B类型吗 // 是的,a声明时得到了一个特殊的B -> C
110. 哪个类包含 clone 方法?是 Cloneable 还是 Object?
java.lang.Cloneable 是一个标示性接口,不包含任何方法,clone 方法在object 类中定义。并且需要知道 clone() 方法是一个本地方法,这意味着它是由c 或 c++ 或其他本地语言(win环境在dll中)实现的。
111. Java 中 ++ 操作符是线程安全的吗?
不是。它涉及到多个指令,如读取变量值,增加,然后存储回内存,这个过程可能会出现多个线程交差。
112. a = a + b 与 a += b 的区别
在变量a,b数据类型相同时,或是数据类型不同时但a的类型精度高于b时,结果是一样的。
a=a+b,在运算中会将等号右侧的低精度类型向高精度类型转换,然后再相加赋值给等号左侧。如果右侧精度高于左侧,则会报错,此时需要进行强制转换a=(高精度)a+b。
a+=b,因为+=运算符会自动类型转换(+=会先将右侧操作数类型转换为左侧操作数类型,再相加赋值),不会出现上面的情况。
113. 能在不进行强制转换的情况下将一个 double 值赋值给long 类型的变量吗?
不能,因为 double 类型的范围比 long 类型更广,所以必须要进行强制转换。
114. 3*0.1 == 0.3 将会返回什么?true 还是 false?
false,因为有些浮点数不能完全精确的表示出来。
115. int 和 Integer 哪个会占用更多的内存?
Integer 对象会占用更多的内存。Integer 是一个对象,需要存储对象的元数据。但是 int 是一个原始类型的数据,所以占用的空间更少。
116. 为什么 Java 中的 String 是不可变(Immutable)?
- 只有当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约堆中的空间,因为不同的字符串变量都指向池中的同一个字符串。
- 如果字符串是可变的,那么会引起很严重的安全问题。譬如,数据库的用户名、密码都是以字符串的形式传入来获得数据库的连接,或者在socket编程中,主机名和端口都是以字符串的形式传入。因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变字符串指向的对象的值,造成安全漏洞。
- 因为字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。
- 类加载器要用到字符串,不可变性提供了安全性,以便正确的类被加载。譬如你想加载java.sql.Connection类,而这个值被改成了myhacked.Connection,那么会对你的数据库造成不可知的破坏。
- 因为字符串是不可变的,所以在它创建的时候hashcode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
117. Java 中的构造器链是什么?
当你从一个构造器中调用另一个构造器,就是 Java 中的构造器链。这种情况只在重载了类的构造器的时候才会出现。
118. 64 位 JVM 中,int 的长度是多少?
Java 中,int 类型变量的长度是一个固定值,与平台无关,都是 32 位。意思就是说,在 32 位 和 64 位 的 Java 虚拟机中,int 类型的长度是相同的。
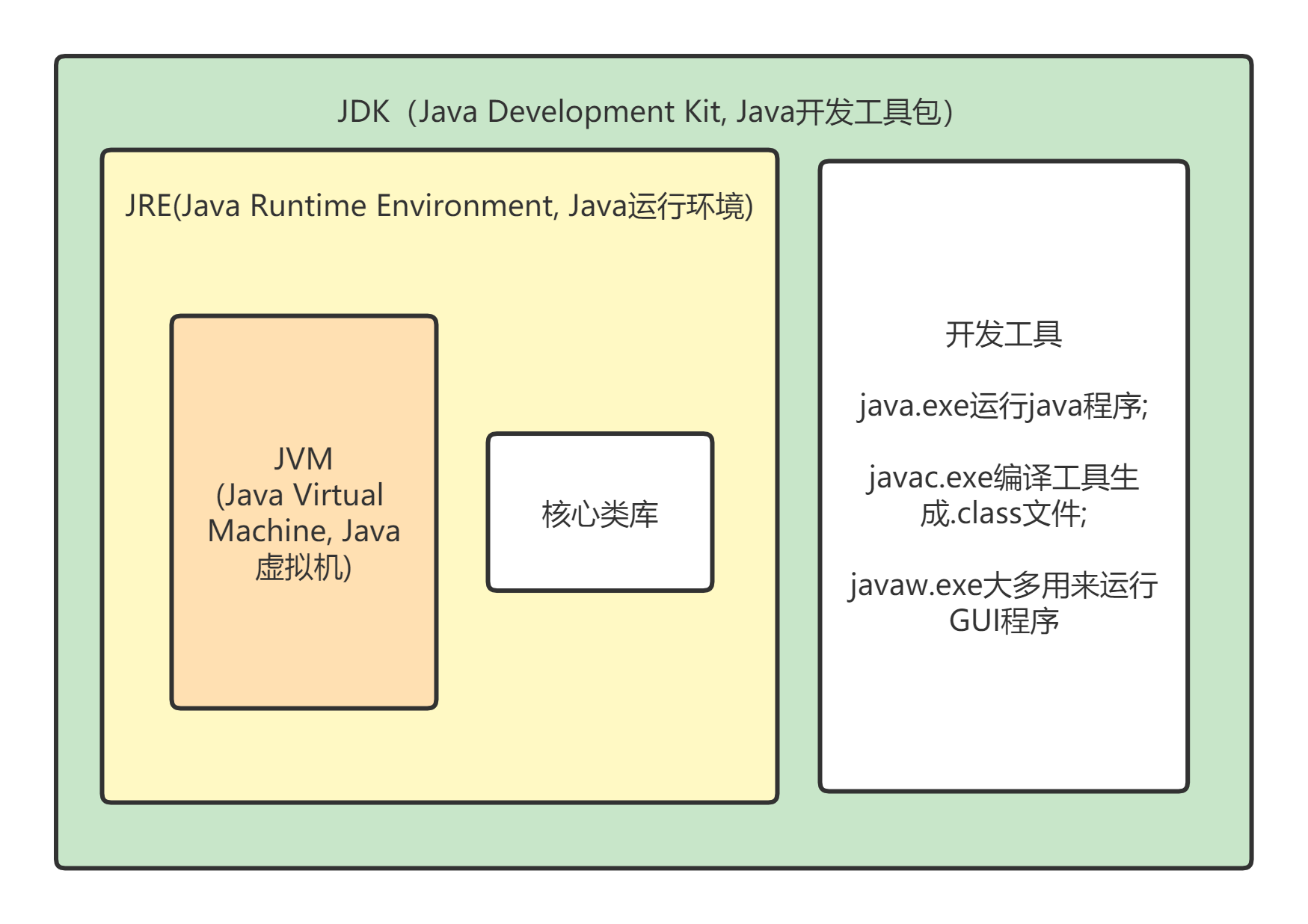
119. JRE、JDK、JVM 及 JIT 之间有什么不同?
- JRE 代表 Java 运行环境(Java Runtime Environment),包含JVM标准实现及Java核心类库;
- JDK 代表 Java 软件开发工具包(Java development kit),包含了jre、一堆Java工具和Java基础的类库;
- JVM 代表 Java 虚拟机(Java virtual machine),它的责任是运行 Java 应用;
- JIT 代表即时编译(Just In Time compilation),当代码执行的次数超过一定的阈值时,会将 Java 字节码转换为本地代码,如,主要的热点代码会被准换为本地代码,这样有利大幅度提高 Java 应用的性能。
120, 解释 Java 堆空间及 GC?
当通过 Java 命令启动 Java 进程的时候,会为它分配内存。内存的一部分用于创建堆空间,当程序中创建对象的时候,就从堆空间中分配内存。
GC 是 JVM 内部的一个进程,回收无效对象的内存用于将来的分配
121. poll() 方法和 remove() 方法的区别?
poll() 和 remove() 都是从队列中取出一个元素,但是 poll() 在获取元素失败的时候会返回空,但是 remove() 失败的时候会抛出异常。
122. Java 中怎么打印数组?
可以使用 Arrays.toString() 和 Arrays.deepToString() 方法来打印数组。由于数组没有实现 toString() 方法,所以如果将数组传递给 System.out.println()方法,将无法打印出数组的内容,但是 Arrays.toString() 可以打印每个元素。
123. Java 中的 LinkedList 是单向链表还是双向链表?
是双向链表。
124. Hashtable 与 HashMap 有什么不同之处
- Hashtable 是 JDK 1 遗留下来的类,而 HashMap 是后来增加的;
- Hashtable 是同步的,比较慢,但 HashMap 没有同步策略,所以会更快;
- Hashtable 不允许有个空的 key,但是 HashMap 允许出现一个 null key。
125. 写一段代码在遍历 ArrayList 时移除一个元素?
// 错误代码
// 移除i后,下次遍历的实际上是i+2元素,跳过了一个元素
for (int i = 0; i < list.size(); i++){
if (list.get(i).equals("3"))
list.remove(i);
}
// 错误代码
// 因为元素在使用的时候发生了并发的修改,会产生ConcurrentModificationException
for (String s : list) {
if (s.equals("3"))
list.remove(s);
}
// 正确做法
// 使用迭代器remove
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
String s = iterator.next();
if (s.equals("3"))
iterator.remove();
}
126. ArrayList 和 HashMap 的默认大小是多少?
在 Java 7 中,ArrayList 的默认大小是 10 个元素,HashMap 的默认大小是16 个元素(必须是 2 的幂)。
127. 有多个 socket时,需要多少个线程来处理?
- 当socket连接数量不是很多时,可以通过accept监听端口,每有一个socket请求就建立一个线程;
- 当数量很多时就需要线程池管理线程了。
128. TCP 协议与 UDP 协议有什么区别
- TCP:传输控制协议(Transmission Control Protocol)
- Tcp是面向连接的运输层协议,这就是说,应用程序在使用TCP提供的服务传送数据之前,必须先建立TCP连接。建立连接的目的是通信双方为接下来的数据传输传做好准备,初始化各种状态变量,分配资源等等,在传输数据完毕后,必须释放以建立的TCP连接,即释放变量和资源。这个过程与打电话类似:通话前先拨号建立连接,通话结束后要释放连接
- UDP:用户数据报协议(User Datagram Protocol)
- UDP只是在IP协议服务的基础上,添加了端口的功能。有了端口,运输层就可以进行复用和分用和差错检测的功能
- 区别:
- 最大的区别就是TCP是面向连接的,而UDP是无连接的
- TCP是可靠的,安全的;UDP是不可靠的,不安全的,但是传输数据的速率快
- TCP比UDP更复杂,它具有流量控制和拥塞控制机制
- TCP面向字节流;UDP是面向报文的
- TCP对系统资源要求较多,UDP对系统资源要求较少。TCP首部有20个字节,UDP的首部只有8个字节的首部开销。
- TCP连接只能是一对一的;而UDP支持一对一,一对多和多对多的交互通信
- UDP协议不使用确认信息对报文的到达进行确认,它不能保证报文到达的顺序,也不能向源端反馈信息来进行流量控制,因而会出现报文丢失等现象。
- TCP肯定将数据传送出去,并且在目的主机上的应用程序能以正确的顺序接收数据。
129. 接口是什么?为什么要使用接口而不是直接使用具体类
接口是一个类中方法的特征集合,是一种逻辑上的抽象。
- 简单、规范性:如果一个项目比较庞大,那么就需要一个能理清所有业务的架构师来定义一些主要的接口,这些接口不仅告诉开发人员你需要实现那些业务,而且也将命名规范限制住了(防止一些开发人员随便命名导致别的程序员无法看明白)。
- 维护、拓展性:比如你要做一个画板程序,其中里面有一个面板类,主要负责绘画功能,然后你就这样定义了这个类,可是在不久将来,你突然发现这个类满足不了你了,然后你又要重新设计这个类,更糟糕是你可能要放弃这个类,那么其他地方可能有引用他,这样修改起来很麻烦,如果你一开始定义一个接口,把绘制功能放在接口里,然后定义类时实现这个接口,然后你只要用这个接口去引用实现它的类就行了,以后要换的话只不过是引用另一个类而已,这样就达到维护、拓展的方便性。
- 安全、严密性:接口是实现软件松耦合的重要手段,它描叙了系统对外的所有服务,而不涉及任何具体的实现细节。这样就比较安全、严密一些(一般软件服务商考虑的比较多)。
130. 什么是“依赖注入”和“控制反转”?为什么有人使用?
控制反转(IOC,Inversion of Control):是一种设计模式设计思想,原本在程序中需要手动创建对象的控制权,在使用Spring后,将这个控制权交给Spring框架来管理。由Spring来负责控制对象的生命周期(创建、销毁)和对象间的依赖关系。
IOC由专门的容器(bean工厂)创建对象,将所有的类都放在容器中,当需要某个对象的时候,不再需要手动new,只需要告诉容器,然后容器就会把对应的对象返回回来。
好处:传统的应用程序都是在类的内部手动创建依赖对象,从而导致类与类之间高度耦合。有了IOC容器之后,创建和查找依赖对象的控制权交给了容器,对象与对象之间是松散耦合,有利于功能复用,使得体系结构更加灵活。
举例:一个service接口可能依赖了很多其他接口,如果采用手动new依赖对象的话,需要搞清楚所有依赖对象的构造方法。而通过bean工厂,只需要在对应类上添加注解(@Controller,@Service,@Resource等),告诉bean工厂该类交给工厂管理,然后在其他地方使用时直接从工厂中取对象即可。
依赖注入:实现控制反转的方式。在需要的类上添加注解(@Controller,@Service,@Resource等),就能将类注入到bean工厂当中,如果没有声明value,则类名作为检索的名称。
131. 依赖注入的几种方式
- 构造注入:将被依赖对象通过构造函数的参数注入给依赖对象,并且在初始化对象的时候注入。
- 优点:对象初始化完成后便可获得可使用的对象。
- 缺点:当需要注入的对象很多时,构造器参数列表将会很长,不够灵活。
// 构造注入
public class Demo{
private String name;
private int age;
//此处省略setter和getter
public Demo(String name,int age){
this.name = name;
this.age=age;
}
}
// 构造器配置-代码:
<bean id="test" class="com.ssm.pojo.Demo">
<constructor-arg index="0" value="张三" />
<constructor-arg index="1" value="20" />
</bean>
- setter注入:通过调用成员变量提供的 setter 方法将被依赖对象注入给依赖类。
- 优点:灵活,可以选择性地注入需要的对象。
- 缺点:依赖对象初始化完成后由于尚未注入被依赖对象,因此还不能使用。
<bean id="test2" class="com.ssm.pojp.Demo">
<property name="name" vlaue="李四" />
<property name="age" value="30" />
</bean>
- 接口注入:主要应用于资源来自于非自身系统,而是来自外界,如jdbc配置。
- 优点:接口注入中,接口的名字、函数的名字都不重要,只要保证函数的参数是要注入的对象类型即可。
- 缺点:侵入性强。为了使用外部接口,自身类中需要增加额外的代码。
<Context>
<Resource name="jdbc/ssm"
auth="Container"
type="javax.sql.DateSource"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysel://localhost:3306/xxx?zeroDateTimeBehavior=xxx"
username="root"
password:"123"
/>
</Context>
// 通过JNDI获取数据库连接资源-代码:
<bean id="dateSource" class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiName">
<value>java:comp/env/jdbc/ssm</value>
</property>
</bean>
132. 适配器模式和装饰器模式有什么区别?
虽然适配器模式和装饰器模式的结构类似,但是每种模式的出现意图不同。适配器模式被用于桥接两个接口,而装饰模式的目的是在不修改类的情况下给类增加新的功能。
133 适配器模式和代理模式有什么不同?
由于适配器模式和代理模式都是封装真正执行动作的类,因此结构是一致的,但是适配器模式用于接口之间的转换,而代理模式则是增加一个额外的中间层,以便支持分配、控制或智能访问。
134. Java 中,throw 和 throws 有什么区别
- throw 在方法体内使用(catch),throws 在方法声明上使用(方法后,如public getName() throws xxx);
- throw 后面接的是异常对象,只能接一个。throws 后面接的是异常类型,可以接多个,多个异常类型用逗号隔开;
- throw 是在方法中出现不正确情况时,手动来抛出异常,结束方法的,执行了 throw 语句一定会出现异常。而 throws 是用来声明当前方法有可能会出现某种异常的,如果出现了相应的异常,将由调用者来处理,声明了异常不一定会出现异常。
135. Java 中,Serializable 与 Externalizable 的区别?
都是序列化接口。
Serializable 是 JVM 内嵌的默认序列化方式,成本高、脆弱而且不安全。Externalizable 允许控制整个序列化过程,允许指定属性进行序列化。
136. 线程池参数都有哪些
- corePoolSize:核心线程数
- maximumPoolSize:最大线程数
- keepAliveTime:空闲线程存活时间
- unit:时间单位
- workQueue:线程池任务队列
- threadFactory:创建线程的工厂
- handler:拒绝策略
137. 什么是字节码?采用字节码的大好处是什么
- 字节码:Java源代码经过虚拟机编译器编译后产生的文件(即扩展为.class的文件),它不面向任何特定的处理器,只面向jvm虚拟机。
采用字节码的好处:
Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行时比较高效, 而且,由于字节码并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。
java中的编译器和解释器:
Java中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟机器。这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口。编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在Java中,这种供虚拟机理解的代码叫做字节 码(即扩展为.class的文件),它不面向任何特定的处理器,只面向虚拟机。每 一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java源程序经过编译 器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行,这就是上面提到的Java的特点的编译与解释并存的解释.
Java源代码---->编译器---->jvm可执行的Java字节码(即虚拟指令)---->jvm---->jvm中 解释器----->机器可执行的二进制机器码---->程序运行。
138. Java和C++的区别
- 都是面向对象的语言,都支持封装、继承和多态
- Java不提供指针来直接访问内存,程序内存更加安全
- Java的类是单继承的,C++支持多重继承;虽然Java的类不可以多继承,但是接口可以多继承。
- Java有自动内存管理机制,不需要程序员手动释放无用内存
139. this关键字的用法
this是自身的一个对象,代表对象本身,可以理解为:指向对象本身的一个指针。
this的用法在java中大体可以分为3种:
- 普通的直接引用,this相当于是指向当前对象本身。
- 形参与成员名字重名,用this来区分:
public Person(String name, int age) {
this.name = name;
this.age = age;
}
- 引用本类的构造函数
class Person{
private String name;
private int age;
public Person() {
}
public Person(String name) {
this.name = name;
}
public Person(String name, int age) {
this(name);
this.age = age;
}
}
140. super关键字的用法
super可以理解为是指向自己超(父)类对象的一个指针,而这个超类指的是离自己最近的一个父类。
super也有三种用法:
- 普通的直接引用
- 与this类似,super相当于是指向当前对象的父类的引用,这样就可以用super.xxx来引用父类的成员。
- 子类中的成员变量或方法与父类中的成员变量或方法同名时,用super进行区分
class Person{
protected String name;
public Person(String name) {
this.name = name;
}
}
class Student extends Person{
private String name;
public Student(String name, String name1) {
super(name);
this.name = name1;
}
public void getInfo(){
System.out.println(this.name); //Child
System.out.println(super.name); //Father
}
}
public class Test {
public static void main(String[] args) {
Student s1 = new Student("Father","Child");
s1.getInfo();
}
}
- 引用父类构造函数
- super(参数):调用父类中的某一个构造函数(应该为构造函数中的第一条语句)。
- this(参数):调用本类中另一种形式的构造函数(应该为构造函数中的第一条语句)。
- 为什么需要放在构造函数中的第一条语句:在构造函数中,如果你不指定构造器之间的调用关系 ,那么编译器会给你加上super()且放在第一行 ;目的是在初始化当前对象时,先保证了父类对象先初始化 。所以,你指定了构造函数间的调用,那么this()必须在第一行,以保证在执行任何动作前,对象已经完成了初始化。
141. 面向对象和面向过程的区别
面向过程:
- 面向过程是具体化的,流程化的,解决一个问题,你需要一步一步的分析,一步一步的实现。
- 优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源。比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,能是最重要的因素。
- 缺点:没有面向对象易维护、易复用、易扩展。
面向对象:
- 面向对象是模型化的,你只需抽象出一个类,这是一个封闭的盒子,在这里你拥有数据也拥有解决问题的方法。需要什么功能直接使用就可以了,不必去一步一步的实现,至于这个功能是如何实现的,不管调用者的事,会用就可以了。面向对象的底层其实还是面向过程,把面向过程抽象成类,然后封装,方便我们使用的就是面向对象了。
- 优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
- 缺点:性能比面向过程低
142. 在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?
帮助子类做初始化工作。
143. 内部类的分类有哪些
在Java中,可以将一个类的定义放在另外一个类的定义内部,这就是内部类。内部类本身就是类的一个属性,与其他属性定义方式一致。
内部类可以分为四种:成员内部类、局部内部类、匿名内部类和静态内部类。
静态内部类
定义在类内部的静态类,就是静态内部类。
public class Outer {
private static int radius = 1;
static class StaticInner {
public void visit() {
System.out.println("visit outer static variable:" + radius);
}
}
}
// 静态内部类可以访问外部类所有的静态变量,而不可访问外部类的非静态变量;
// 静态内部类的创建方式,new 外部类.静态内部类(),如下:
Outer.StaticInner inner = new Outer.StaticInner();
inner.visit();
成员内部类
定义在类内部,成员位置上的非静态类,就是成员内部类
public class Outer {
private static int radius = 1;
private int count =2;
class Inner {
public void visit() {
System.out.println("visit outer static variable:" + radius);
System.out.println("visit outer variable:" + count);
}
}
}
// 成员内部类可以访问外部类所有的变量和方法,包括静态和非静态,私有和公有。
// 部类依赖于外部类的实例,它的创建方式外部类实例.new 内部类(),如下:
Outer outer = new Outer();
Outer.Inner inner = outer.new Inner();
inner.visit();
局部内部类
定义在方法中的内部类,就是局部内部类
public class Outer {
private int out_a = 1;
private static int STATIC_b = 2;
public void testFunctionClass(){
int inner_c =3;
class Inner {
private void fun(){
System.out.println(out_a);
System.out.println(STATIC_b);
System.out.println(inner_c);
}
}
Inner inner = new Inner();
inner.fun();
}
public static void testStaticFunctionClass(){
int d =3;
class Inner {
private void fun(){
// System.out.println(out_a); 编译错误,定义在静态方法中的局部类不可以访问外部类的实例变量
System.out.println(STATIC_b);
System.out.println(d);
}
}
Inner inner = new Inner();
inner.fun();
}
}
// 定义在实例方法中的局部类可以访问外部类的所有变量和方法,定义在静态方法中的局部类只能访问外部类的静态变量和方法。
// 局部内部类的创建方式,在对应方法内,new 内部类(),如下:
public static void testStaticFunctionClass(){
class Inner {
}
Inner inner = new Inner();
}
匿名内部类
匿名内部类就是没有名字的内部类,日常开发中使用的比较多
public class Outer {
private void test(final int i) {
new Service() {
public void method() {
for (int j = 0; j < i; j++) {
System.out.println("匿名内部类" );
}
}
}.method();
}
}
//匿名内部类必须继承或实现一个已有的接口
interface Service{
void method();
}
// 除了没有名字,匿名内部类还有以下特点:
// 1.匿名内部类必须继承一个抽象类或者实现一个接口。
// 2.匿名内部类不能定义任何静态成员和静态方法。
// 3.当所在的方法的形参需要被匿名内部类使用时,必须声明为 final。
// 4.匿名内部类不能是抽象的,它必须要实现继承的类或者实现的接口的所有抽象方法。
匿名内部类创建方式:
new 类/接口{
//匿名内部类实现部分
}
内部类的优点
- 一个内部类对象可以访问创建它的外部类对象的内容,包括私有数据;
- 内部类不为同一包的其他类所见,具有很好的封装性;
- 内部类有效实现了“多重继承”,优化 java 单继承的缺陷;
- 匿名内部类可以很方便的定义回调。
内部类有哪些应用场景
- 一些多算法场合
- 解决一些非面向对象的语句块。
- 适当使用内部类,使得代码更加灵活和富有扩展性。
- 当某个类除了它的外部类,不再被其他的类使用时。
144. 为什么重写equals时必须重写hashCode方法?
因为Object规范中规定了:
如果两个对象通过equals方法比较是相等的,那么它们的hashCode方法结果值也是相等的。
因此,当只重写equals方法,不重写hashCode时,违反规定,对于HashSet, HashMap, HashTable等基于hash值的类就会出现问题。
145. BIO,NIO,AIO 有什么区别?
- BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
- NIO:Non IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过Channel(通道)通讯,实现了多路复用。
- AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
146. 什么是反射?
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射。
静态编译:在编译时确定类型,绑定对象
动态编译:运行时确定类型,绑定对象
优点: 运行期类型的判断,动态加载类,提高代码灵活度。
缺点:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的java代码要慢很多。
147. 反射机制的应用场景有哪些?
反射是框架设计的灵魂。
在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
举例:
- 使用JDBC连接数据库时使用Class.forName()通过反射加载数据库的驱动程序;
- Spring框架也用到很多反射机制, 经典的就是xml的配置模式。Spring 通过 XML 配置模式装载 Bean的过程:
- 将程序内所有 XML 或 Properties 配置文件加载入内存中;
- Java类里面解析xml或properties里面的内容,得到对应实体类的字节码字符串以及相关的属性信息;
- 使用反射机制,根据这个字符串获得某个类的Class实例;
- 动态配置实例的属性
148. Java获取反射的三种方法
- 通过new对象实现反射机制
- 通过路径实现反射机制
- 通过类名实现反射机制
public class Student {
private int id;
String name;
protected boolean sex;
public float score;
}
public class Get {
//获取反射机制三种方式
public static void main(String[] args) throws ClassNotFoundException {
//方式一(通过建立对象)
Student stu = new Student();
Class classobj1 = stu.getClass();
System.out.println(classobj1.getName());
//方式二(通过路径-相对路径)
Class classobj2 = Class.forName("包名.Student");
System.out.println(classobj2.getName());
//方式三(通过类名)
Class classobj3 = Student.class;
System.out.println(classobj3.getName());
}
}
149. 在使用 HashMap 的时候,用 String 做 key 有什么好处?
HashMap 内部实现是通过 key 的 hashcode 来确定 value 的存储位置,因为字符串是不可变的,所以当创建字符串时,它的 hashcode 被缓存下来,不需要再次计算,所以相比于其他对象更快。
150. 集合和数组的区别
- 数组是固定长度的;集合可变长度的。
- 数组可以存储基本数据类型,也可以存储引用数据类型;集合只能存储引用数据类型。
- 数组存储的元素必须是同一个数据类型;集合存储的对象可以是不同数据类型。
使用集合框架的好处
- 容量自增长;
- 提供了高性能的数据结构和算法,使编码更轻松,提高了程序速度和质量;
- 允许不同 API 之间的互操作,API之间可以来回传递集合;
- 可以方便地扩展或改写集合,提高代码复用性和可操作性;
- 通过使用JDK自带的集合类,可以降低代码维护和学习新API成本。
常用的集合类有哪些?
Map接口和Collection接口是所有集合框架的父接口:
- Collection接口的子接口包括:Set接口和List接口
- Map接口的实现类主要有:HashMap、TreeMap、Hashtable、 ConcurrentHashMap以及Properties等
- Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
- List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
集合框架底层数据结构
List
- Arraylist: Object数组
- Vector: Object数组
- LinkedList: 双向循环链表
Set
- HashSet(无序,唯一):基于 HashMap 实现的,底层采用 HashMap 来保存元素
- LinkedHashSet: LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基 于 Hashmap 实现一样,不过还是有一点点区别的。
- TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树。) Map
- HashMap: JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主 体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间
- LinkedHashMap:LinkedHashMap 继承自 HashMap,所以它的底层仍然是 基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面 结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。 同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
- HashTable: 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为 了解决哈希冲突而存在的
- TreeMap: 红黑树(自平衡的排序二叉树)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号