【学习】大数据实战—关键词排行榜
一、项目介绍
通过web网页获取到用户输入的关键词,将日志存入到linux(或windows)本地,并使用flume同步到hdfs中。
再通过MapReduce将数据进行处理,结合Hive和sqoop生成数据表存入Mysql中,最后生成关键词排行榜。
tomcat版本:8.5.xx
tomcat链接(linux):
https://tomcat.apache.org/download-80.cgi#8.5.59
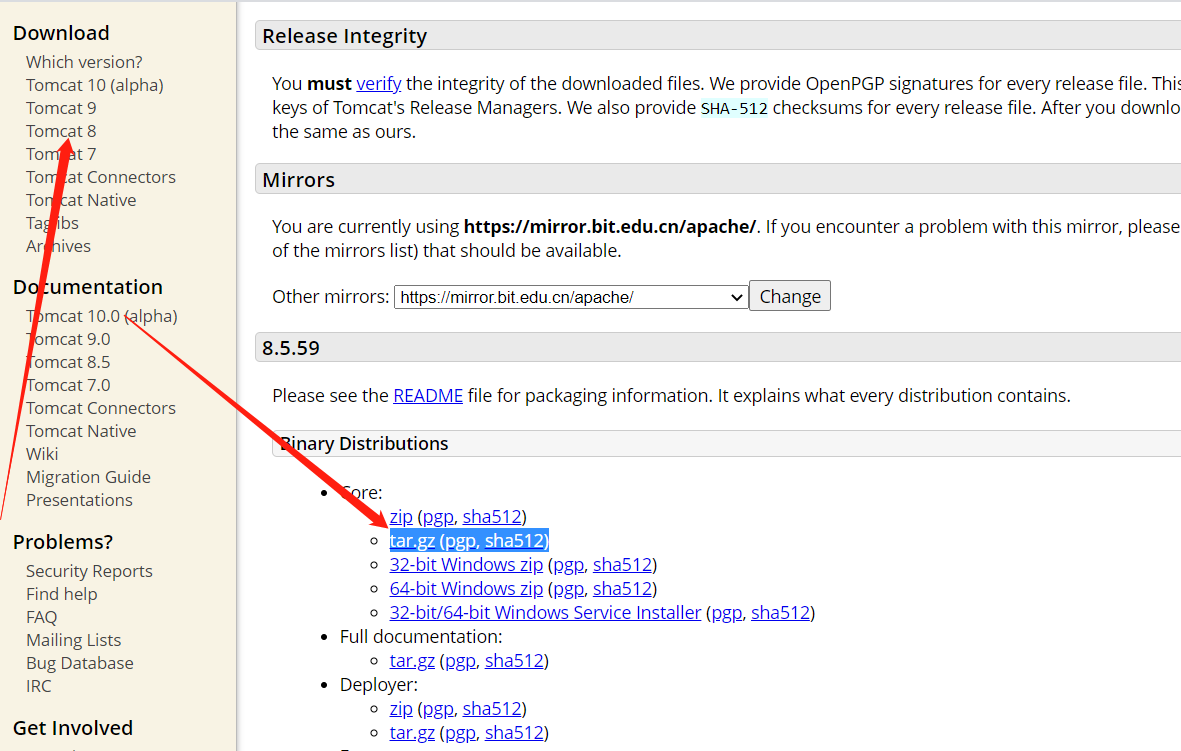
tomcat链接(windows):
https://tomcat.apache.org/download-80.cgi#8.5.59
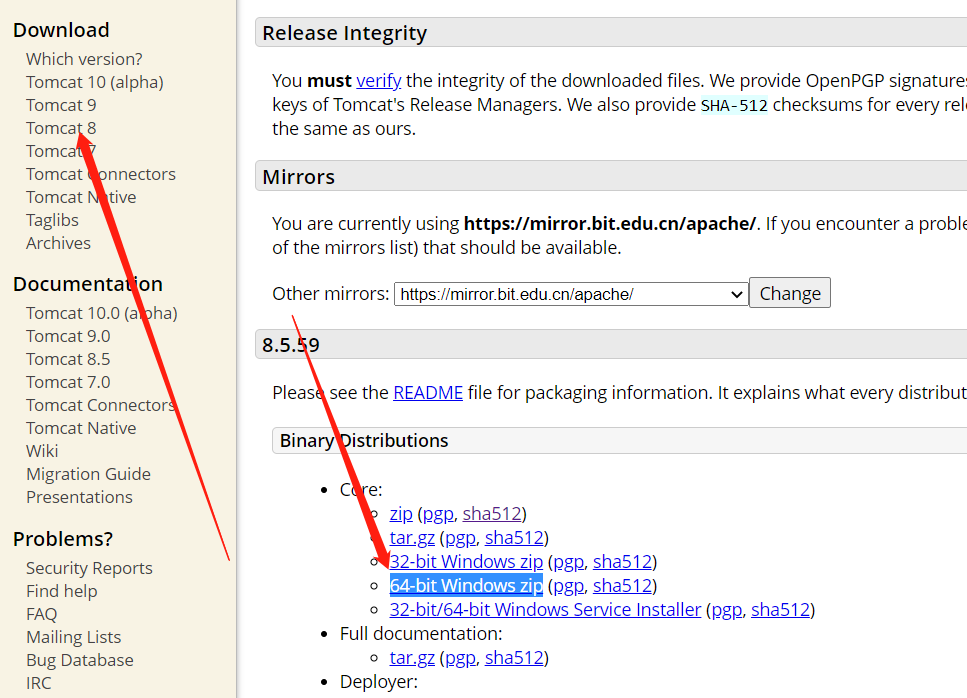
Centos版本:6.9
确保jdk,hadoop,hdfs,flume,sqoop都已经配置好
注:本篇博客的web程序在windows下编写调试
二、前端页面
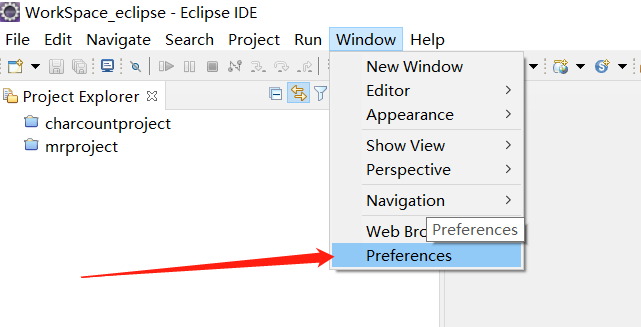
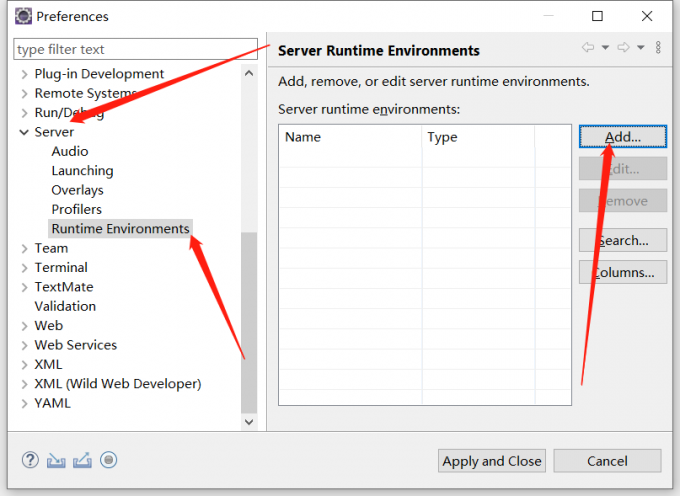
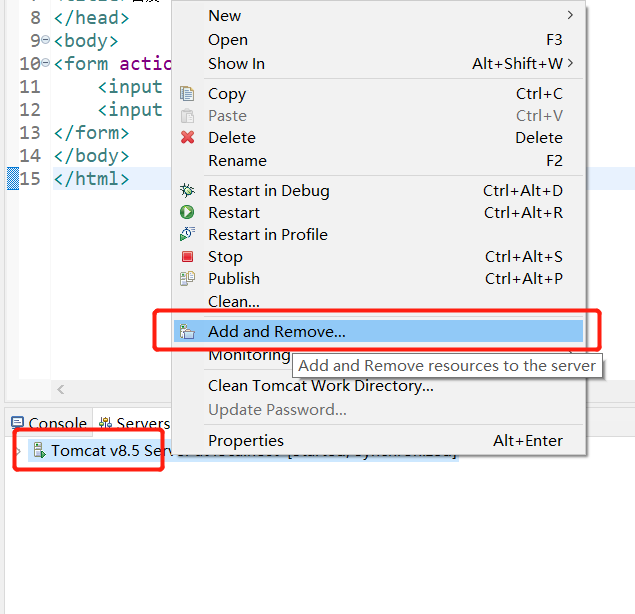
1.配置Tomcat
eclipse配置tomcat8.5
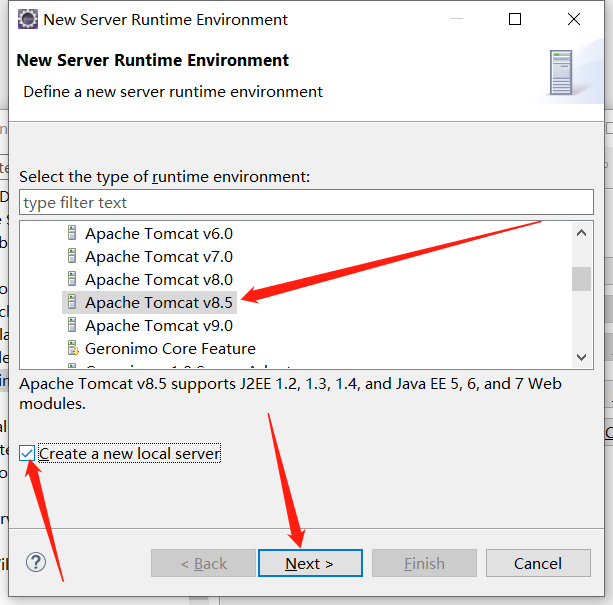
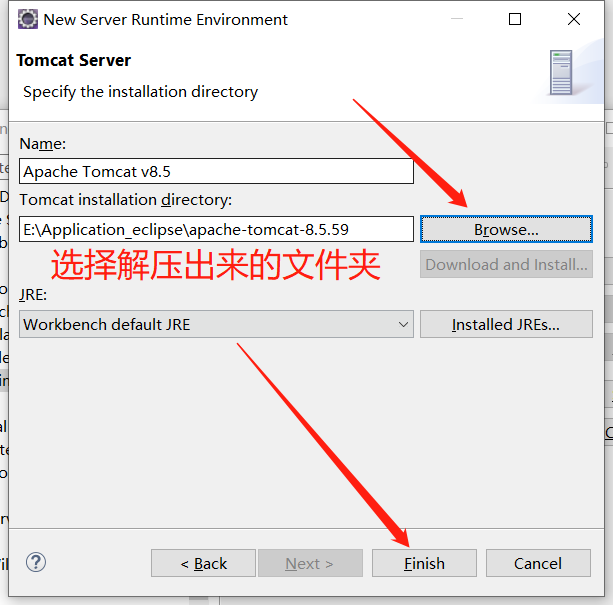
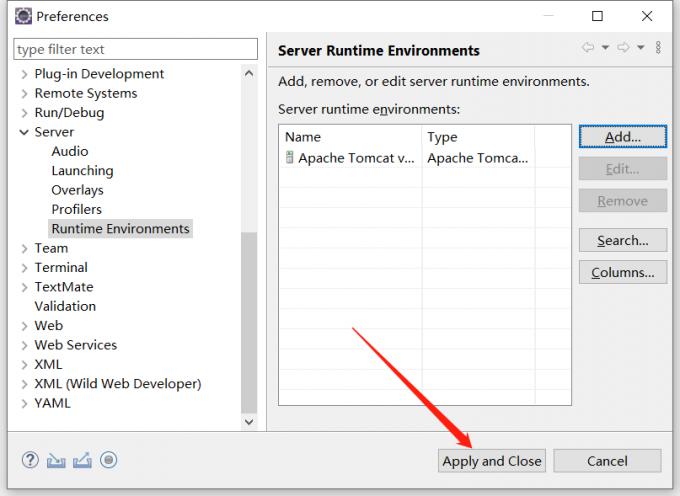
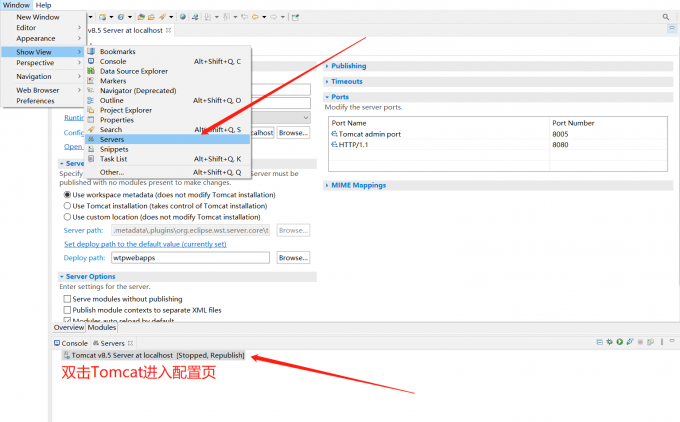
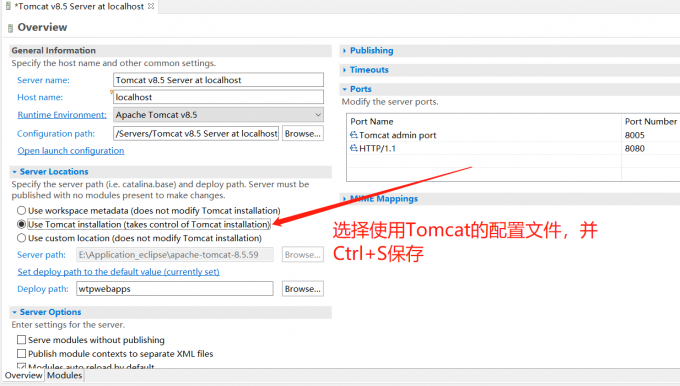
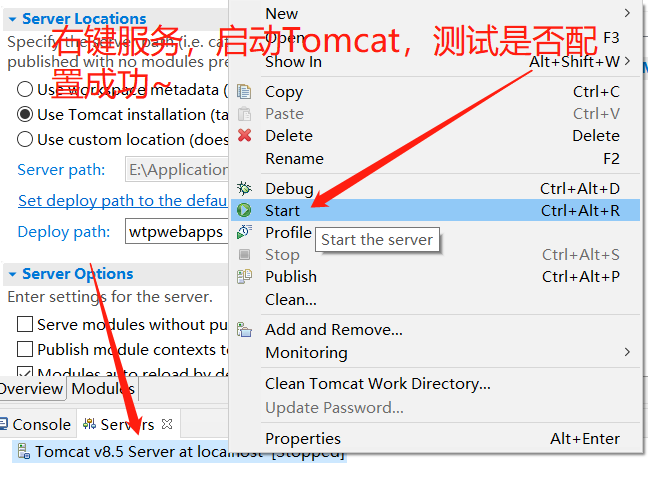
出现如下提示则配置成功~(访问http://localhost:8080/,如果有页面加载出来同样证明配置成功)
十月 13, 2020 11:04:02 上午 org.apache.catalina.startup.Catalina start
信息: Server startup in 1192 ms
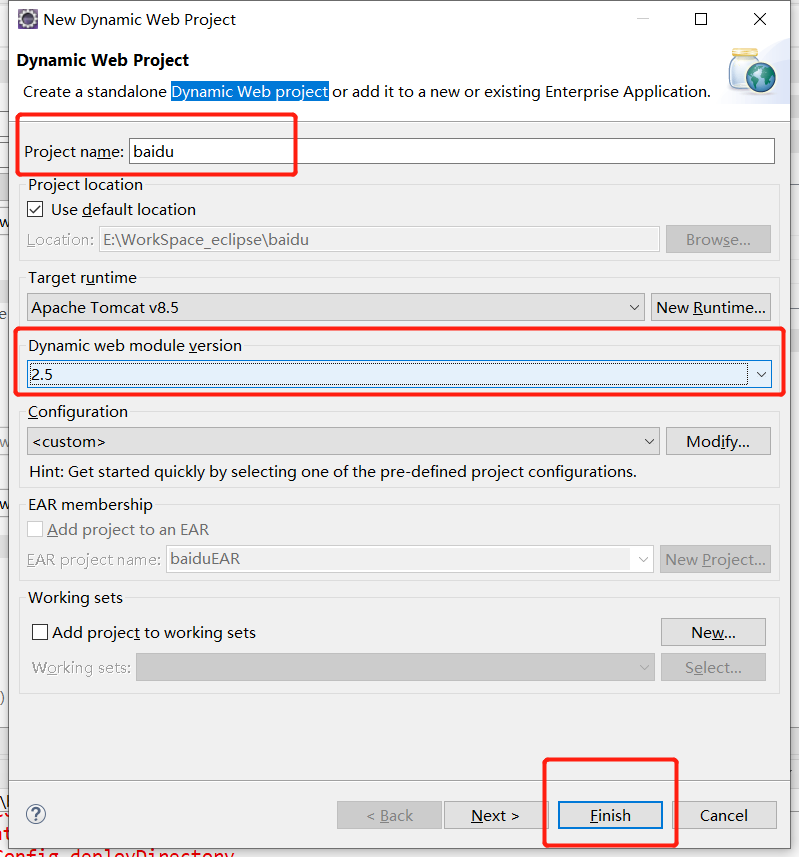
2.创建网站
创建Dynamic Web project项目
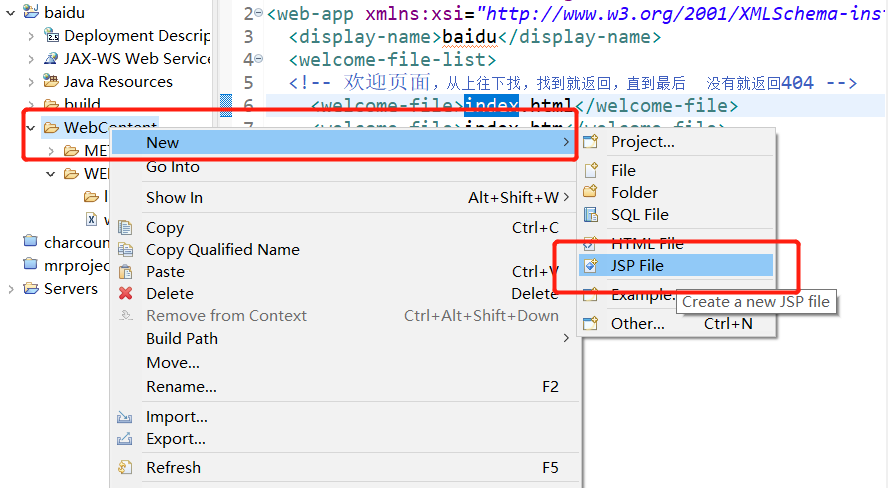
在WebContent下创建index.jsp
写个简单的jsp页面
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>百度一下,你就知道</title>
</head>
<body>
<form action="#">
<input type = "text" name = "wd" />
<input type = "submit" value = "百度一下" />
</form>
</body>
</html>
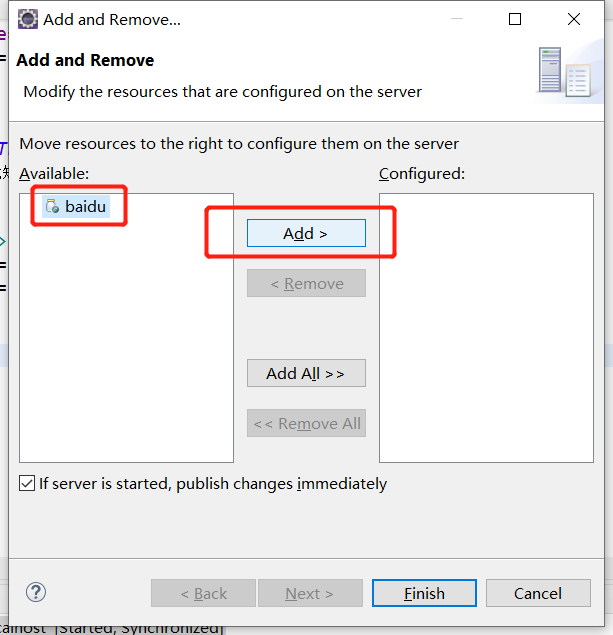
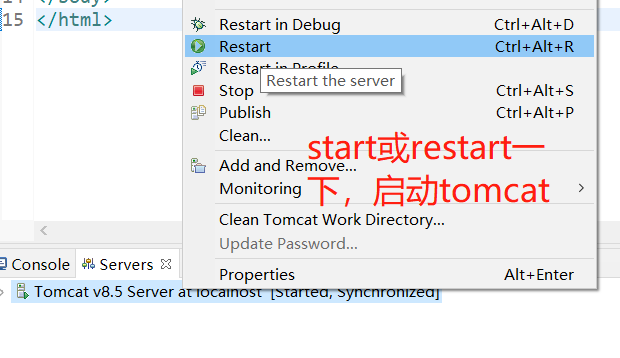
之后将页面添加进tomcat服务器,并重启tomcat
访问页面链接:http://localhost:8080/baidu
并尝试搜索几个关键词
之后找到tomcat配置目录,修改server.xml,使其能够存储用户的sessionid
我的路径为:
E:\Application_eclipse\apache-tomcat-8.5.59\conf
server.xml的倒数第5行左右,在Valve标签的pattern属性中添加一个%S,大写的S
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs" pattern="%h %l %u %t "%r" %s %b %S" prefix="localhost_access_log" suffix=".txt"/>
然后重启tomcat,在页面中随便搜索几个关键词
找到log目录,下面是我的路径
E:\Application_eclipse\apache-tomcat-8.5.59\logs
打开日志可以看见自己刚刚的搜索记录,并且后面的几条搜索记录中有sessionid
0:0:0:0:0:0:0:1 - - [13/Oct/2020:13:52:23 +0800] "GET /baidu/ HTTP/1.1" 200 253 1B7149C97A280ECBBB8E62D366071E65
0:0:0:0:0:0:0:1 - - [13/Oct/2020:13:52:24 +0800] "GET /favicon.ico HTTP/1.1" 200 21630 -
0:0:0:0:0:0:0:1 - - [13/Oct/2020:13:52:25 +0800] "GET /baidu/?wd=1231 HTTP/1.1" 200 253 1B7149C97A280ECBBB8E62D366071E65
0:0:0:0:0:0:0:1 - - [13/Oct/2020:13:52:27 +0800] "GET /baidu/?wd=asfasf HTTP/1.1" 200 253 1B7149C97A280ECBBB8E62D366071E65
0:0:0:0:0:0:0:1 - - [13/Oct/2020:13:52:29 +0800] "GET /baidu/?wd=java HTTP/1.1" 200 253 1B7149C97A280ECBBB8E62D366071E65
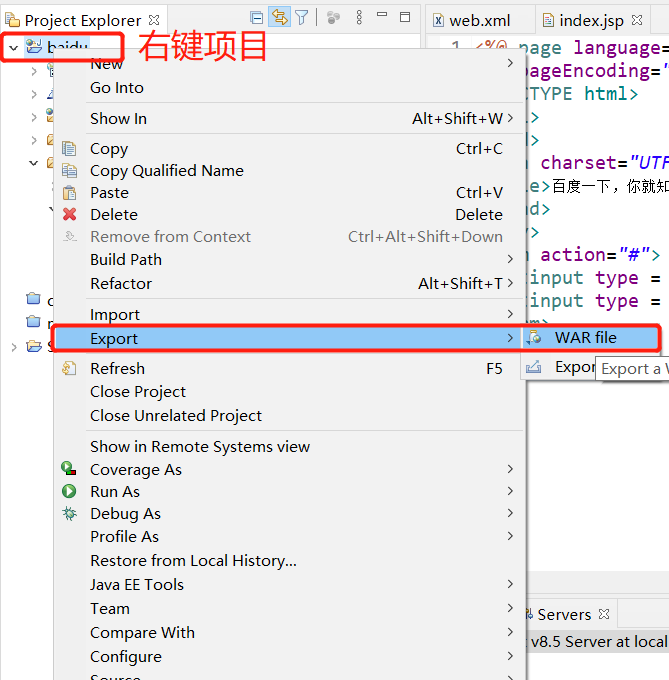
3.发布网站
成功后,将项目打包成war,名字“百度”即可
然后将baidu.war和tomcat的linux版本上传到centos中(我用xshell)
之后将apache-tomcat-8.5.39.tar.gz解压到你的应用路径下(我这里是/opt/modules/)
顺手给apache-tomcat-8.5.39改个名字
[hadoop@bigdata modules]$ mv apache-tomcat-8.5.39/ tomcat-8.5.39/
进入tomcat目录修改配置
[hadoop@bigdata modules]$ cd tomcat-8.5.39/
[hadoop@bigdata tomcat-8.5.39]$ ls
bin conf lib logs README.md RUNNING.txt webapps
BUILDING.txt CONTRIBUTING.md LICENSE NOTICE RELEASE-NOTES temp work
[hadoop@bigdata tomcat-8.5.39]$ cd conf/
[hadoop@bigdata conf]$ ls
catalina.policy context.xml jaspic-providers.xsd server.xml tomcat-users.xsd
catalina.properties jaspic-providers.xml logging.properties tomcat-users.xml web.xml
[hadoop@bigdata conf]$ vim server.xml
同样的,将tomcat的Valve标签的pattern最后加上%S,之后保存并退出
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b %S" />
进入webapps路径,将war包上传到此位置
[hadoop@bigdata conf]$ cd ..
[hadoop@bigdata tomcat-8.5.39]$ cd webapps/
[hadoop@bigdata webapps]$
进入tomcat根目录启动tomcat
[hadoop@bigdata tomcat-8.5.39]$ ls
bin conf lib logs README.md RUNNING.txt webapps
BUILDING.txt CONTRIBUTING.md LICENSE NOTICE RELEASE-NOTES temp work
[hadoop@bigdata tomcat-8.5.39]$ ls bin/
bootstrap.jar configtest.bat setclasspath.sh tomcat-native.tar.gz
catalina.bat configtest.sh shutdown.bat tool-wrapper.bat
catalina.sh daemon.sh shutdown.sh tool-wrapper.sh
catalina-tasks.xml digest.bat startup.bat version.bat
commons-daemon.jar digest.sh startup.sh version.sh
commons-daemon-native.tar.gz setclasspath.bat tomcat-juli.jar
[hadoop@bigdata tomcat-8.5.39]$ bin/startup.sh
Using CATALINA_BASE: /opt/modules/tomcat-8.5.39
Using CATALINA_HOME: /opt/modules/tomcat-8.5.39
Using CATALINA_TMPDIR: /opt/modules/tomcat-8.5.39/temp
Using JRE_HOME: /opt/modules/jdk1.8.0_171
Using CLASSPATH: /opt/modules/tomcat-8.5.39/bin/bootstrap.jar:/opt/modules/tomcat-8.5.39/bin/tomcat-juli.jar
Tomcat started.
[hadoop@bigdata tomcat-8.5.39]$
之后在windows下访问一下试试,访问链接:
http://centos的ip:8080/baidu/
然后去log目录下找到刚刚的日志信息
[hadoop@bigdata tomcat-8.5.39]$ cd logs/
[hadoop@bigdata logs]$ ls
catalina.2020-10-13.log host-manager.2020-10-13.log localhost_access_log.2020-10-13.txt
catalina.out localhost.2020-10-13.log manager.2020-10-13.log
[hadoop@bigdata logs]$ more localhost_access_log.2020-10-13.txt
192.168.30.1 - - [13/Oct/2020:12:46:52 +0800] "GET /baidu HTTP/1.1" 302 - -
192.168.30.1 - - [13/Oct/2020:12:46:53 +0800] "GET /baidu/ HTTP/1.1" 200 253 74FA95828C8CA2B5A02A824D442
2CA90
192.168.30.1 - - [13/Oct/2020:12:46:53 +0800] "GET /favicon.ico HTTP/1.1" 200 21630 -
192.168.30.1 - - [13/Oct/2020:12:48:03 +0800] "GET /baidu/?wd=java HTTP/1.1" 200 253 74FA95828C8CA2B5A02
A824D4422CA90
192.168.30.1 - - [13/Oct/2020:12:48:14 +0800] "GET /baidu/?wd=hadoop HTTP/1.1" 200 253 74FA95828C8CA2B5A
02A824D4422CA90
[hadoop@bigdata logs]$
三、日志收集
1.编写flume配置文件
启动hadoop
[hadoop@bigdata logs]$ cd /opt/modules/hadoop-2.6.0-cdh5.7.6/
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ sbin/start-daemon.sh
starting namenode, logging to /opt/modules/hadoop-2.6.0-cdh5.7.6/logs/hadoop-hadoop-namenode-bigdata.out
starting datanode, logging to /opt/modules/hadoop-2.6.0-cdh5.7.6/logs/hadoop-hadoop-datanode-bigdata.out
starting resourcemanager, logging to /opt/modules/hadoop-2.6.0-cdh5.7.6/logs/yarn-hadoop-resourcemanager-bigdata.out
starting nodemanager, logging to /opt/modules/hadoop-2.6.0-cdh5.7.6/logs/yarn-hadoop-nodemanager-bigdata.out
starting historyserver, logging to /opt/modules/hadoop-2.6.0-cdh5.7.6/logs/mapred-hadoop-historyserver-bigdata.out
3808 Bootstrap
4064 NameNode
4305 JobHistoryServer
4243 NodeManager
4355 Jps
4185 ResourceManager
4125 DataNode
在hdfs中创建该项目日志专属目录
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ bin/hdfs dfs -mkdir -p /baidu/day20201013
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ bin/hdfs dfs -ls /baidu/
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2020-10-13 14:08 /baidu/day20201013
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$
之后创建flume关于baidu的配置文件
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ cd /opt/modules/flume-1.6.0-cdh5.7.6-bin/
[hadoop@bigdata flume-1.6.0-cdh5.7.6-bin]$ cd case/
[hadoop@bigdata case]$ vim baidu.properties
内容为(这里要注意路径哦~):
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -f /opt/modules/tomcat-8.5.39/logs/localhost_access_log.2020-10-13.txt
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /baidu/day20201013
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
之后启动flume
[hadoop@bigdata case]$ cd ..
[hadoop@bigdata flume-1.6.0-cdh5.7.6-bin]$ bin/flume-ng agent --conf /opt/modules/flume-1.6.0-cdh5.7.6-bin/conf/ --conf-file case/baidu.properties --name a1
2.完成日志收集
手动构造数据,在搜索页面多搜索一些关键词,例如以下关键词各来一些:
hadoop
java
spark
tom
jack
rose
nokia
apple
huawei
sony
可以使用hdfs指令查询日志是否同步成功
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ bin/hdfs dfs -cat /baidu/day20201013/F*
成功后用ctrl+c关闭flume
四、数据清洗
1.编写mr
使用eclipse创建maven项目
项目结构
pom.xml代码
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hadoop</groupId>
<artifactId>baiduproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.7.6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-cdh5.7.6</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>E:/plug-in_java/lib/tools.jar</systemPath>
</dependency>
</dependencies>
</project>
定义日志写入实体类WebLogWritable
package com.hadoop.baidu;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* 针对每一条的weblog,记录为一个实例对象
* 日志的数据j就是里面的字段
* 要让hdfs跑起来,需要实现WritableComparable(参照NullWritable和IntWritable)
* @author alpha
*
*/
public class WebLogWritable implements WritableComparable<WebLogWritable> {
private String KeyWord; // 搜索的关键字
private String sessionId; // 用户的唯一标识符
private boolean flag = true; // 标记变量,如果为false则认为是脏数据,直接丢弃
/**
* 序列化,本质上是支持将对象写入文件
*/
public void write(DataOutput out) throws IOException {
// 将属性写入文件
out.writeUTF(this.KeyWord);
out.writeUTF(this.sessionId);
}
/**
* 反序列化,本质上是支持将文件读取为java对象
*/
public void readFields(DataInput in) throws IOException {
// 将属性从文件中读取,注意,读取顺序必须和写入顺序一致
this.KeyWord = in.readUTF();
this.sessionId = in.readUTF();
}
public WebLogWritable() {
super();
// TODO Auto-generated constructor stub
}
public WebLogWritable(String keyWord, String sessionId, boolean flag) {
super();
KeyWord = keyWord;
this.sessionId = sessionId;
this.flag = flag;
}
public String getKeyWord() {
return KeyWord;
}
public void setKeyWord(String keyWord) {
KeyWord = keyWord;
}
public String getSessionId() {
return sessionId;
}
public void setSessionId(String sessionId) {
this.sessionId = sessionId;
}
public boolean isFlag() {
return flag;
}
public void setFlag(boolean flag) {
this.flag = flag;
}
@Override
public String toString() {
// 指定类输出的格式,这里就是将来的文件格式
return this.KeyWord+"\t"+this.sessionId;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((KeyWord == null) ? 0 : KeyWord.hashCode());
result = prime * result + (flag ? 1231 : 1237);
result = prime * result + ((sessionId == null) ? 0 : sessionId.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
WebLogWritable other = (WebLogWritable) obj;
if (KeyWord == null) {
if (other.KeyWord != null)
return false;
} else if (!KeyWord.equals(other.KeyWord))
return false;
if (flag != other.flag)
return false;
if (sessionId == null) {
if (other.sessionId != null)
return false;
} else if (!sessionId.equals(other.sessionId))
return false;
return true;
}
/**
* 可比较对象的方法,实现和自己的比较
*/
public int compareTo(WebLogWritable o) {
// 排序用的返回-1表示小,返回0一样,返回1表示大
int com = this.KeyWord.compareTo(o.KeyWord);
if(com == 0) {
com = this.sessionId.compareTo(o.sessionId);
}
return com;
}
}
创建获取日志类WebLogWritableUtil
package com.hadoop.baidu;
/**
* 这个工具类用于实现数据清洗
* 返回WebLogWritable对象
* 如果是脏数据,flag为false
* @author alpha
*
*/
public class WebLogWritableUtil {
/**
* 用来进行数据的清洗
* @param line 每一行的数据
* @return 封装好的WebLogWritable实例对象
*/
public static WebLogWritable getWebWritable(String line) {
WebLogWritable web = new WebLogWritable();
/*
* 传入数据:
*
* [0]:192.168.30.1
* [1]:-
* [2]:-
* [3]:[13/Oct/2020:15:36:33
* [4]:+0800]
* [5]:"GET
* [6]:/baidu/?wd=sony
* [7]:HTTP/1.1"
* [8]:200
* [9]:253
* [10]:43A636CA0BF39C281CD4A2EBFB438350
*/
String[] items = line.split(" ");
if(items.length >= 11) {
if(items[6].indexOf("=") > 0) {
String KeyWord = items[6].substring(items[6].indexOf("=")+1);
web.setKeyWord(KeyWord);
}else {
web.setFlag(false);
}
if(items[10].length() <= 0 || "-".equals(items[10])) {
// 脏数据
web.setFlag(false);
}else {
String sessionId = items[10];
web.setSessionId(sessionId);
}
}else {
// 脏数据
web.setFlag(false);
}
return web;
}
}
驱动类WebLogDriver
package com.hadoop.baidu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 驱动类,唯一不同的是
* 此处不需要reduce进程
* @author alpha
*
*/
public class WebLogDriver extends Configured implements Tool{
public static void main(String[] args) {
Configuration conf = new Configuration();
try {
int status = ToolRunner.run(conf, new WebLogDriver(), args);
System.exit(status);
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
public int run(String[] args) throws Exception {
// create job
Job job = Job.getInstance(this.getConf(), "baidu-text");
job.setJarByClass(WebLogDriver.class);
// input
Path inputPath = new Path(args[0]);
FileInputFormat.setInputPaths(job, inputPath);
// map
job.setMapperClass(WebLogMapper.class);
job.setMapOutputKeyClass(WebLogWritable.class);
job.setMapOutputValueClass(NullWritable.class);
// shuffle
// reduce
job.setNumReduceTasks(0);
// output
Path outputPath = new Path(args[1]);
// hdfsAPI 如果目录事先存在,则删除
FileSystem hdfs = FileSystem.get(this.getConf());
if(hdfs.exists(outputPath)) {
hdfs.delete(outputPath, true);
}
FileOutputFormat.setOutputPath(job, outputPath);
// submit job
boolean flag = job.waitForCompletion(true);
return flag?0:1;
}
}
Mapper类WebLogMapper
package com.hadoop.baidu;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* <KEYIN LongWritable
* , VALUEIN Text
* , KEYOUT WebLogWritable
* , VALUEOUT NullWritable
* >
* @author alpha
*
*/
public class WebLogMapper extends Mapper<LongWritable, Text, WebLogWritable, NullWritable>{
private WebLogWritable web = new WebLogWritable();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, WebLogWritable, NullWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
this.web = WebLogWritableUtil.getWebWritable(line);
// 仅保存flag为true的
if(web.isFlag()) {
context.write(web, NullWritable.get());
}
}
}
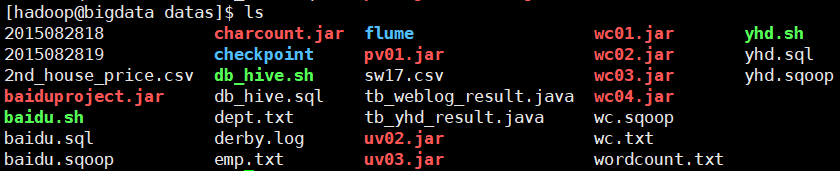
2. 上传到CentOs中
五、编写SQL,SQOOP和SH文件
1.SQL
编写baidu.sql执行HQL,生成结果表,并设置本地模式
set hive.exec.model.local.auto=true;
drop table if exists db_baidu.tb_weblog;(数据库名字.表的名字)
drop table if exists db_baidu.tb_weblog_result;(数据库名字.表的名字)
drop database if exists db_baidu;
create database db_baidu;
create table db_baidu.tb_weblog(
keyword string,
sessionid string
)
row format delimited fields terminated by '\t';
load data inpath '/baidu/mr' into table db_baidu.tb_weblog;
create table db_baidu.tb_weblog_result as
select keyword,count(*) as cnt from db_baidu.tb_weblog group by keyword order by cnt desc limit 10;
2.SQOOP
编写baidu.sqoop
export
--connect
jdbc:mysql://你的hostname:3306/数据库名称
--username
用户名
--password
密码
--table
tb_weblog_result(结果表名称)
--export-dir
/user/hive/warehouse/db_baidu.db/tb_weblog_result
--fields-terminated-by
'\001'
-m
1
3.SH
#! /bin/bash
HADOOP_HOME=/opt/modules/hadoop-2.6.0-cdh5.7.6(hadoop目录)
HIVE_HOME=/opt/modules/hive-1.1.0-cdh5.7.6(hive目录)
SQOOP_HOME=/opt/modules/sqoop-1.4.6-cdh5.7.6(sqoop目录)
$HADOOP_HOME/bin/yarn jar /opt/datas/baiduproject.jar com.hadoop.baidu.WebLogDriver /baidu/day20201013 /baidu/mr(执行mr)
$HIVE_HOME/bin/hive -f /opt/datas/baidu.sql
$SQOOP_HOME/bin/sqoop --options-file /opt/datas/baidu.sqoop
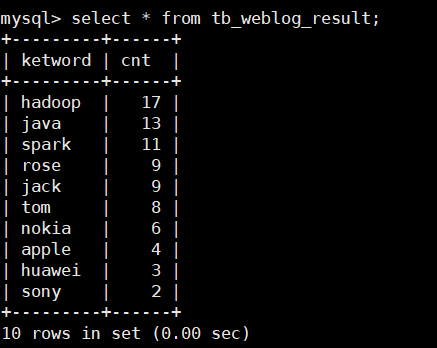
六、执行结果
[hadoop@bigdata datas]$ ./baidu.sh
.
.
.
.
.
20/10/17 16:58:01 INFO mapreduce.ExportJobBase: Transferred 240 bytes in 24.467 seconc)
20/10/17 16:58:01 INFO mapreduce.ExportJobBase: Exported 10 records.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号