【学习】CentOS 6.x安装hadoop 2.6.0
一、说明
系统:CentOS 6.9
hadoop版本:2.6.0
hadoop下载链接:http://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
用户名:hadoop
hostname:bigdata
jdk版本:1.8
jdk下载链接:
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html#license-lightbox
native下载链接:http://dl.bintray.com/sequenceiq/sequenceiq-bin/:hadoop-native-64-2.6.0.tar
前置要求:CentOS能够正常联网,且hostname已经配置好,登录用户已经做好sudo权限
我的指令在Xshell中执行的,在Terminal中同理,建议所有指令都与我相同,避免出现不可逆问题
二、环境配置
由于hadoop需要jdk 1.8版本 CentOS 6.x默认jdk版本不符,先在root用户下查询一下已安装的jdk
[hadoop@bigdata ~]$ su - root
Password:
[root@bigdata ~]# rpm -qa | grep java
以下为执行后显示的内容:
java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64
tzdata-java-2016j-1.el6.noarch
java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64
一般情况下都是没有jdk 1.8的,有的话请跳过这步。
卸载低版本jdk,一句一句执行
[root@bigdata ~]# rpm -e --nodeps java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64
[root@bigdata ~]# rpm -e --nodeps tzdata-java-2016j-1.el6.noarch
[root@bigdata ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64
之后可以查询一下是否还有低版本jdk,执行之后没有jdk则成功
[root@bigdata ~]# rpm -qa | grep java
临时关闭防火墙
[root@bigdata ~]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
关闭防火墙开机自启动
[root@bigdata ~]# chkconfig iptables off
打开selinux配置文件(安全软件)
[root@bigdata ~]# vim /etc/selinux/config
按i进入编辑模式(左下角会显示insert),之后将selinux配置文件修改
SELINUX=enforcing 改为 SELINUX=disabled
之后按Esc推出编辑模式,再依次输入':wq'保存并退出
之后切换到opt目录,创建三个文件夹,并修改权限(hadoop改为你登录用户的名字)
[root@bigdata ~]# cd /opt/
[root@bigdata opt]# mkdir datas
[root@bigdata opt]# mkdir modules
[root@bigdata opt]# mkdir tools
[root@bigdata opt]# chown hadoop:hadoop ./datas/
[root@bigdata opt]# chown hadoop:hadoop ./modules/
[root@bigdata opt]# chown hadoop:hadoop ./tools/
[root@bigdata opt]# ll
total 16
drwxr-xr-x. 2 hadoop hadoop 4096 Sep 25 18:38 datas
drwxr-xr-x. 2 hadoop hadoop 4096 Sep 25 18:38 modules
drwxr-xr-x. 2 root root 4096 Mar 26 2015 rh
drwxr-xr-x. 2 hadoop hadoop 4096 Sep 25 18:39 tools
之后切换回hadoop用户(切换到你登录用户)
[root@bigdata opt]# exit
将jdk 1.8上传到CentOS中,可以用xshell也可以用vm复制,也可以用cmd的执行sftp指令上传,我以sftp为例(文件写自己文件路径),我将文件上传到了刚刚创建的opt/tools中了
C:\Users\alpha>sftp root@bigdata
root@bigdata's password:
Connected to root@bigdata.
sftp> put E:\安装包和文件备份\jdk-8u171-linux-x64.tar.gz /opt/tools/
之后检查一下tools文件夹中是否存在了jdk安装文件
[hadoop@bigdata tools]$ ls
jdk-8u171-linux-x64.tar.gz
将文件解压到opt/modules
[hadoop@bigdata tools]$ tar -zxf jdk-8u171-linux-x64.tar.gz -C /opt/modules/
解压完成后,跳转至解压目录,并复制jdk路径(将pwd执行后的路径复制),然后打开配置文件
[hadoop@bigdata tools]$ cd /opt/modules/jdk1.8.0_171/
[hadoop@bigdata jdk1.8.0_171]$ pwd
/opt/modules/jdk1.8.0_171
[hadoop@bigdata jdk1.8.0_171]$ sudo vim /etc/profile
之后将光标移至最下方,打开编辑模式(按i),在最后输入如下内容,然后Esc退出编辑模式,输入':wq'推保存退出
# JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin
然后输入,使配置立即生效
[hadoop@bigdata ~]$ source /etc/profile
验证是否成功,如下则成功
[hadoop@bigdata ~]$ java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
三、HDFS配置
将hadoop和native上传到/opt/tools/目录(与jdk上传方法相同)
切换到/opt/tools目录,解压hadoop到opt/modules/
[hadoop@bigdata ~]$ cd /opt/tools/
[hadoop@bigdata tools]$ ls
hadoop-2.6.0-cdh5.7.6.tar.gz jdk-8u171-linux-x64.tar.gz native-cdh5.7.6.tar.gz
[hadoop@bigdata tools]$ tar -zxf hadoop-2.6.0-cdh5.7.6.tar.gz -C /opt/modules/
将native解压到/opt/modules/hadoop-2.6.0-cdh5.7.6/lib下,路径名与你hadoop版本有关,建议自己cd过去找找
[hadoop@bigdata tools]$ tar -zxf native-cdh5.7.6.tar.gz -C /opt/modules/hadoop-2.6.0-cdh5.7.6/lib
解压完成后切换到hadoop的配置文件中,并通过pwd指令获取当前路径然后手动复制下来
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ cd /opt/modules/hadoop-2.6.0-cdh5.7.6/etc/hadoop
[hadoop@bigdata hadoop]$ pwd
/opt/modules/hadoop-2.6.0-cdh5.7.6/etc/hadoop
修改hadoop全局运行文件
[hadoop@bigdata hadoop]$ vim hadoop-env.sh
在export JAVA_HOME=后写上你的jdk路径,然后保存并退出
export JAVA_HOME=/opt/modules/jdk1.8.0_171
之后配置mr的运行环境
[hadoop@bigdata hadoop]$ vim mapred-env.sh
跟上面一样,然后保存并退出
export JAVA_HOME=/opt/modules/jdk1.8.0_171
然后配置yarn
[hadoop@bigdata hadoop]$ vim yarn-env.sh
同样找到export JAVA_HOME,保存并退出
export JAVA_HOME=/opt/modules/jdk1.8.0_171
找到hadoop文件夹,创建hadoop数据临时存放文件夹datas,并进入datas获取路径
[hadoop@bigdata hadoop]$ cd /opt/modules/hadoop-2.6.0-cdh5.7.6/
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ mkdir datas
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ cd datas
[hadoop@bigdata datas]$ pwd
/opt/modules/hadoop-2.6.0-cdh5.7.6/datas
回到hadoop目录打开core配置文件
[hadoop@bigdata datas]$ cd ../etc/hadoop
[hadoop@bigdata hadoop]$ vim core-site.xml
找到configuration标签,将下面内容粘贴进configuration标签,并保存(修改好自己的路路径)
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.6.0-cdh5.7.6/datas</value>
</property>
打开hdfs-site.xml
[hadoop@bigdata hadoop]$ vim hdfs-site.xml
找到configuration标签,将下面内容粘贴进configuration标签,并保存(修改好自己的路路径)
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
格式化hdfs文件系统(如果出错了就是上面几个配置文件路径有问题)
[hadoop@bigdata hadoop]$ cd ../..
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ bin/hdfs namenode -format
最后几行出现:
20/09/25 20:35:33 INFO util.ExitUtil: Exiting with status 0
表示成功
启动主节点(先namenode后datanode)
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/modules/hadoop-2.6.0-cdh5.7.6/logs/hadoop-hadoop-namenode-bigdata.out
使用jps查询进程,看看是否启动成功
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ jps
2868 NameNode
2937 Jps
启动从节点,并查询是否成功
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/modules/hadoop-2.6.0-cdh5.7.6/logs/hadoop-hadoop-datanode-bigdata.out
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ jps
2964 DataNode
2868 NameNode
3036 Jps
打开任意浏览器(虚拟机外)地址栏输入'ip:50070'查看监控页面,以我为例
http://bigdata:50070/
测试一下
进入datas目录创建一个wordcount.txt
[hadoop@bigdata ~]$ cd /opt/datas
[hadoop@bigdata datas]$ vim wordcount.txt
内容如下:
word hadoop java
hadoop spark mysql
hadoop java scala
之后回到hadoop目录在集群上创建一个datas文件夹
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ bin/hdfs dfs -mkdir /datas
在集群中查看
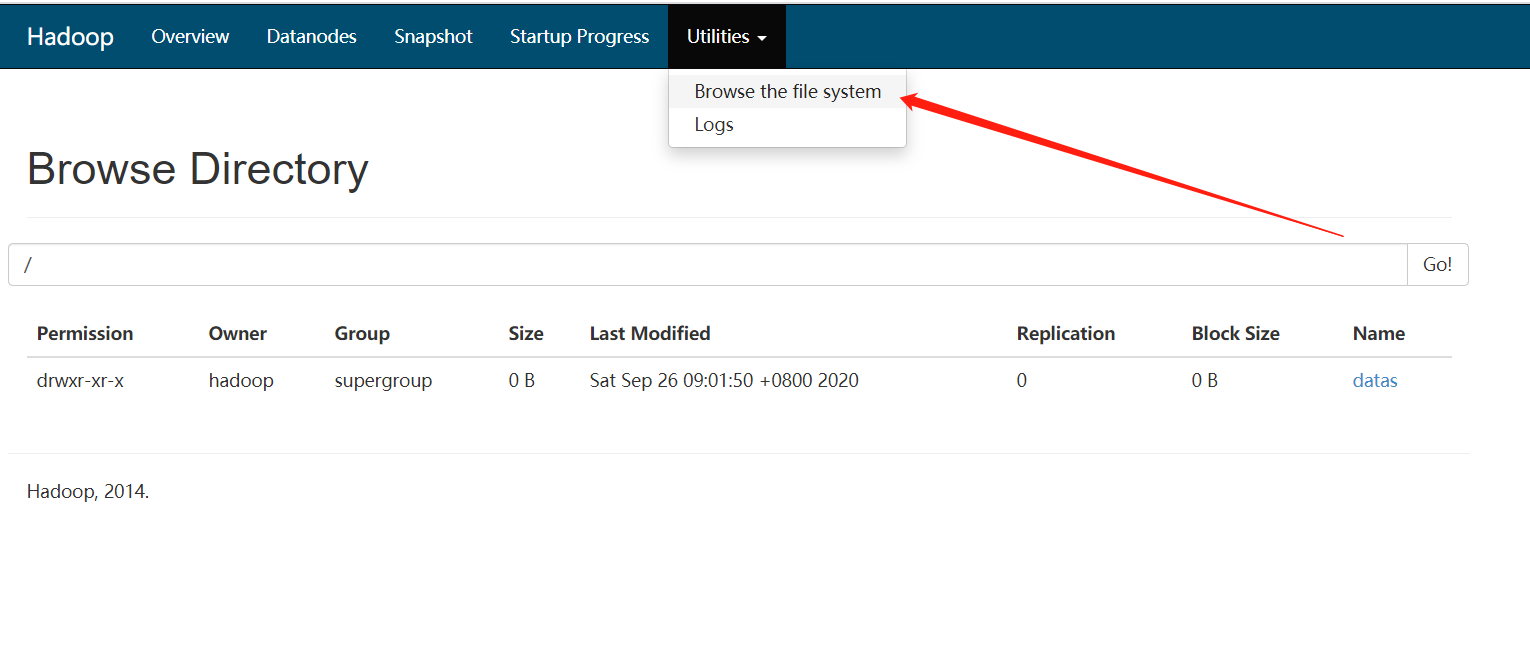
将刚刚创建的wordcount上传到集群中
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ bin/hdfs dfs -put /opt/datas/wordcount.txt /datas
查看
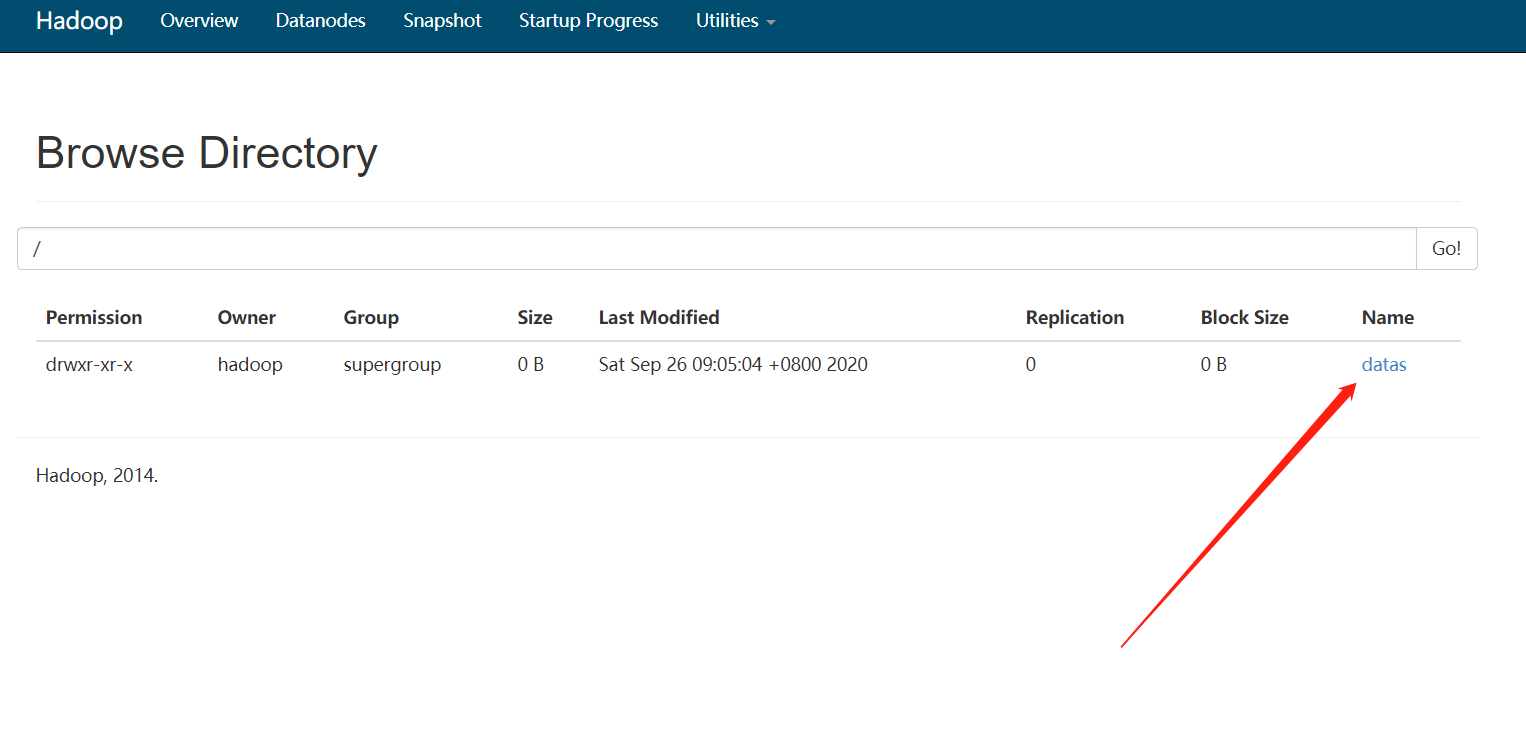
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ bin/hdfs dfs -ls /datas
Found 1 items
-rw-r--r-- 1 hadoop supergroup 54 2020-09-26 09:05 /datas/wordcount.txt
关闭集群
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ sbin/hadoop-daemon.sh stop datanode
stopping datanode
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ sbin/hadoop-daemon.sh stop namenode
stopping namenode
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ jps
3446 Jps
三、mapreduce配置
进入hadoop配置路径
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ cd /opt/modules/hadoop-2.6.0-cdh5.7.6/etc/hadoop
打开mapred-site.xml
[hadoop@bigdata hadoop]$ vim mapred-site.xml
将下方内容插入到configuration标签中
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
之后打开yarn-site.xml
[hadoop@bigdata hadoop]$ vim yarn-site.xml
将下方内容插入到configuration标签中,其中第二个value写你自己的域名解析
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata</value>
</property>
之后回到hadoop根目录启动hadoop和yarn
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ cd etc/hadoop
[hadoop@bigdata hadoop]$ cd ../..
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/modules/hadoop-2.6.0-cdh5.7.6/logs/hadoop-hadoop-namenode-bigdata.out
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/modules/hadoop-2.6.0-cdh5.7.6/logs/hadoop-hadoop-datanode-bigdata.out
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/modules/hadoop-2.6.0-cdh5.7.6/logs/yarn-hadoop-resourcemanager-bigdata.out
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/modules/hadoop-2.6.0-cdh5.7.6/logs/yarn-hadoop-nodemanager-bigdata.out
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ jps
5430 DataNode
5527 ResourceManager
5341 NameNode
5805 Jps
5773 NodeManager
查看mapreduce监控页面,网址'ip或域名解析:8088'
http://bigdata:8088/
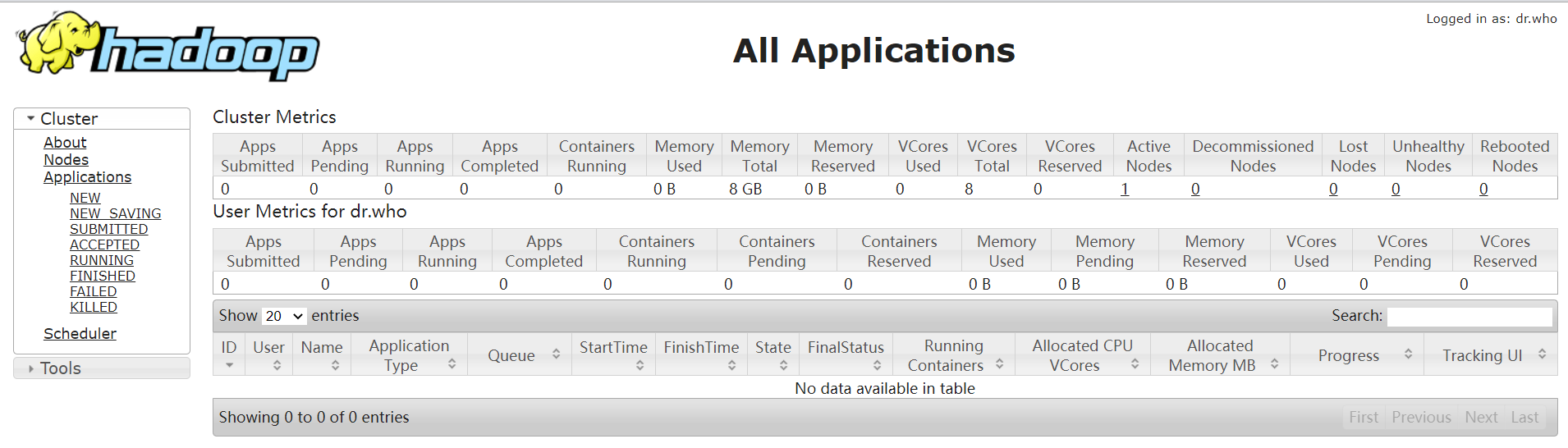
四、测试
测试一下统计词频,(前提是hdfs集群中已经存在了/datas/worcount.txt文件,没有的话请看上面的教程)
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.6.jar wordcount /datas/wordcount.txt /datas/wcout/wc-1
执行过程中可以在maprduce监控页面看到
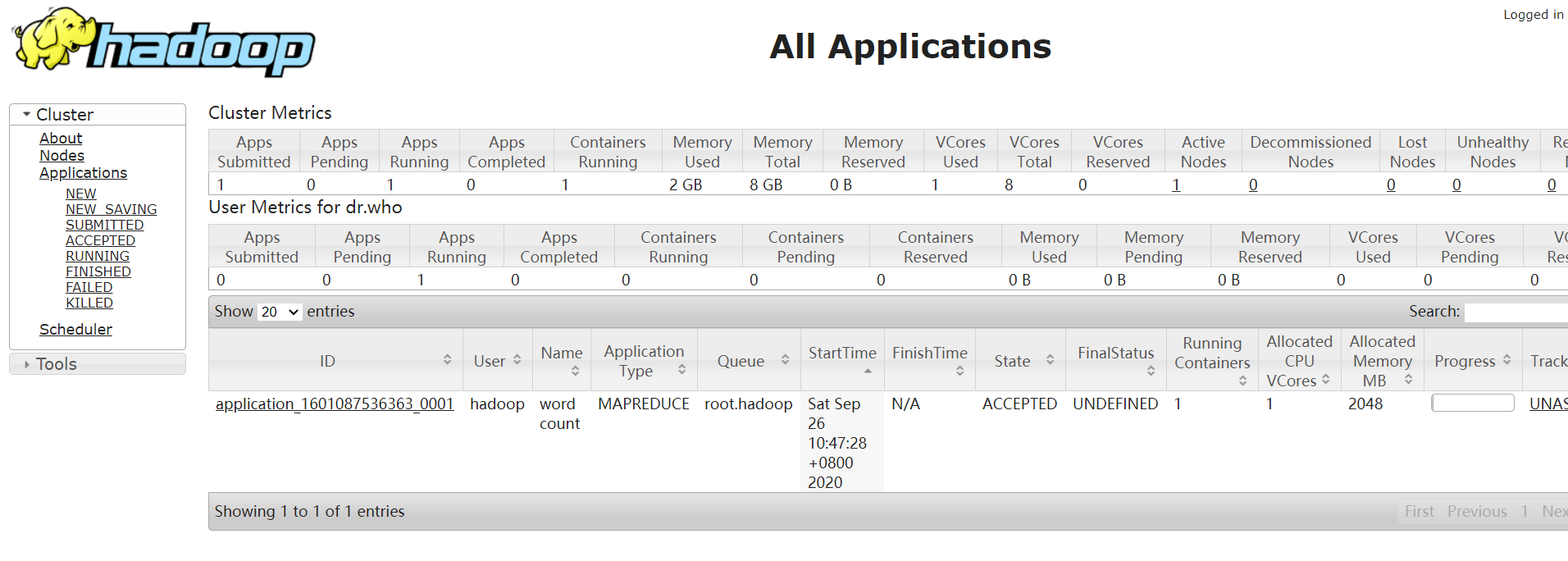
执行成功后,将结果输出在了hdfs集群中,可以在浏览器中访问 域名:50070
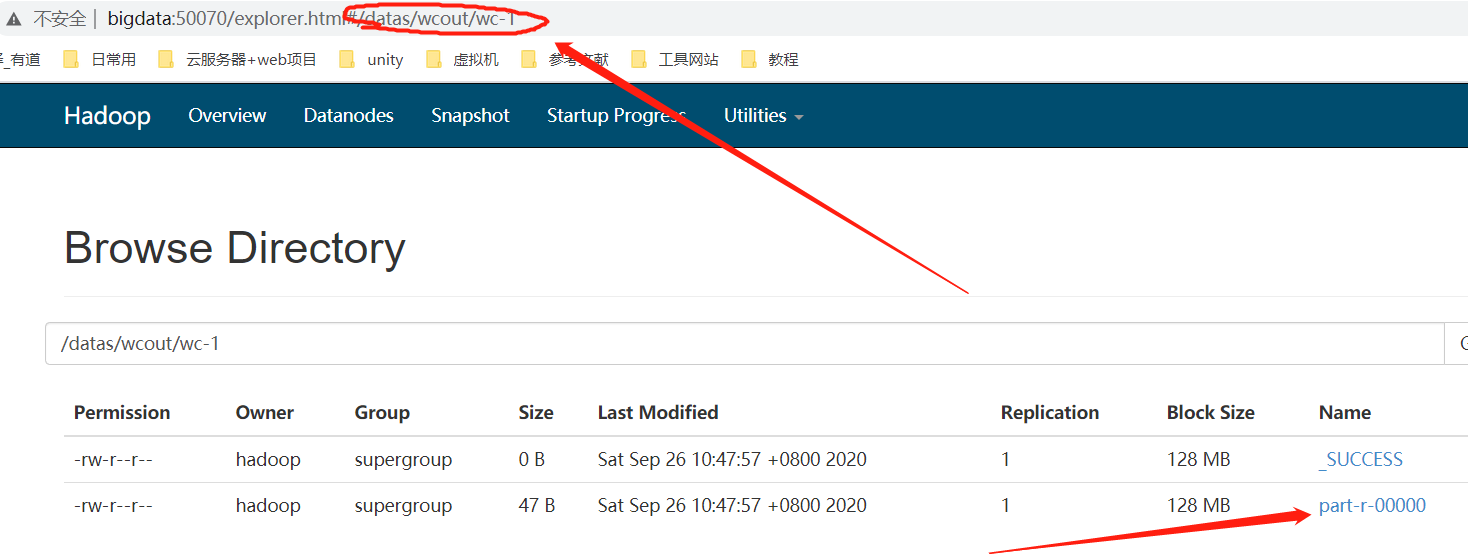
查看结果
[hadoop@bigdata hadoop-2.6.0-cdh5.7.6]$ bin/hdfs dfs -cat /datas/wcout/wc-1/p*
hadoop 3
java 2
mysql 1
scala 1
spark 1
word 1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号