word2vec详解
原理
word2vec的大概思想是,认为,距离越近的词,相关性就越高,越能够表征这个词。所以,只需要把所有的条件概率\(P(w_{t+j}|w_t)\)最大化,这样就能够得到一个很好的用来表征词语之间关系的模型了。
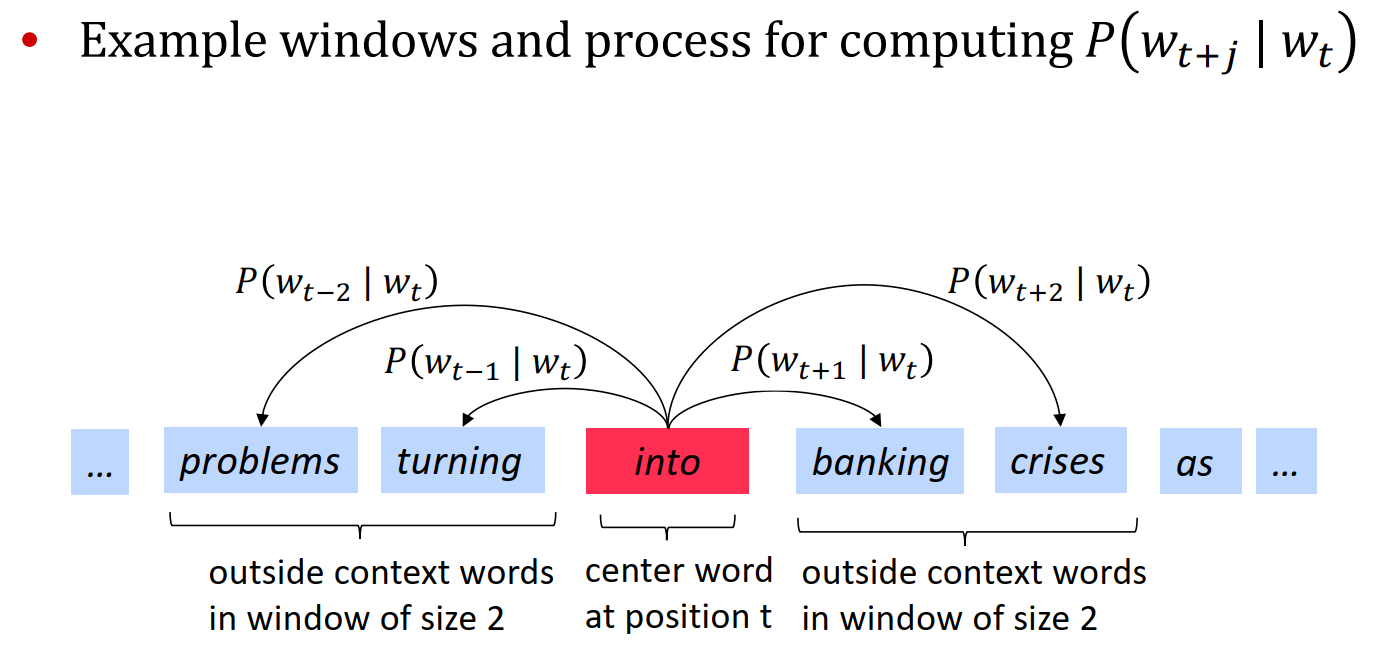
最大化的方法就是使用最大似然估计,构建损失函数,然后使用梯度下降进行优化就可以了。
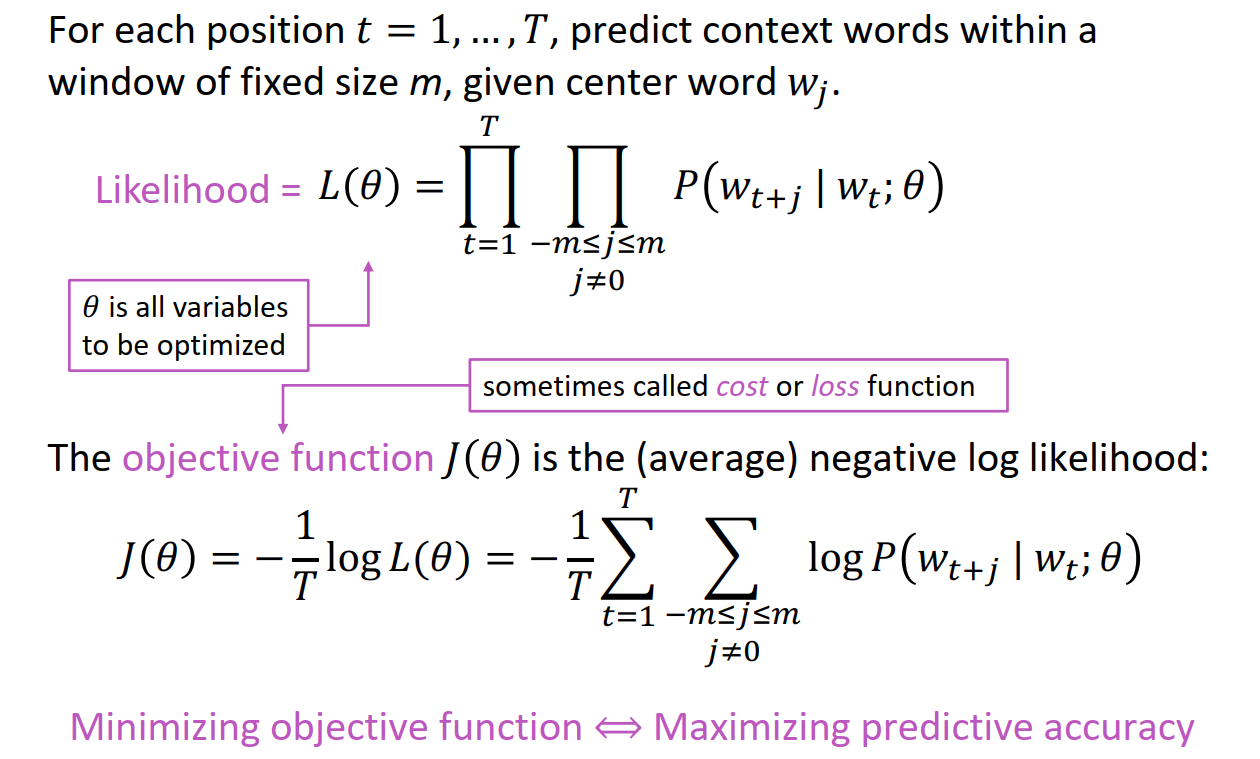
而这里的核心问题就是,如何去用参数表征这个条件概率,也就是说,如何计算p(wt+j | wt ; θ),下面是计算的方式,这里使用了两个参数 u 和v ,两个都代表莫一个词的表征,只不过含义不一样,u代表这个词作为context word来计算的时候,使用的表征,v代表这个词作为中心词计算的时候,使用的表征。

这里可以用点积来比较相似度,点积越大,越相似,就是让临近的单词相似度变高,然后在进行归一化操作,因为概率值必须在0-1之间,本质上理解就是,使用点积建模相似度,越相似的词,点积越大,最终的概率就越大。

Skip-gram & CBOW
首先,这里面的u和v是用Embedding进行编码的,一般是300维度,然后这300维度的向量在做softmax操作,最后在做优化,而优化的时候有两种算方法
第一种是skip-gram,这个就是上面提到的,使用中间词预测周边词,计算方法和上面一致
embed_o = self.embedding(index_0)
embed_v = self.embedding(index_v)
第二种是CBOW,这个不同的是,使用两边的词,预测中间的词,这里计算的时候就会出现差异,这个时候应该如何计算softmax, 首先假设周边词为w1 w2 w3 w4
这个时候需要对周边词进行平均操作,在求softmax
embed_v_list = self.embedding(w1,w2,w3,w4)
embed_v_mean = mean(embed_v_list)
embed_o = self.embedding(index_o)
负采样
可以发现,在上面计算softmax的时候,要对所有的词进行计算,这样要耗费巨大的算力,而且实际上很多词根本就不可能一起出现,所以就出现了称为负采样的策略。
所以换了一种策略,这里直接使用sigmoid来建模条件概率,首先,让相关的两个词概率变大,然后随机选取一些词(K个词),作者默认这些词与要计算的词不相关,这个时候,在点积前加上一个负号,约束让概率变小。所以最终的损失函数就改造为了:
评估
对词向量好坏的评价方法,分为内部和外部两种。
-
内部主要是计算词相似度,这个通过t-sne降维可视化,就可以直观的观察到。
-
外部是指通过一些任务,例如翻译,命名体识别等各种任务,可以用来评估词向量的效果。
使用gensim训练词向量
可以参考:https://www.kaggle.com/pierremegret/gensim-word2vec-tutorial
首先是对要训练的文本进行分词处理,英文可以使用NLTK,中文可以直接使用jieba,分完词之后,需要将其放入到一个list中,例如
[["苹果","很","好吃"],["香蕉","也","好吃"]]
之后就可以直接喂入到genism中进行训练了
from gensim.models import Word2Vec
model = Word2Vec(min_count=20,
sg=1
window=2,
size=300,
sample=6e-5,
alpha=0.03,
min_alpha=0.0007,
negative=20,
workers=cores-1)
t = time()
model.train(sentences, total_examples=model.corpus_count, epochs=30, report_delay=1)
print('Time to train the model: {} mins'.format(round((time() - t) / 60, 2)))
参数:
min_count: 频率小于min_cout的词,会被过滤掉,默认为5
window:预测窗口的尺寸
size:词向量的维度
sample: 阈值,决定多高频率的词语会被随机的下采样,更高频率的词被随机下采样到所设置的阈值,默认值为1e-3。
sg: 训练模式,1: skip-gram; 0: CBOW
alpha: 初始学习率
min_alpha: 最小的学习率
negative:如果>0, 会使用负采样算法,可以设置有多少词被负采样,一般为5-20
worker: 使用多少核心进行计算
使用训练好的模型:
model.save(fname) # 保存
model = Word2Vec.load(fname) # 加载
model.similarity("苹果","香蕉") #计算相似度
model.most_similar(positive=['母亲','皇帝'],negative=['父亲']) #计算相对距离
# '皇后'
#读取词向量
model['computer']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号