Pytorch系列:(五)CNN
卷积
Conv2d
2D卷积函数和参数如下
nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros'
)
参数说明:
in_channels: 输入通道数,RGB图片一般是3
out_channels: 输出通道,也可以理解为kernel的数量
kernel_size:kernel的和宽设置
kernel 输出尺寸计算:
\(\lfloor(n_h -k_h+p_h)/s_h+1\rfloor *\lfloor(n_w -k_w+p_w)/s_w+1\rfloor\)
stride:kernel移动的步伐
padding:在四周加入padding的数量,默认补0
dilation:
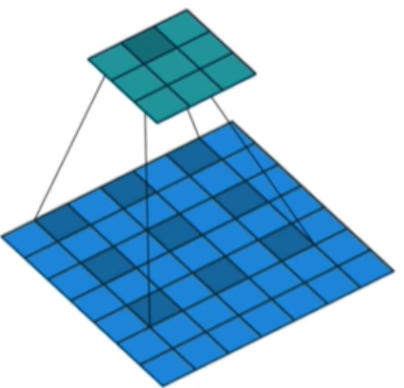
空洞就是计算的时候,对输入层进行挖空操作,如下图所示(图片来源于网络)
group:
分组计算,输出的feature map数量还是一样,只不过,每一个输出feature map 并不是用所有的输入feature map 计算的,而是分组计算,这样可以并行化并且减少计算成本
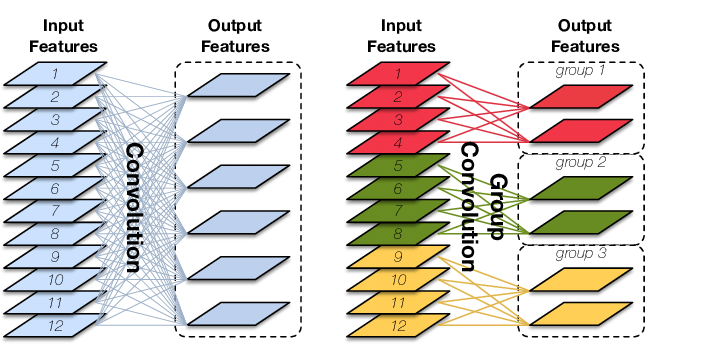
假设输入为12个feature map , 输出为6个通道,常规卷积Conv参数\(6*12*k^2\),但是假设goup=3,那么参数为 3个 \(2*4*k^2\),这是因为计算的时候,输入的feature map 和 计算的kernel 都要分成3组(如下图所示,图片来源网络)。

bias: 如果bias=True,添加偏置
Conv1d
一维卷积的特点是,卷积核有一个维度和特征的维度是保持一致的,卷积核的另外一个维度是作用在sequenc length上面。
Conv1d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True
)
in_channels: – 输入信号的通道。即为词向量的维度。2维RGB图像卷积中,为3, 一般用在序列模型中,例如一句话中的单词表征为300,那么输入就设置为300
out_channels: 输出多少个channel
kernel_size:设置卷积尺寸,其中一个维度为in_channels,所以实际上卷积大小为kernel_size*in_channels
stride:卷积步长,作用在sequence len上面
padding:在序列两边补0
dilation:卷积核元素之间的间距,同上面conv2d
groups: 同上面conv2d
bias: 如果bias=True,添加偏置
尺寸计算方法
假设输入尺寸为 (batch, sequence len, feature_len) 需要将维度转换为( batch , feature_len, sequence len),卷积核的尺寸为(feature_len, kernel_size) , 输出为( batch, kernel_size, Lout) ,其中Lout的计算方法如下:
\(L_{out} = \lfloor(feature\_len -k_h+p_h)/s_h+1\rfloor\)
转置卷积
反卷积(转置卷积)和正常卷积相反,具有尺寸扩张作用,也可以理解为带参数学习的上采样功能,主要可以用到GAN中的。
转置卷积的操作如下图所示:
相当于将被卷积的2*2 feature map进行padding,之后再做卷积操作。
设卷积核大小为k*k,输入为方形矩阵
-
对输入进行四边补零,单边补零的数量为k-1
-
将卷积核旋转180°,在新的输入上进行直接卷积 (上下翻转,左右翻转)
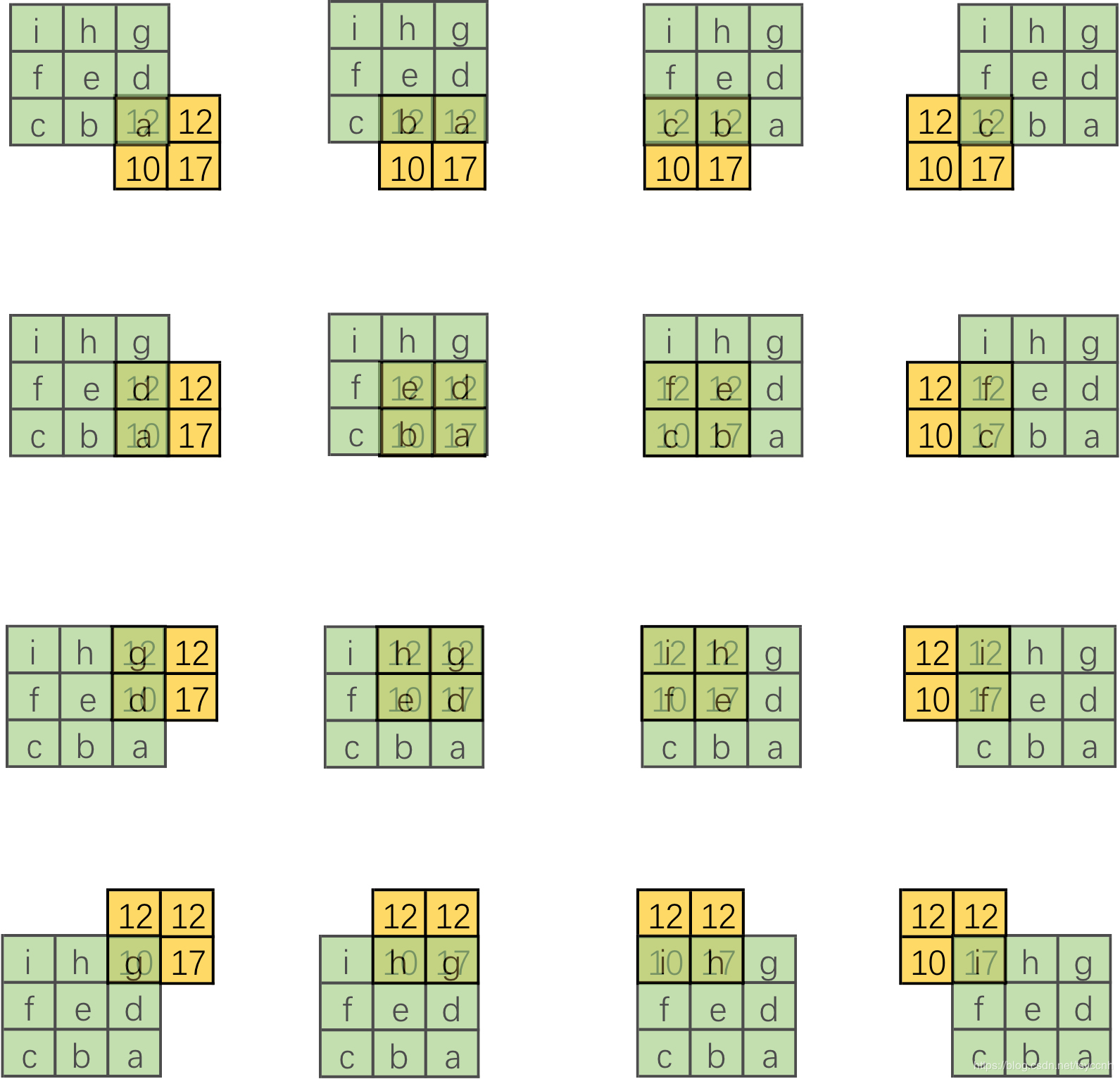
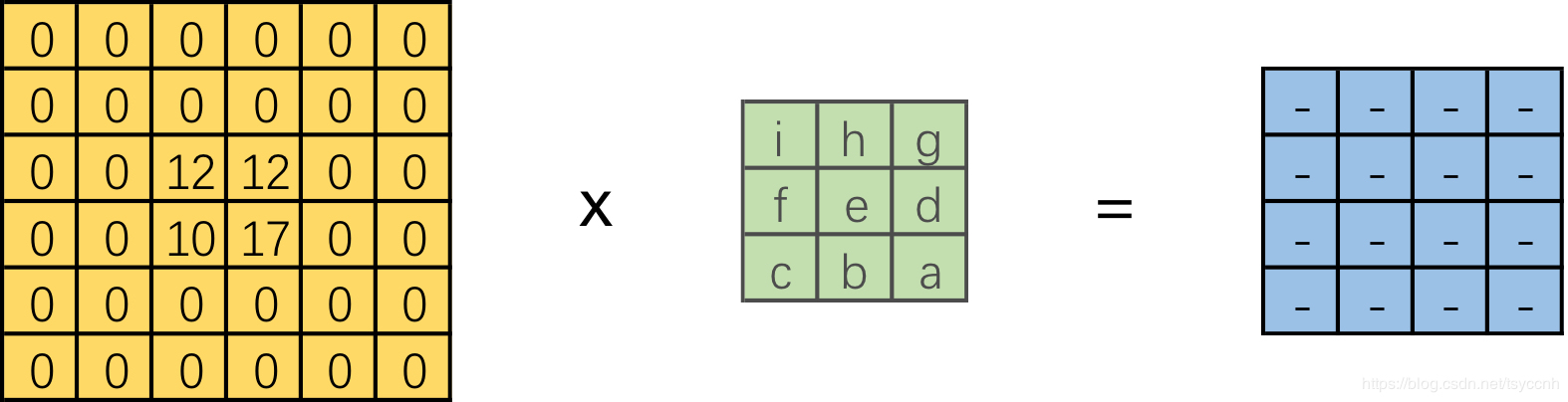
在pytorch中转置卷积函数如下,其中参数和传统卷积基本一致
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
output_padding=0,
groups=1,
bias=True,
dilation=1,
padding_mode='zeros'
)
尺寸计算方法
简化版
\(out = (in\_{channel}-1) * stride + kernel\_size\)
完整版
\(out = (in\_{channel}-1) * stride -2*padding_size + dilation * (kernel\_size-1)+output\_padding +1\)
推荐一个细致讲解转置卷积的帖子:https://blog.csdn.net/tsyccnh/article/details/87357447
池化函数
nn.MaxPool2d
nn.MaxPool2d(
kernel_size,
stride=None,
padding=0,
dilation=1,
return_indices=False,
ceil_mode=False
)
其中,
return_indices: 可以返回池化的位置,主要用于自编码其中池化上采样(最大池化)
ceil_mode: 表示尺寸向上取整,主要用于kernel_size无法被长宽整除的时候。
其他参数和上述卷积参数含义一样。
主要功能是进行特征缩减,同时保留最大信息,2*2的MaxPoold执行操作如下图所示(来源于cs231n )
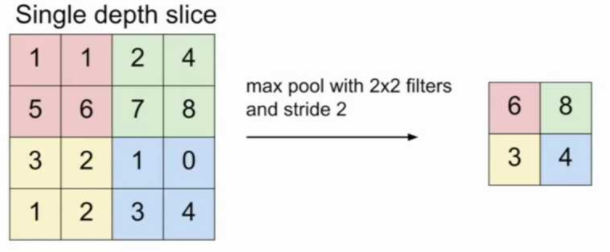
pytorch中的pooling函数,默认kernel size和stride是一样的
pool2d = nn.MaxPool2d(3) # 这里省略stride设置 pool2d(X)
# 也可以手动设置更详细的:
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
nn.AvgPool2d
nn.AvgPool2d(
kernel_size,
stride=None,
padding=0,
ceil_mode=False,
count_include_pad=True,
divisor_override=None
)
其中:
count_include_pad:求平均值的时候,是否考虑将padding加入计算,divisor_override:可以设置分母,例如2*2均值就是除以4,但是我们可以设置其他值
其他参数和上述nn.MaxPool2d含义一样
主要操作和nn.MaxPool2d一样,不同的是,这里做的是求平均操作。
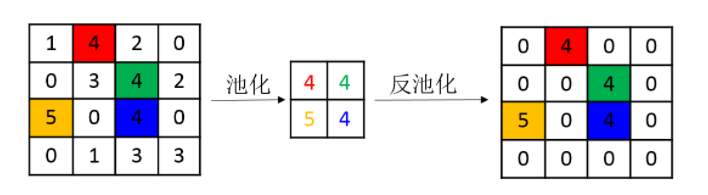
nn.MaxUnpool2d
反池化操作,就是池化的反向操作,具体如下图所示(图片来源网络):
nn.MaxUnpool2d(
kernel_size,
stride=None,
padding=0
)
一个例子,首先使用MaxPool2d采样,然后保留采样位置,最后使用采样位置indices来进行反池化操作。
img = torch.randn((28,28))
max_pool_l = nn.MaxPool2d((2,2),stride=(2,2),return_indices=True)
img_pool,indices = max_pool_l(img)
maxUpPool_l = nn.MaxUnpooled((2,2),stride=(2,2))
img_Up = maxUpPool_l(input_i , indices)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号