tornado 入门篇
一、Tornado简介
目前学习的版本是:tornado4.5.0
Tornado是一个由Python开发的Web框架,它是单线程异步的非阻塞服务器,因此速度非常快。
相对一般情况下来说,如果同时连接数Django为8000个左右,那么Tornado为12000个。
二、路由
路由就是路径,一条路线。
通过IP找到服务器,通过端口找到服务。服务都会有一个路由对应一个Handler,在Handler中才执行具体业务逻辑。
比如你去一家会所,会所就是服务器。前台妹妹问你需要什么服务,你要打洞,妹妹会指引你去打洞的地方。如果你只是洗澡,妹妹会指引你去洗澡的地方。指引就是路由,一条路线,告诉你怎么走。在web开发中,路由就是指引的作用,指向一个地方,这个地方最终会是Handler。到了打洞的地方(Handler),洞要怎么打就随你发挥了。

Handler:指定请求的资源,相当于Django的视图函数。
端口:如果所有服务都用同一个端口,就像所有的汽车在同一条路开,结果就是堵死,谁都别想好过!那么就用端口去区分具体是哪个服务,你占用了一个端口,那么其他服务就靠边站,去用其他端口。不同的服务,不同的端口。你想想看,如果洗澡和打洞都在同一片天空下,打洞的打不好,洗澡的没法淡定,因此需要分开来。
web服务:正在运行的程序,可以跟别人交互。
Tornado服务:启动起来就是一个服务了。
三、万事从Hello World开始
(一).新建一个py文件,输入下面代码


import tornado.web import tornado.ioloop import tornado.options # 让模块有自定义选项 import tornado.httpserver # 启动一个单线程的http服务器 from tornado.options import define, options # 自定义端口 # help是给人看的帮助提示 define("port", default=8888, help="given your port", type=int) class MainHandler(tornado.web.RequestHandler): def get(self): self.write("Hello World!") # 路由表 application = tornado.web.Application( # s不要漏下,不然找不到路由 handlers=[ (r"/", MainHandler), ] ) if __name__ == "__main__": tornado.options.parse_command_line() # 可以通过命令行交互 python xxx.py --port=8888 http_server = tornado.httpserver.HTTPServer(application) http_server.listen(options.port) # 调用自定义端口 tornado.ioloop.IOLoop.instance().start()
在浏览器中敲入URL http://47.98.139.237:8888 就能看到打印出来的字符串Hello World
(二).get_arguments() 和 get_argument()
这两个方法都是接收从前端传过来的参数。
(1).首先看get_arguments()
直接上代码:
# 只需改动上诉代码中的MainHandler class MainHandler(tornado.web.RequestHandler): def get(self): name = self.get_arguments("name") print(name)
在浏览器中敲入URL http://47.98.139.237:8888/?name=zyb&name=budong
去后台可以看到打印结果 ['zyb', 'budong'] 是一个列表。两个重名的name都得到了
(2).get_argument()
修改一下代码:
class MainHandler(tornado.web.RequestHandler): def get(self): name = self.get_argument("name") print(name)
再在浏览器中敲入URL http://47.98.139.237:8888/?name=zyb&name=budong
后台只能看到 budong 这一个字符串。只能得到最后一个name
(3).总结
get_argument()其实是get_arguments()[-1]
(三).self.write()的机制
self.write()先把内容放在缓冲区,正常情况下,当请求处理完成的时候会自动把缓冲区的内容输出到浏览器。
可以调用self.flush()方法,这样可以直接把缓冲区的内容输出到浏览器,不用等待请求处理完成。
(四).self.write()接受的对象
self.write()只接受bytes、unicode字符和字典,这三个对象。
(1).bytes,二进制
class IndexHandler(tornado.web.RequestHandler): def get(self): self.write(b'Tornado <br>')
(2).unicode字符
python3都是用的Unicode编码
(3).字典
示例代码
class MainHandler(tornado.web.RequestHandler): def get(self): self.write("<h1>Tornado.</h1>") self.write({"name": "quanquan616", "age": 30})
在浏览器中访问这个路由,它会变成下面这个样子

先看浏览器中返回了什么:

原因:
def get(self)函数中遇到了字典,tornado会把响应类型设置成"application/json"
具体看tornado对write()函数的描述
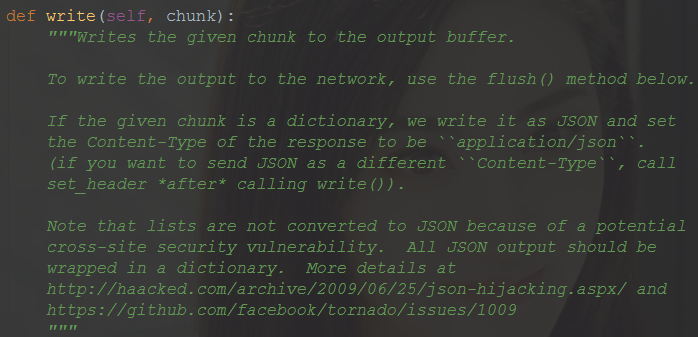
解决办法:
既然self.write()采用了缓冲区机制,那么就用上述提到的self.flush()函数来解决。
就像文件操作那样,f.write()的时候,不会往磁盘中写入数据,只有当被正常关闭或者代码全部正常执行完毕后才会把数据一次性写入磁盘中。
在文件操作中,如果想要把数据写入磁盘,可以调用f.flush()函数。
tornado的self.write()也是同理可得!调用self.flush()往浏览器中冲刷。
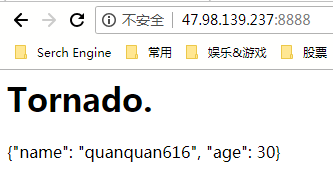
class MainHandler(tornado.web.RequestHandler): def get(self): self.write("<h1>Tornado.</h1>") self.flush() self.write({"name": "quanquan616", "age": 30})
再次访问这个路由,一起正常显示

(4).列表
self.write()只接收bytes、unicode和字典这三个对象,往它里面放列表肯定报错。
可以把列表转换为json,json它就是一个字符串,所以是可以被接收的。
注意:下面代码不规范,只是为了演示使用。
class MainHandler(tornado.web.RequestHandler): def get(self): import json self.write(json.dumps([1, 2, 3, 4, 5]))
浏览器中可以看到这个列表被打印出来了。
(三).图解

四、self.render()
同理Django的render()
(一).最简单的方式
(1).现有如下目录

(2).代码中的配置

注意:"template_path"、"static_path"、"debug",这三个键绝对不能写错!键后面的值根据实际命名的去填写。
(3).编写Handler
class MainHandler(tornado.web.RequestHandler): def get(self): self.render("lesson2.html")
(4).编写前端HTML文件
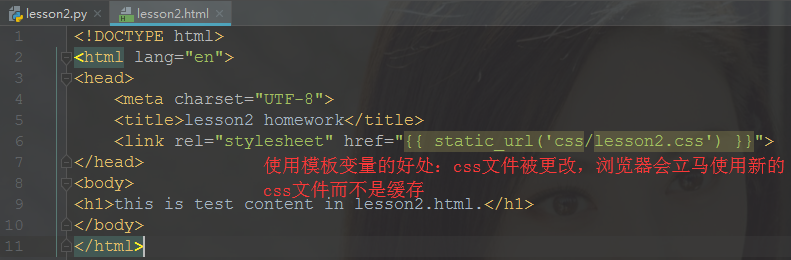
(5).在浏览器中访问根路由就可以看到这个HTML
五、跳转路由
通过redirect("/路由的名称")可以跳转到指定的路由。
例如:
class RedirectTestHanlder(tornado.web.RequestHandler): def get(self): self.redirect("/")
在浏览器中访问RedirectTestHanlder对应的路由时,会跳转到根路由所对应的Handler
六、接收输入
(一).get_argument()
它即可获取URL中的参数,也可获取body中的参数。返回的值,始终是unicode
有多个同名参数,获取的是最后一个参数,等同于:get_arguments()[-1]
(二).get_query_argument()
只能获取URL中的参数。
(三).get_body_argument()
只能获取<body>标签中的参数。
七、URL传参的两种方式
(一).查询字符串风格
(1).Handler
class GetHandler(tornado.web.RequestHandler): def get(self): name = self.get_argument('name', None)
(2).给它配置个路由
(r'/get', GetHandler)
(3).访问URL的格式:http://127.0.0.1:8000/get?name=budong
(二).REST风格
(1).Handler
class UserHandler(tornado.web.RequestHandler): def get(self, name, age): self.write('name: %s <br> age: %s' % (name, age)) class StudentHandler(tornado.web.RequestHandler): def get(self, name, number): self.write('name: %s <br> number: %s' % (name, number))
(2).配置路由
(r'/user/(.+)/([0-9]+)', UserHandler), (r'/stu/(?P<number>[0-9]+)/(?P<name>.+)', StudentHandler),
(3).访问URL的格式:
http://127.0.0.1:8000/user/budong/18
http://127.0.0.1:8000/stu/20170001/budong
八、获取请求信息
继承tornado.web.RequestHandler之后,可以直接调用self.request来获取客户端请求信息。
常用的一些属性及方法:

九、请求与响应
浏览器和服务器之间是怎么沟通的?

(一).请求信息
浏览器在发送请求的时候,会发送具体的请求信息,由请求行、请求消息头、请求正文,这三块内容构成。
(1).请求行
请求行,位于第一行。包含内容为:
Method:一般为 GET 或者 POST
Path-to-resource:请求的资源的URI
Http/Version-number:客户端使用的协议的版本,有HTTP/1.0和HTTP/1.1
(2).请求消息头
向服务器传递附加信息。包含内容为:
Accept:浏览器可以接受的MIME类型。
Accept-Charset:浏览器支持的字符集,如:gbk、utf-8
Accept-Encoding:浏览器能够解码的数据压缩方式,如:gzip
Accept-language:所希望的语言
Host:请求的主机IP和端口
User-Agent:通知服务器,浏览器类型
Content-Length:表示请求消息正文的长度
Connection:表示是否需要持久连接(Keep-alive)
Cookie:这是最重要的请求头信息之一(会话有关)
(3).请求正文
请求具体内容,比如:URL中传入的参数,form表单里面的内容等等
(4).注意
在请求与响应当中,请求是浏览器设置的,在服务器端只能接受,无法改变。只能改变响应头!
(二).响应信息
响应信息为服务器的处理结果。主要包含:响应行,响应消息头,响应正文。
(1).响应行
响应行主要报错如下信息:
Http/Version-number:服务器用的协议版本
Statuscode:响应码。代表服务器处理的结果的一种表示,常用的响应码有:200正常。302/307重定向。304服务器的资源没有被修改。404请求的资源不存在。500服务器报错了。message响应码描述,例如200的描述为OK
(2).响应消息头
Server:通知客户端,服务器的类型
Content-Encoding:响应正文的压缩编码方式。常用的是gzip
Content-Length:通知客户端响应正文的数据大小
Content-Type:通知客户端响应正文的MIME类型
Content-Disposition:通知客户端,以下载的方式打开资源
(3).响应正文
具体的响应内容,如html、JavaScript等数据内容
十、设置响应头
请求是浏览器设置的,无法改变。只能改变响应头!
(一).设置响应头set_header("key","value")
例:
class HeaderHandler(tornado.web.RequestHandler): def get(self): self.write('set_header') self.set_header('aaa', '1111') self.set_header('bbb', '2222') self.set_header('bbb', '3333')
注意:set_header()出现同名的键,后者会把前者覆盖!
(二).添加响应头add_header("key","value")
例:
class AddHandler(tornado.web.RequestHandler): def get(self): self.write('add_header') self.add_header('ccc', '3333') self.add_header('ccc', '4444')
注意:add_header()可以出现相同信息。
(三).清除指定头clear_header("key")
可以撤销给定的响应头信息
十一、发送错误码到浏览器
(一).将指定的HTTP错误码发送到浏览器send_error()
例:(也可以直接渲染自己写好的错误页面)
class SendHandler(tornado.web.RequestHandler): def get(self): self.write('send_error') # self.flush() self.send_error(404)
使用send_error()时需要注意:
(1).如果已经执行了flush(),则不能再执行send_error()。因为执行了flush(),后面的内容就不能改变了,send_error()失去了作用,同理self.write()字典。
(2).如果从来没有执行过flush()的话,代码从上往下,遇到了send_error(),那么之前的所有内容都不会交给浏览器,内容直接丢失了,只返回send_error()中指定的了。
十二、处理未定义的路由
用户输入了一个压根就不存在的路由怎么办?
(一).定义一个Handler
class NotFoundHandler(tornado.web.RequestHandler): def get(self, *args, **kwargs): self.send_error(404) def write_error(self, status_code, **kwargs): self.render('error_notfound.html')
send_error()在其底层调用的是write_error(),因此只要重写此方法,就可以实现自定义的的错误页面。
(二).把此路由放到路由表的最后面
(r'/(.*)', NotFoundHandler),
注意看这个正则的规则,匹配任意字符串,贪婪模式。如果把它放到了路由表的第一行,那么访问任何页面都是not found
十三、请求处理过程
Tornado在接受到请求之后,后按照下面的调用顺序来执行
1.设置header
2.初始化
3.准备工作
4.处理get请求
5.处理post请求
6.处理错误
7.结束,释放资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号