爬虫入门
实现爬虫的基础套路
第一步、准备url
(1).准备start_url
特点:url地址规律不明显,总数不确定。
通过代码提取下一页url的技巧:xpath;寻找url地址,部分参数在当前的响应中(比如:当前页面数和总页码数在当前的响应中)
(2).准备url_list
特点:页面总数明确,url地址规律明显
第二步、发送请求,获取响应
基础的请求响应看requests文档即可,这里写一点反反爬虫的小技巧:
1.添加随机的User-Agent
2.添加随机的代理IP
3.在对方判断出是爬虫后,添加更多的headers字段,包括cookie(cookie的处理可以使用requests提供的session对象来解决)
cookie池的逻辑:准备一堆能用的cookie,组成cookie池。
如果不用登陆,准备刚开始能够成功请求对方网站的cookie,即接收对方网站设置在response中的cookie,下次请求时随机一个cookie池中的cookie进行请求。
如果要登陆,准备多个账号,使用程序获取每个账号的cookie,随机挑选cookie进行请求。
4.当电脑端JS太难搞或得不到数据的时候,可以尝试把浏览器模式切换成手机模式或平板模式,看看有没有简化。如果还是跟电脑端浏览器一样,那只能去刚正面了。
第三步、提取数据
1.确定数据的位置
如果数据在当前的url地址中:
提取的是列表页的数据,直接请求列表页的url地址,不用进入详情页。
提取的是详情页数据:确定url,发送请求、接收响应,提取数据,返回继续下一个url
如果数据不在当前的url地址中:
数据不在当前的url地址中,说明数据在其他响应中,需要去寻找数据的位置:在浏览器开发者模式的Network中,从头到尾找;使用开发者模式的过滤条件;通过search数字、英文来定位数据。
2.数据的提取
xpath:从html中提取整块的数据,先分组,之后每一组再提取
re:提取html中的json字符串
json:把json字符串转化为python字典对象,然后再提取
爬虫代码的一些建议
一、尽量减少请求次数
1.能抓列表页就不抓详情页
2.保存获取到的html页面,供差错和重复请求时使用
二、关注网站中所有类型的页面
1.wap页面、触屏版页面
2.H5页面
3.app
三、多伪装
1.动态User-Agent
2.代理ip
3.尽量不适用cookie
四、利用多线程、分布式
在不被反爬的情况下,尽可能地提升效率
requests对比urllib
1.requests的底层实现就是urllib
2.通过urllib获取到的网页内容是没有经过解压的,需要手动去解压。而requests能自动帮我们解压(gzip压缩的等)网页内容
3.requests发送请求的时候必须带上协议,不然就会报错!
requests解决编码的办法
1.response.content.decode() python3中默认是"utf-8"
2.response.content.decode("GBK") 直接指定编码
3.response.text 通过请求头里的信息去推测编码
response.text与response.content的区别
首先,requests得到的响应要么是bytes类型要么是str类型。
1.response.text
类型:str
解码类型:根据HTTP头部,对响应的编码作出有根据的推测,推测的文本编码
修改编码方式:response.encoding="utf-8"
2.response.content
类型:bytes
解码类型:没有指定
修改编码方式:response.content.decode() python3中默认是"utf-8"
技巧:
如果得到一个json对象,一大堆内容挤在一起狠起来很费力,如何解决?
1.json在线解析工具:https://www.json.cn/
2.在pycharm中新建一个json文件,把json字符串丢进去,然后格式化一下就好看很多了
中文被解析成了unicode字符,可以把这些字符放进ipython中,回车一下就能得到原始版的中文了。
常用的头信息
带上headers的目的:模拟浏览器,欺骗服务器,获取和浏览器一致的内容。
User-Agent:浏览器名称,注意大小写
response.headers:响应头,返回一个dict。需要关注一下"Set-Cookie"这个信息,它是服务器返回给本地后设置的。(JS也可以设置cookie)
response.request.headers:请求的头,也是返回一个dict
发送带参数的请求
需要用到requests.get()中的params参数,这个参数是一个dict类型:kw={key:value}
语法:requests.get(url,params=kw)
带参数的get请求是在url后面加一个问号(?)然后键值对之间以"&"符号隔开,每个键值对通过等号(=)相互关联。
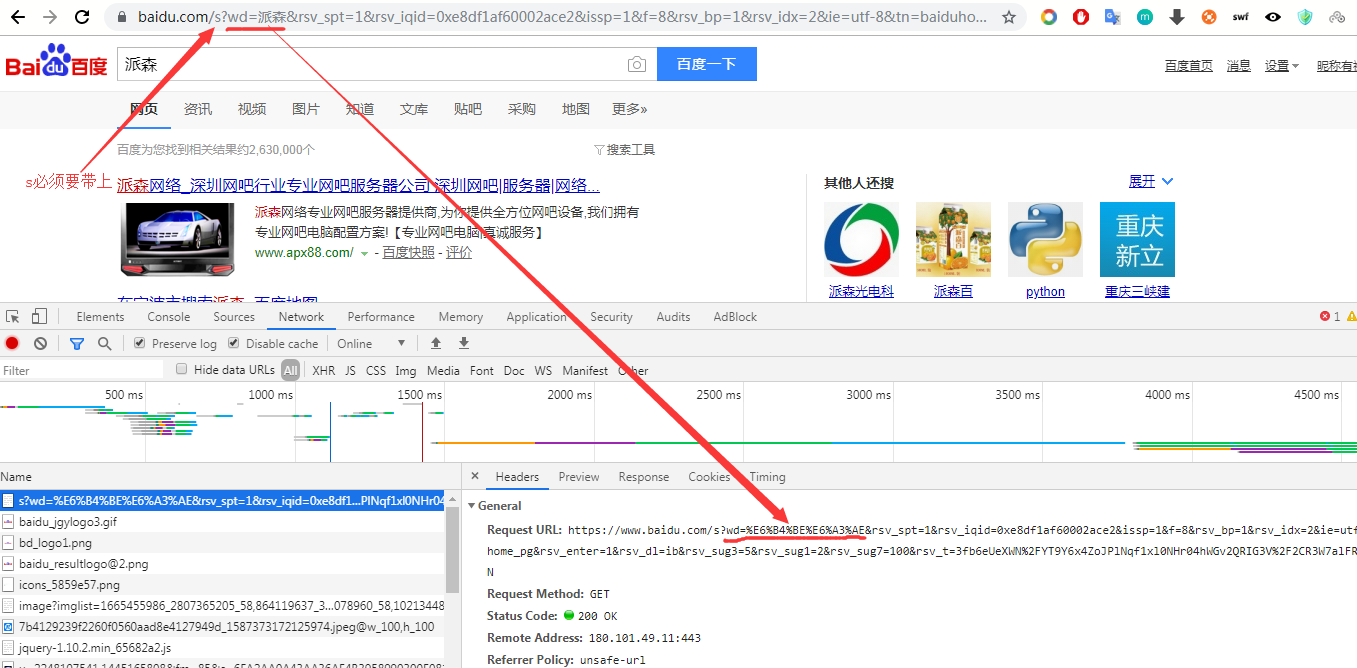
上图中的这个小写"s"是必须带的,不然的话:

当requests执行带参数的get请求时,其实是在地址栏后面做拼接操作。在requests中,get的问号可写可不写。而且,可以不用写params参数,直接写进url也可以,但直接写的时候就必须把问号带上了。如下例所示:
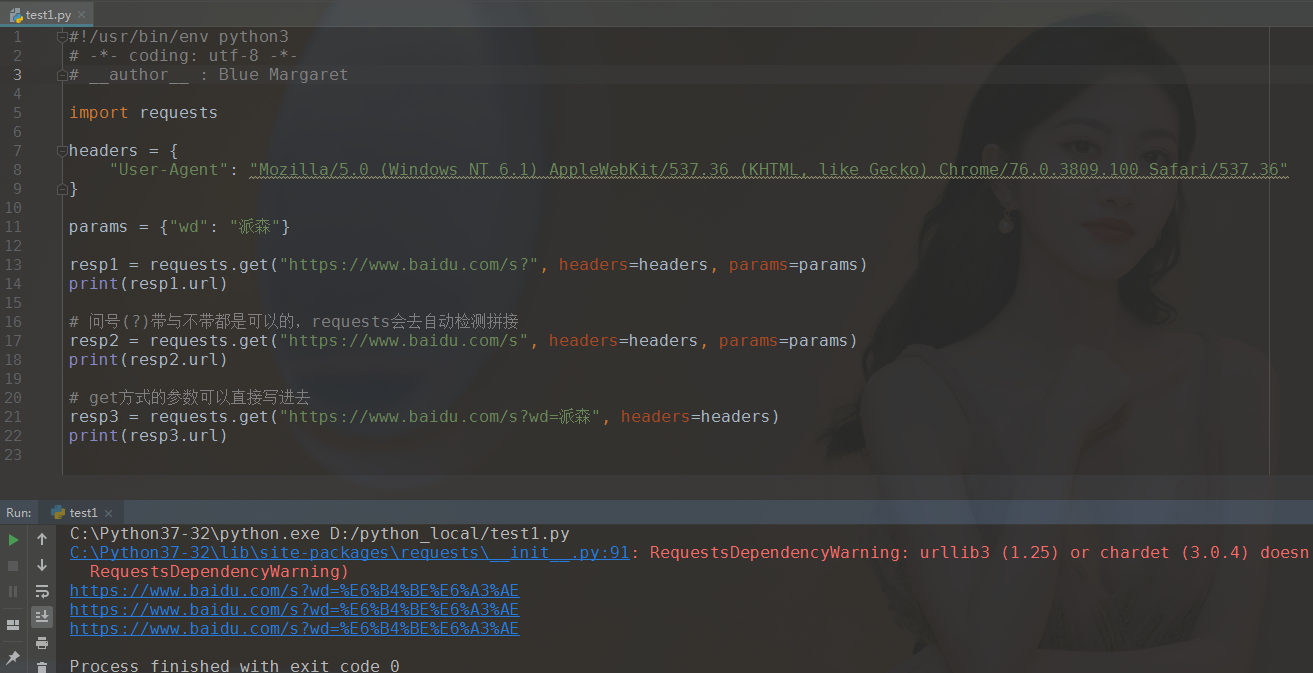


import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36" } params = {"wd": "派森"} resp1 = requests.get("https://www.baidu.com/s?", headers=headers, params=params) print(resp1.url) # 问号(?)带与不带都是可以的,requests会去自动检测拼接 resp2 = requests.get("https://www.baidu.com/s", headers=headers, params=params) print(resp2.url) # get方式的参数可以直接写进去 resp3 = requests.get("https://www.baidu.com/s?wd=派森", headers=headers) print(resp3.url)
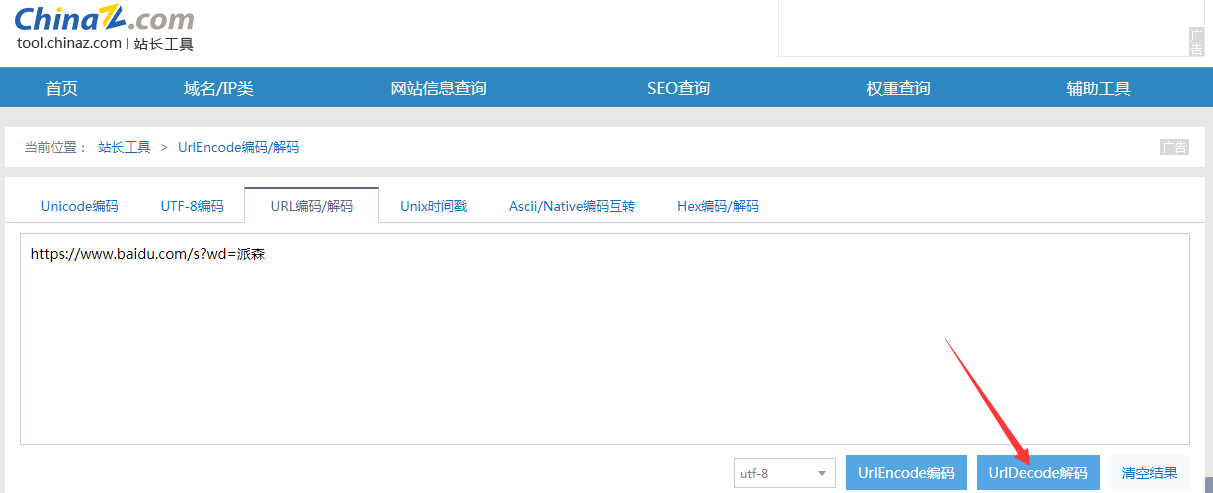
注意一点:想要看中文的URL内容,需要去URL解码网站将url解码一下,不然就会看到一大串百分号开头的内容。
URL解码网站:https://tool.chinaz.com/tools/urlencode.aspx
例如:我在百度输入了关键词"派森",把前面部分的wd复制过来,去URL解码网站解一下才能看到真正的内容。
技巧:
1.遇到很长很长的URL地址,可以试着去删掉一些参数,写个小爬爬往往犯不着模拟得那么像。
比如我在百度上输入"派森"这关键词,回车后,URL变成了这么一大串:https://www.baidu.com/s?wd=%E6%B4%BE%E6%A3%AE&rsv_spt=1&rsv_iqid=0xe8df1af60002ace2&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=ib&rsv_sug3=5&rsv_sug1=2&rsv_sug7=100&rsv_t=3fb6eUeXWN%2FYT9Y6x4ZoJPlNqf1xl0NHr04hWGv2QRIG3V%2F2CR3W7alFRVZka9k9Zh0N
一大串我也看不懂是什么意思,也不知道是怎么生成的,其实只是前面的wd才是最关键的内容。但如果要模拟得很像很像,那么最好是把全部的参数都破译出来,然后带上去发送请求。
爬虫代理
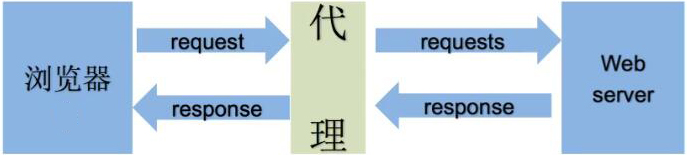
代理相当于中间人,为什么要使用代理?
1.让服务器认为不是同一个客户端在请求
2.防止自己的真实地址被泄漏
目的:假装是不同的用户在访问。
反向代理:例如nginx,它的原理是将请求转发给内部服务,你并不知道最终的服务器地址。相对安全,因为你只能知道nginx地址,而最终跑服务的server是不知道的。你也只能把nginx干掉,而很难干掉最终的server
正向代理:例如vpn,你是知道最终服务器地址是哪里。
判断方式:是否知道最终的服务器地址。
另外,透明和普通匿名容易被对方抓到你的真实IP,高匿就不太容易被怼。
requests中使用代理
给proxies参数传递一个字段
准备一大堆的IP,组成IP池,并设定随机选择的策略(比如通过排序,选择使用次数较少的IP地址优先去代理),然后随机选择一个进行访问。
检查IP的可用性:
1.超时参数设置(例如,设置3秒内必须响应,不然就报错)
2.使用代理IP质量检测网站
代理的工作方式
cookie和session
cookie:保存在本地,单个cookie不能超过4K,很多浏览器会限制一个站点最多只能保存20个cookie
session:保存在服务器中,会在服务器中存在一定时间,多了会影响服务器性能
cookie池:一套cookie和session往往跟一个用户对应,请求太快、次数太多,容易被识别为爬虫。解决方案:准备一大堆cookie,组成cookie池,选择使用次数较少的cookie去请求。
友情提示:不需要cookie的时候尽量不去使用cookie
requests的cookies参数也是一个字典类型:cookies={"key":"value"}
不带cookie也能直接登录的三种情况:
1.cookie过期时间很长的网站。2.cookie过期之前就拿到想要的数据。3.配合其他程序,一个程序专门去获取cookie然后传给当前程序,当前程序直接拿来使用
requests的会话保持
使用requests提供的Session类(注意:实例化后不是上面cookie和session的那个session,而是requests提供的会话保持对象),会自动帮我们把网站的cookie保持住。
用法:session = requests.Session()
lxml库
lxml是python的第三方库,可以自动修正html代码,需要额外安装:pip install lxml
导入lxml的etree模块:from lxml import etree
利用etree.HTML(),可以将字符串转化为Element对象
Element对象具有xpath()方法:html=etree.HTML(html_str)
验证码的识别
云打码平台:http://www.yundama.com/
1.url不变,验证码不变
直接请求验证码的url,获得响应,进行识别
2.url不变,验证码会变
思路:对方服务器返回验证码的时候,会和每个用户的信息和验证码进行一一对应,之后在用户发送post请求时,会对比post请求中的验证码和当前用户真正存储在服务器端的验证码是否相等。
步骤:
(1).实例化requests.Session()
(2).使用session请求登录页面,获取验证码的url
(3).使用session请求验证码url的响应,这个响应就是一张验证码图片对象(一般是response.content的bytes对象)
(4).把上面的bytes对象丢给打码平台去识别
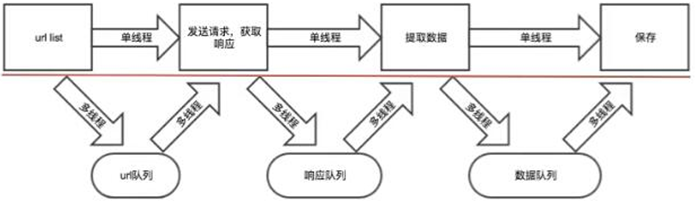
多线程爬虫
动态HTML技术了解
Selenium和PhantomJS
selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的。selenium可以直接运行在浏览器上,它支持主流的浏览器(包括PhantomJS这些无界面的浏览器)。selenium可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至网页截屏。
phantomjs是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的Javascript
selenium所需的chrome驱动下载(国内镜像):https://npm.taobao.org/mirrors/chromedriver
阿里云的其他镜像:https://npm.taobao.org/
selenium基本操作

页面元素定位

selenium中cookie的常用用法
1.driver.get_cookies()
2.{cookie["name"]:cookie["value"] for cookie in driver.get_cookies()}
3.driver.delete_cookie("cookie_name")
4.driver.delete_all_cookies()
页面等待
当网页采用了动态html技术,页面上部分元素的出现时间便不能确定,这个时候可以设置一个等待时间,强制要求在一定的时间内出现,否则就报错。
1.强制等待
time.sleep(10)
2.显示等待
设置最长的等待时间,去等待指定的某个条件。如果在这个时间内还是没有找到元素,就会抛出异常。
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "myDynamicElement")))
3.隐式等待
简单地设置一个最大等待的时间,单位为秒
driver.implicitly_wait(10)
4.针对三种等待方式的建议
尽量使用第一种强制等待方式,显示和隐式等待经过前辈的实践,反应并不好用。
selenium使用的注意点
(1).获取文本和获取属性
先定位到元素,然后调用.text或者get_attribute()方法
(2).selenium获取的页面数据是浏览器中elements内容
(3).find_element和find_elements的区别
find_element返回一个element对象,如果没有会报错
find_elements返回一个列表,没有就是空列表
小技巧:在判断是否有下一页的时候,使用find_elements获取一下列表,如果列表为空,则表明没有下一页了。
(4).如果页面中有iframe、frame,需要先调用driver.switch_to_frame()方法,切换到该frame中才能定位元素
(5).selenium请求下一个页面时,下一个页面未必会立马加载出所有的数据,如果此时去获取一个还未加载出来的数据,就会报错。可以强制等待一定时间:time.sleep(5)
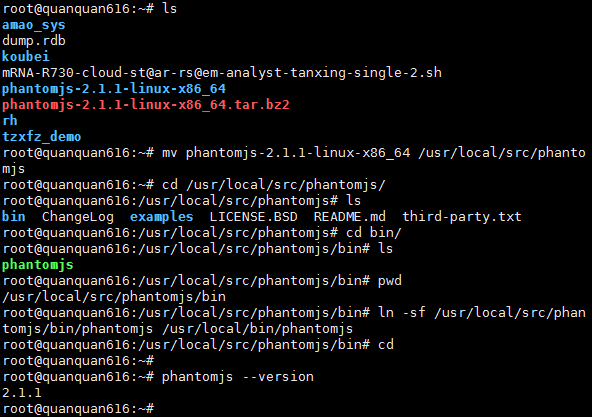
Ubuntu Server 18.04.2 LTS下的PhantomJS安装
不建议使用apt,可能会报错装不上。去官网下载,解压后即可使用:https://phantomjs.org/download.html
本人偷懒直接用了root权限,如果是其他用户则需要sudo提权
# 解压 tar -xvf phantomjs-2.1.1-linux-x86_64.tar.bz2 # 解压开后,找到bin目录中的可执行文件,就直接可以使用 # 为了避免误删,建议把文件夹移动到一个合适的位置 mv phantomjs-2.1.1-linux-x86_64 /usr/local/src/phantomjs # 创建软链 ln -sf /usr/local/src/phantomjs/bin/phantomjs /usr/local/bin/phantomjs # 如能正确输出版本号,则表示可用 phantomjs --version
Tesseract
定义:Tesseract是一个将图像翻译成文字的OCR库(光学文字识别,Optical Character Recognition)
安装:apt install tesseract-ocr
在python中调用tesseract:pip install pytesseract
Tesseract处理规范的文字
tesseract-oct是光学文字识别,它的原理是根据图片上的颜色色差的变化去判别是否为文字。
在终端的处理:tesseract test.jpg text
在python代码中使用
1.好图片的识别结果:

from PIL import Image import pytesseract # 在windows7环境下,必须指定tesseract的路径,不然就会报错 """ 报错信息: Traceback (most recent call last): File "C:\Python37-32\lib\site-packages\pytesseract\pytesseract.py", line 223, in run_tesseract proc = subprocess.Popen(cmd_args, **subprocess_args()) File "C:\Python37-32\lib\subprocess.py", line 756, in __init__ restore_signals, start_new_session) File "C:\Python37-32\lib\subprocess.py", line 1155, in _execute_child startupinfo) FileNotFoundError: [WinError 2] 系统找不到指定的文件。 During handling of the above exception, another exception occurred: Traceback (most recent call last): File "D:/python_local/pytesseract_example/demo2.py", line 9, in <module> pytesseract.image_to_string(image) File "C:\Python37-32\lib\site-packages\pytesseract\pytesseract.py", line 345, in image_to_string }[output_type]() File "C:\Python37-32\lib\site-packages\pytesseract\pytesseract.py", line 344, in <lambda> Output.STRING: lambda: run_and_get_output(*args), File "C:\Python37-32\lib\site-packages\pytesseract\pytesseract.py", line 253, in run_and_get_output run_tesseract(**kwargs) File "C:\Python37-32\lib\site-packages\pytesseract\pytesseract.py", line 225, in run_tesseract raise TesseractNotFoundError() pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your path """ pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe" tessdata_dir_config = '--tessdata-dir "C:\\Program Files\\Tesseract-OCR\\tessdata"' print(pytesseract.image_to_string(Image.open("good.jpg"), config=tessdata_dir_config))
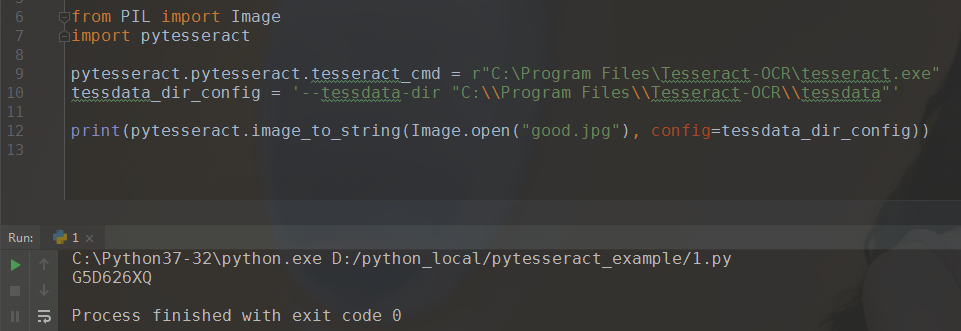
完全符合预期,一个字都没有错。
2.当图片存在有干扰元素的时候

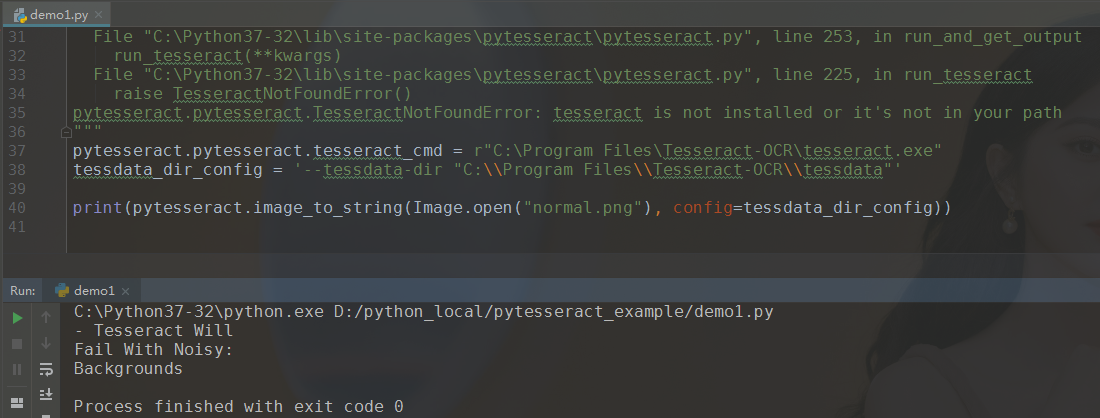
有了一些干扰元素后,这个玩意儿就不那么准确了。
其他的技巧
1.with open()报编码错误的时候,在open()函数里指定一下对应的encoding属性即可。例:with open("path/", "w", encoding="utf-8")
2.requests.utils.dict_from_cookiejar,把cookie的json对象转化为字典。response.cookies返回的是<RequestJar对象>
3.requests.utils.unquote("被编码后的url地址"),如果一个url地址里有中文,浏览器会将中文编码成一串以百分号开头的字符串,使用这个方法可以把被编码的url转化成人眼能看懂的内容。注意:这个方法只能解码URL地址
4.requests.utils.quote("url地址"),把一个url地址进行编码
5.requests.get("url", verify=False),不去验证证书。https的网站需要去权威机构购买SSL证书验证,有些网站没有去买,所以当去访问这些网站的时候会返回错误。使用这个属性,便可以避开这个问题
6.requests.get("url", timeout:int=seconds),超时指定的秒数后报错

 浙公网安备 33010602011771号
浙公网安备 33010602011771号