每日一练(二十六)
1.1 sqlite 命令行
sqlite命令行中可以识别两种命令:
- sqlite的系统命令,以点 . 开头
- SQL语句,通过SQL语句实现创建、查找、插入、更新、删除等操作,以分号 ; 结尾
在命令行打开sqlite之后输入.help来产看sqlite支持的命令,如下:
gq@server:~/learn/sqlite3$ sqlite
SQLite version 2.8.17
Enter ".help" for instructions
sqlite> .help
.databases List names and files of attached databases
.dump ?TABLE? ... Dump the database in a text format
.echo ON|OFF Turn command echo on or off
.exit Exit this program
.explain ON|OFF Turn output mode suitable for EXPLAIN on or off.
.header(s) ON|OFF Turn display of headers on or off
.help Show this message
.indices TABLE Show names of all indices on TABLE
.mode MODE Set mode to one of "line(s)", "column(s)",
"insert", "list", or "html"
.mode insert TABLE Generate SQL insert statements for TABLE
.nullvalue STRING Print STRING instead of nothing for NULL data
.output FILENAME Send output to FILENAME
.output stdout Send output to the screen
.prompt MAIN CONTINUE Replace the standard prompts
.quit Exit this program
.read FILENAME Execute SQL in FILENAME
.schema ?TABLE? Show the CREATE statements
.separator STRING Change separator string for "list" mode
.show Show the current values for various settings
.tables ?PATTERN? List names of tables matching a pattern
.timeout MS Try opening locked tables for MS milliseconds
.width NUM NUM ... Set column widths for "column" mode
可以通过敲你所用系统的文件结束符(通常是Ctrl + D)或者中断字符(通常是Ctrl + C)。来终止sqlite3程序。确定你在每个SQL语句结束敲入分号!sqlite3程序通过查找分号来决定一个SQL语句的结束。如果你省略分 号,sqlite3将给你一个连续的命令提示符并等你给当前的SQL命令添加更多的文字。这个特点让你输入多行的多个SQL语句.
SQL语句可以参考:SQL命令操作
常用的SQL语句如下:
sql语句, 都以‘;’结尾
1-- 创建一张表
create table stuinfo(id integer, name text, age integer, score float);
在创建的时候显示数据名称,然后是数据类型
2-- 插入一条记录
insert into stuinfo values(1001, 'zhangshangngsan', 18, 80);
insert into stuinfo (id, name, score) values(1002, 'lisi', 90);
可以按照全部元素的顺序插入,也可以指定元素插入
插入多条的时候直接在后面加上即可
3-- 查看数据库记录
也可以 .schema 来查看表结构
select * from stuinfo;
select * from stuinfo where score = 80;
select * from stuinfo where score = 80 and name= 'zhangsan';
select * from stuinfo where score = 80 or name='wangwu';
select name,score from stuinfo; 查询指定的字段
select * from stuinfo where score >= 85 and score < 90;
可以按照某一条件查询数据,也可以使用and、or来表示查询的范围,或者是给定一个范围进行查找
4-- 删除一条记录
delete from stuinfo where id=1003 and name='zhangsan';
先根据数据信息来找到指定记录,然后再删除
5-- 更新一条记录(这里没有table,直接使用表名字)
update stuinfo set age=20 where id=1003;
update stuinfo set age=30, score = 82 where id=1003;
同样是根据where的内容找到记录,然后通过set规定记录中的新值
6-- 删除一张表
drop table stuinfo;
7-- 增加一列
alter table stuinfo add column sex char;
8-- 删除一列
create table stu as select id, name, score from stuinfo;
drop table stuinfo;
alter table stu rename to stuinfo;
Sqlite中是不允许删除列字段的,所以可以通过复制其余字段来实现删除指定字段
9-- 删除一行
delete from stuinfo where id=1;
1.2 sqlite设置自增字段
首先要有一个概念:
PRIMARY KEY 约束唯一标识数据库表中的每条记录。主键必须包含唯一的值。主键列不能包含 NULL 值。每个表都应该有一个主键,并且每个表只能有一个主键。
然后,自增字段使用autoincrement
关键字 AUTOINCREMENT 的使用,必须满足以下两点:
1、只能用于整型(INTEGER)字段,INT类型是不可以;
2、只能用于PRIMARY KEY字段;
所以自增字段的声明组合就是:integer primary key
参考链接:https://blog.csdn.net/zhangxiaonanwin/article/details/6086117?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.control
所以,自增字段是由integer primary key来声明的,如示:

1.3 C/C++ 输出当前日期时间
在程序中输出当前的日期时间
#define BUFLEN 255
#include<stdio.h>
#include<time.h>
int main()
{
time_t t = time( 0 );
char tmpBuf[BUFLEN];
strftime(tmpBuf, BUFLEN, "%Y-%m-%d %H:%M:%S", localtime(&t));
printf("time is [%s]",tmpBuf);
return 0;
}
1.4 SQLite的C接口
如果第一次直接在命令行安装sqlite3,是不包含sqlite3.h这个包的,我们需要单独下载sqlite3支持的库,即通过命令行:
sudo apt install libsqlite3-dev
如果我们不知道该安装什么包来提供sqlite3的C/C++接口,可以通过debian官网通过查询软件包关键词可以知道库是依赖libsqlite3-dev包的:
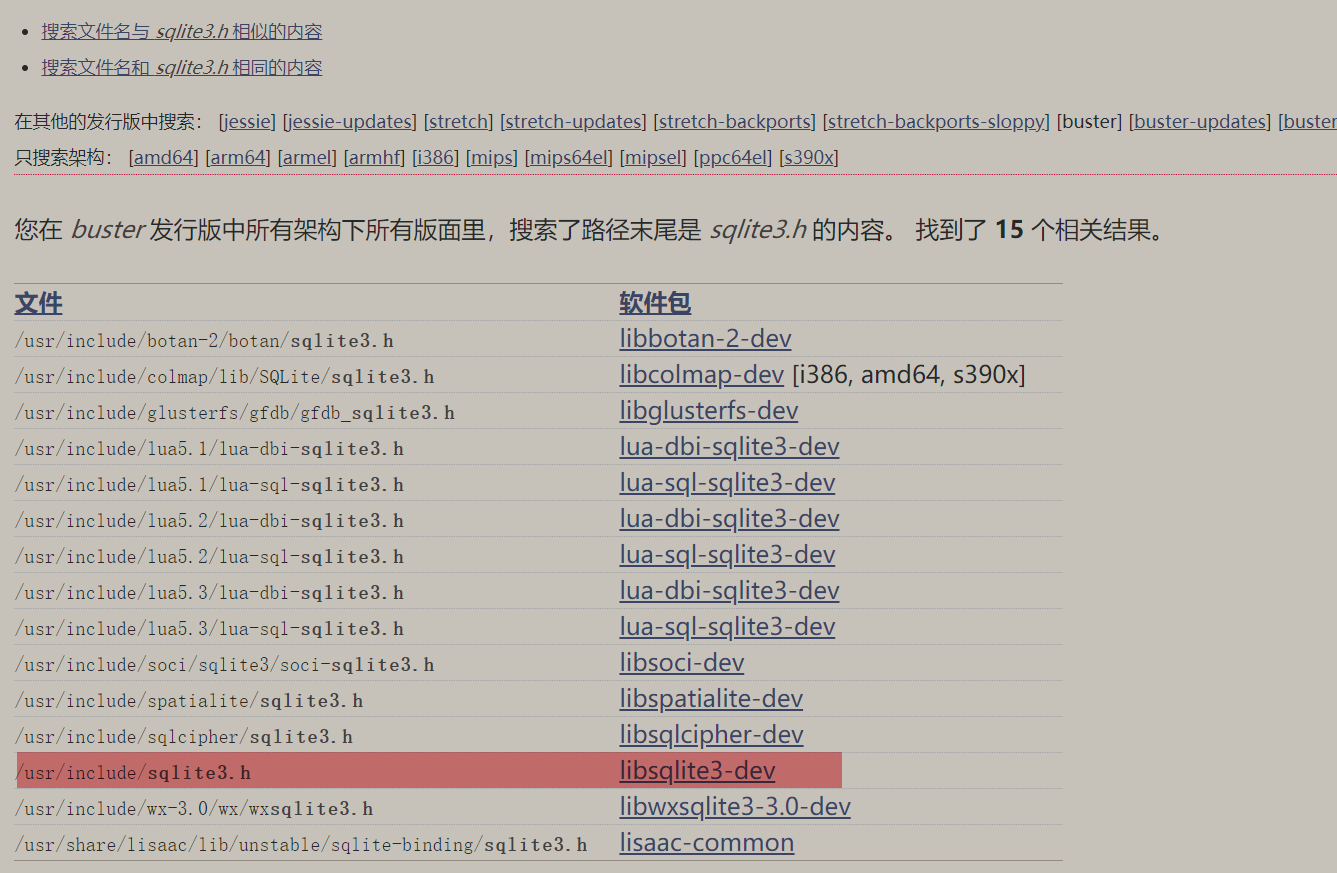
注意,链接的时候要加上-lsqlite3表示依赖第三方库
关于创建一个数据库,可以通过create table stu (id integer, name text),但是如果连续创建的话会报错,因为已经存在了,所以我们可以使用create table if not exists stu (id integer, name text)来防止重复创建报错。
可以通过句柄来获取错误消息
重要接口
以下是重要的 C&C++ / SQLite 接口程序,基本可以您在 C/C++ 程序中使用 SQLite 数据库的需求。
| 序号 | API & 描述 |
|---|---|
| 1 | *sqlite3_open(const char *filename, sqlite3 *ppDb) 该例程打开一个指向 SQLite 数据库文件的连接,返回一个用于其他 SQLite 程序的数据库连接对象。如果 filename 参数是 NULL 或 ‘:memory:’,那么 sqlite3_open() 将会在 RAM 中创建一个内存数据库,这只会在 session 的有效时间内持续。如果文件名 filename 不为 NULL,那么 sqlite3_open() 将使用这个参数值尝试打开数据库文件。如果该名称的文件不存在,sqlite3_open() 将创建一个新的命名为该名称的数据库文件并打开。 |
| 2 | *sqlite3_exec(sqlite3*, const char *sql, sqlite_callback, void *data, char *errmsg) 该例程提供了一个执行 SQL 命令的快捷方式,SQL 命令由 sql 参数提供,可以由多个 SQL 命令组成。在这里,第一个参数 sqlite3 是打开的数据库对象,sqlite_callback 是一个回调,data 作为其第一个参数,errmsg 将被返回用来获取程序生成的任何错误。sqlite3_exec() 程序解析并执行由 sql 参数所给的每个命令,直到字符串结束或者遇到错误为止。 |
| 3 | sqlite3_close(sqlite3*) 该例程关闭之前调用 sqlite3_open() 打开的数据库连接。所有与连接相关的语句都应在连接关闭之前完成。如果还有查询没有完成,sqlite3_close() 将返回 SQLITE_BUSY 禁止关闭的错误消息。 |
sqlite3_exec函数原型如下:
int sqlite3_exec(
sqlite3*, /* 数据库句柄 */
const char *sql, /* 执行的SQLite命令 */
int (*callback)(void*,int,char**,char**), /* Callback function */
void *, /* 向回调函数传递的参数是 */
char **errmsg /* Error msg written here */
);
sqlite3_exec()是一个通用函数,可以执行SQLite命令行,相当于间接使用命令行来操作数据库。
打开数据库
直接调用sqlite3_open()打开一个数据库。
检测返回值是否为SQLITE_OK,如果不是,表示出错了,出错信息的获取通过句柄可以获取,如下:
const char *sqlite3_errmsg(sqlite3*);
SQLite有31种返回值,如下:
#define SQLITE_OK 0 /* Successful result */
/* beginning-of-error-codes */
#define SQLITE_ERROR 1 /* Generic error */
#define SQLITE_INTERNAL 2 /* Internal logic error in SQLite */
#define SQLITE_PERM 3 /* Access permission denied */
#define SQLITE_ABORT 4 /* Callback routine requested an abort */
#define SQLITE_BUSY 5 /* The database file is locked */
#define SQLITE_LOCKED 6 /* A table in the database is locked */
#define SQLITE_NOMEM 7 /* A malloc() failed */
#define SQLITE_READONLY 8 /* Attempt to write a readonly database */
#define SQLITE_INTERRUPT 9 /* Operation terminated by sqlite3_interrupt()*/
#define SQLITE_IOERR 10 /* Some kind of disk I/O error occurred */
#define SQLITE_CORRUPT 11 /* The database disk image is malformed */
#define SQLITE_NOTFOUND 12 /* Unknown opcode in sqlite3_file_control() */
#define SQLITE_FULL 13 /* Insertion failed because database is full */
#define SQLITE_CANTOPEN 14 /* Unable to open the database file */
#define SQLITE_PROTOCOL 15 /* Database lock protocol error */
#define SQLITE_EMPTY 16 /* Internal use only */
#define SQLITE_SCHEMA 17 /* The database schema changed */
#define SQLITE_TOOBIG 18 /* String or BLOB exceeds size limit */
#define SQLITE_CONSTRAINT 19 /* Abort due to constraint violation */
#define SQLITE_MISMATCH 20 /* Data type mismatch */
#define SQLITE_MISUSE 21 /* Library used incorrectly */
#define SQLITE_NOLFS 22 /* Uses OS features not supported on host */
#define SQLITE_AUTH 23 /* Authorization denied */
#define SQLITE_FORMAT 24 /* Not used */
#define SQLITE_RANGE 25 /* 2nd parameter to sqlite3_bind out of range */
#define SQLITE_NOTADB 26 /* File opened that is not a database file */
#define SQLITE_NOTICE 27 /* Notifications from sqlite3_log() */
#define SQLITE_WARNING 28 /* Warnings from sqlite3_log() */
#define SQLITE_ROW 100 /* sqlite3_step() has another row ready */
#define SQLITE_DONE 101 /* sqlite3_step() has finished executing */
插入信息
基于sqlite3_exec()使用命令行语句来插入信息,根据上面所讲,插入的命令行如下:
2-- 插入一条记录
insert into stuinfo values(1001, 'zhangshangngsan', 18, 80);
insert into stuinfo (id, name, score) values(1002, 'lisi', 90);
可以按照全部元素的顺序插入,也可以指定元素插入
插入多条的时候直接在后面加上即可
insert into stuinfo (id, name, score) values(1002, 'lisi', 90), (1001, 'zhangshan', 18, 80);
先读取到要插入的信息,然后使用sprintf函数格式化为字符串,最后将字符串传递给sqlite3_exec()的第二个参数const char *sql来执行命令行操作数据库。
查询
查询有两种基础方法
- 基于sqlite3_exec和回调函数,参考链接:https://sqlite.org/c3ref/exec.html
- 直接使用sqlite3_get_table函数,参考链接:https://sqlite.org/c3ref/free_table.html
sqlite3_exec函数原型如下:
int sqlite3_exec(
sqlite3*, /* 数据库句柄 */
const char *sql, /* 执行的SQLite命令 */
int (*callback)(void*,int,char**,char**), /* Callback function */
void *, /* 向回调函数传递的参数是 */
char **errmsg /* Error msg written here */
);
sqlite3_exec()是一个通用函数,可以执行SQLite命令行,相当于间接使用命令行来操作数据库。
查询的结果通过回调函数反馈,有几行记录,就调用几次回调函数,所以每次回调函数的执行都是对一行信息的查询。
关于回调函数有如下说明:
- 有几条记录就会调用几次回调函数
- 回调函数的参数通过sqlite3_exec的第三个参数传递,给回调函数的第一个参数
- 每条记录中有几列,就会传给第二个参数column
- 第三个参数就是对应字段内容
char **value,以字符串的形式传递 - 第四个参数char ** name就是字段名
- 二级指针的用法和main函数的参数
char *argv[]一样 - 回调函数返回的应该是0 表示正确,返回1代表出错
回调函数的定义可以如下:
static int callback(void *data, int argc, char **argv, char **azColName){
int i;
for(i=0; i<argc; i++){
printf("%s = %s\n", azColName[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
还有,可以通过sqlite3_get_table来获取表信息,sqlite3_get_table 专门用于查询语句,不需要回调了:
int sqlite3_get_table(
sqlite3 *db, /* 句柄 */
const char *zSql, /* SQL to be evaluated */
char ***pazResult, /* 获取的表信息,传递参数时直接一个二维数组的地址 */
int *pnRow, /* 行数,包括数据名称 */
int *pnColumn, /* 列数 */
char **pzErrmsg /* 出错信息 */
);
直接通过行数和列数来输出信息,不过要注意的是,返回到的查询信息,开始是表的数据名称,后面才是每个行的内容。
1.5 基于多进程的并发编程
Linux中的并发编程可分为如下:
- 基于多进程
- 基于IO多路复用
- 基于多线程
基于fork,父进程衍生出子进程处理相关事务,各个子进程之间相互独立,有着独立的用户空间,进程间的交互通过IPC机制实现。
注意:fork出的子进程是继承了父进程的文件描述符,也就是父进程和子进程都指向同一个文件表表项,所以在fork子进程的时候父进程一定要及时处理打开的文件描述符。
比如在多进程服务器编程的时候,父进程中的监听socket和已连接socket都会继承给子进程,也就是子进程也有对监听socket和已连接socket的引用。随后过程中,父进程继续监听,子进程去处理相关服务,当子进程结束的时候理应关闭已连接socket,但是由于父进程中还有一份对已连接socket的引用,所以得等父进程关闭之后已连接socket才会被释放,如果是高并发服务器,这样一直不释放文件描述符回引起内存泄漏最终将消耗可用的内存导致系统崩溃。所以!!!一般fork之后,父进程立即关闭已连接socket描述符,子进程立即关闭监听socket描述符。
典型的多进程并发服务器程序如下:

多进程的优势劣势:
- 优势:父子进程共享状态信息、共享文件表、独立用户地址,不用担心进程覆盖其他进程的虚拟内存
- 劣势:正是由于独立的地址空间,导致进程间的交互比较附加,得依靠显式的进程间通信机制,这样就导致基于多进程的并发编程比较慢,因为进程本来就开销大,而且进程控制和IPC都是需要开销的。

