


机器学习基础
机器学习
决策树
决策树怎么建树,基尼系数公式
决策树的生成是个递归过程,CART算法采用基尼指数选择最优特征,建树过程如下:
递归对每个节点进行以下操作,构建二叉决策树:
- 步骤1:设节点的训练数据集为D,计算现有特征对该数据集的基尼指数。此时,对每一个特征A,对其可能取的每个值a,根据样本点对A=a的测试为”是“或”否“将D分割成D1和D2两部分,利用基尼指数公式计算A=a时的基尼指数;
- 步骤2:在所有可能的特征A以及它们所有可能的切分点a中,选择基尼指数最小的特征及其对应的切分点作为最优特征与最优切分点。依最优特征和最优切分点,从现节点生成两个子节点,将训练数据集依特征分配到两个子节点中去;
- 步骤3:对两个子节点递归调用1)和2),直至满足停止条件;
- 步骤4:生成CART决策树;
算法停止条件是:节点中样本个数小于预定阈值,或样本集的基尼指数小于预定阈值(样本基本属于同一类),或者没有更多特征;
=== 3点考虑
- 选择哪个属性作为根节点;
- 选择哪些属性作为子节点;
- 什么时候停止并得到目标状态,即叶节点。
基尼指数公式:
其中D表示给定样本集合,$D_k$是D中属于第k类的样本子集,K是类的个数
当按照某个属性a进行划分后,此时的基尼系数为:
在选择合适的决策节点时,就按照使基尼系数最小的那个属性来划分。
参考文章
集成学习
Adaboost拟合目标是什么
Adaboost算法是前向分步加法算法的特例。模型是由基本分类器组成的加法模型,损失函数是指数函数。
强分类器(最终得到的模型,即基学习器的线性组合)计算公式:

其中x是输入向量,F(x)是强分类器, $f_t(x)$是弱分类器, $a_t$ 是弱分类器的权重值,是一个正数,T为弱分类器的数量。弱分类器的输出值为+1或-1,分别对应于正样本和负样本。分类时的判定规则为:

其中sgn是符号函数。强分类器的输出值也为+1或-1,同样对应于正样本和负样本。弱分类器和它们的权重值通过训练算法得到。之所以叫弱分类器是因为它们的精度不用太高。
AdaBoost的loss采用指数损失,基分类器最常见的是决策树(在很多情况下是决策树桩,深度为1的决策树)。在每一轮提升相应错分类点的权重可以被理解为调整错分类点的observation probability。
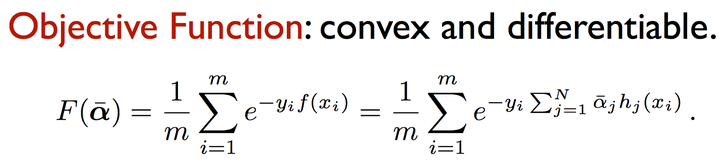
参考文章
Adaboost介绍一下,每个基学习器的权重怎么得到的
分类器重要性α更新规则(对应西瓜书上的解释)
推导前先回顾一下算法的伪代码:

开始论证
在AdaBoost中,第一个分类器h1是通过基学习算法用于初始数据分不而得,此后迭代生成ht和αt,当基分类器ht基于Dt产生后,该基分类器权重αt应使得αt*ht最小化损失函数.
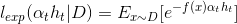
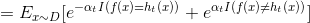
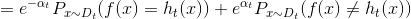
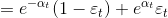
当前基学习器分类错误的概率:
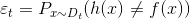
对损失函数求导:
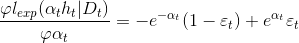
令导数为0得:
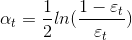
恰好对应伪代码的第六步.
参考文章


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了