Redis

Author:Exchanges
Version:9.0.1
一、引言
1.1 数据库压力过大
由于用户量增大,请求数量也随之增大,数据压力过大
1.2 数据不同步
多台服务器之间,数据不同步
1.3 传统锁失效
多台服务器之间的锁,已经不存在互斥性了。
二、Redis介绍
2.1 关于关系型数据库和NOSQL数据库(键值对存储)
关系型数据库是基于关系表的数据库,最终会将数据持久化到磁盘上,而nosql数据库是基于特殊的结构,并将数据存储到内存的数据库。从性能上而言,nosql数据库要优于关系型数据库,从安全性上而言关系型数据库要优于nosql数据库,所以在实际开发中一个项目中nosql和关系型数据库会一起使用,达到性能和安全性的双保证。
NOSQL产品: redis,mongodb,memcached...
- Redis就是一款NoSQL
- NoSQL -> 非关系型数据库 -> Not Only SQL。
- Key-Value:Redis ...
- 文档型:ElasticSearch,Solr,Mongodb ...
- 面向列:Hbase,Cassandra ...
- 图形化:Neo4j ...
- 除了关系型数据库都是非关系型数据库
- NoSQL只是一种概念,泛指非关系型数据库,和关系型数据库做一个区分
2.2 Redis介绍
有一位意大利人,在开发一款LLOOGG的统计页面,因为MySQL的性能不好,自己研发了一款非关系型数据库,并命名为Redis。Salvatore。
Redis(Remote Dictionary Server)即远程字典服务,Redis是由C语言去编写,Redis是一款基于Key-Value的NoSQL,而且Redis是基于内存存储数据的,Redis还提供了多种持久化机制,性能可以达到110000/s读取数据以及81000/s写入数据,Redis还提供了主从,哨兵以及集群的搭建方式,可以更方便的横向扩展以及垂直扩展。
| Redis之父 |
|---|
 |
三、Redis安装
3.1 安装Redis
官网提供安装方式如下:(安装redis编译的c环境,此步骤没有编译)
Installation
Download, extract and compile Redis with:
$ wget <http://download.redis.io/releases/redis-5.0.5.tar.gz >
$ tar xzf redis-5.0.5.tar.gz $ cd redis-5.0.5
$ make
The binaries that are now compiled are available in the src directory. Run Redis with:
$ src/redis-server
You can interact with Redis using the built-in client:
$ src/redis-cli
redis> set foo bar
OK
redis> get foo
"bar"
3.3 安装步骤
1.把下载好的redis-6.2.6.tar.gz安装包拷贝到当前虚拟机root目录下,解压到/usr/local下
[root@localhost ~]# tar -zxvf redis-6.2.6.tar.gz -C /usr/local2.编译的c环境,注:安装时如果显示yum正在运行,需要先将yum进程kill后再执行该命令
[root@localhost ~]# yum install gcc-c++3.进入redis-6.2.6目录 使用make命令编译redis(若报错,先make distclean,再make)
[root@localhost redis-6.2.6]# make4.使用make PREFIX=/usr/local/redis-6.2.6 install命令安装(安装后会出现bin目录)
[root@localhost redis-6.2.6]# make PREFIX=/usr/local/redis-6.2.6 install5.启动redis服务端(前台启动)
[root@localhost redis-6.2.6]# cd bin[root@localhost bin]# ./redis-server
启动后看到如上欢迎页面,但此窗口不能关闭,窗口关闭就认为redis也关闭了,所以我们需要在后台启动,然后再启动客户端进行连接,所以首先Ctrl+C退出。
解决:可以通过修改配置文件配置redis的后台启动(即服务器启动了但不会创建控制台窗口)
步骤如下:
1.切换到redis-6.2.6目录下,把当前目录下的redis.conf文件拷贝到bin目录下
[root@localhost bin]# cd ../[root@localhost redis-6.2.6]# cp redis.conf bin/redis.conf2.切换到bin目录下,修改redis.conf文件
[root@localhost redis-6.2.6]# cd bin[root@localhost bin]# vim redis.conf3.将redis.conf文件中的daemonize的值从no修改成yes表示后台启动
4.启动redis服务端(后台启动)
[root@localhost bin]# ./redis-server redis.conf5.查看是否启动成功
[root@localhost bin]# ps -ef | grep redis6.启动客户端
[root@localhost bin]# ./redis-cli7.存取数据进行测试
127.0.0.1:6379> set name jack OK127.0.0.1:6379> get name "jack"
3.4 Redis的配置文件
| 配置项名称 | 配置项值范围 | 说明 |
|---|---|---|
| daemonize | yes、no | yes表示启用守护进程,默认是no即不以守护进程方式运行。其中Windows系统下不支持启用守护进程方式运行 |
| port | 指定 Redis 监听端口,默认端口为 6379 | |
| bind | 绑定的主机地址,如果需要设置远程访问则直接将这个属性备注下或者改为bind * 即可,这个属性和下面的protected-mode控制了是否可以远程访问 。 | |
| protected-mode | yes 、no | 默认是yes,即开启。设置外部网络连接redis服务,设置方式如下:1、关闭protected-mode模式,此时外部网络可以直接访问2、开启protected-mode保护模式,需配置bind ip或者设置访问密码 |
| timeout | 300 | 当客户端闲置多长时间后关闭连接,如果指定为 0,表示关闭该功能 |
| loglevel | debug、verbose、notice、warning | 日志级别,默认为 notice |
| databases | 16 | 设置数据库的数量,默认的数据库是0。整个通过客户端工具可以看得到 |
| rdbcompression | yes、no | 指定存储至本地数据库时是否压缩数据,默认为 yes,Redis 采用 LZF 压缩,如果为了节省 CPU 时间,可以关闭该选项,但会导致数据库文件变的巨大。 |
| dbfilename | dump.rdb | 指定本地数据库文件名,默认值为 dump.rdb |
| dir | 指定本地数据库存放目录 | |
| requirepass | 设置 Redis 连接密码,如果配置了连接密码,客户端在连接 Redis 时需要通过 AUTH |
|
| maxclients | 0 | 设置同一时间最大客户端连接数,默认无限制,Redis 可以同时打开的客户端连接数为 Redis 进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis 会关闭新的连接并向客户端返回 max number of clients reached 错误信息。 |
| maxmemory | XXX |
指定 Redis 最大内存限制,Redis 在启动时会把数据加载到内存中,达到最大内存后,Redis 会先尝试清除已到期或即将到期的 Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis 新的 vm 机制,会把 Key 存放内存,Value 会存放在 swap 区。配置项值范围列里XXX为数值。 |
四、redis-benchmark官方自带的性能测试工具
4.1 在安装的redis中可以看到redis-benchmark

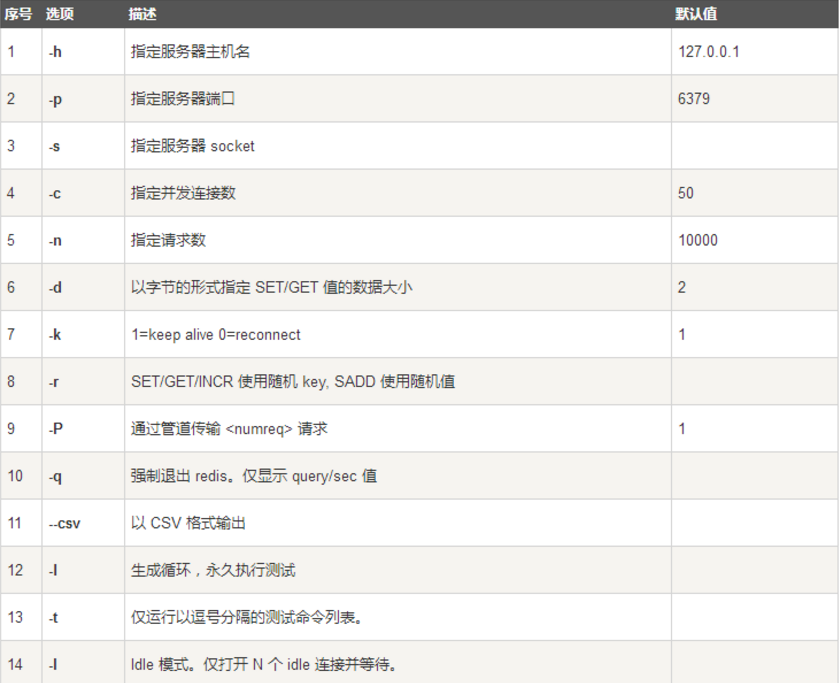
4.2 关于redis-benchmark 的一些参数
测试:100个并发,十万个请求,单机测试
[root@localhost bin]# ./redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000
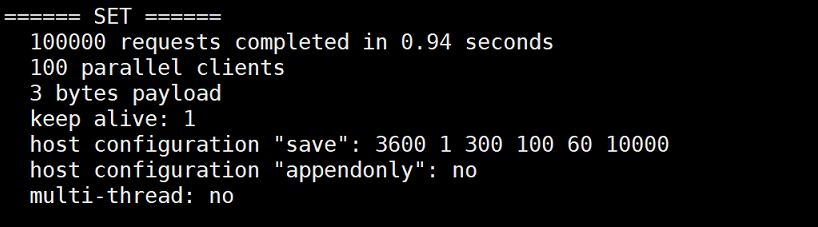
====== SET ======
100000 requests completed in 0.94 seconds 表示对十万个请求进行写入测试
100 parallel clients 100个并发客户端
3 bytes payload 每次写入3个字节
keep alive: 1 只有一台服务器处理请求
host configuration "save": 3600 1 300 100 60 10000 RDB持久化方式默认开启的规则
host configuration "appendonly": no AOF持久化方式未开启
multi-thread: no 多线程未开启99.998% <= 12.559 milliseconds (cumulative count 99999)
99.999% <= 12.567 milliseconds (cumulative count 100000)
100.000% <= 12.567 milliseconds (cumulative count 100000) 请求在多少毫秒处理完成throughput summary: 106837.61 requests per second 每秒处理请求数
另一种写法:
只测试 set 和 get 命令后退出
[root@localhost bin]# ./redis-benchmark -h 127.0.0.1 -p 6379 -t set,get -n 10000 -q
五、Redis的数据类型【重点】
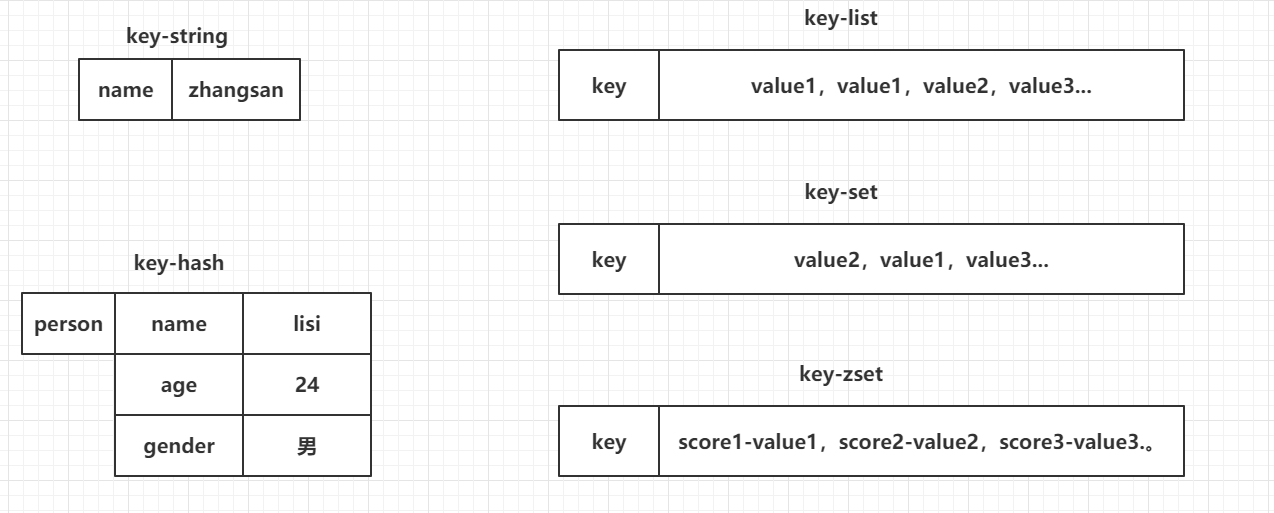
常用的5种数据结构:
- key-string:一个key对应一个值。
- key-hash:一个key对应一个Map。
- key-list:一个key对应一个列表。
- key-set:一个key对应一个集合。
- key-zset:一个key对应一个有序的集合。
另外三种数据结构:
- HyperLogLog:计算近似值的。
- GEO:地理位置。
- BIT:一般存储的也是一个字符串,存储的是一个byte[]。
redis是一种高级的key-value的存储系统,其中的key是字符串类型,尽可能满足如下几点:
1.key不要太长,最好不要操作1024个字节,这不仅会消耗内存还会降低查找效率
2.key不要太短,如果太短会降低key的可读性
3.在项目中,key最好有一个统一的命名规范(根据企业的需求)
value最常用的五种数据类型:
1.字符串(String):最常用的,一般用于存储一个值
2.列表(List):使用list结构实现栈和队列结构
3.集合(Set) :交集,差集和并集的操作
4.有序集合(sorted set) :排行榜,积分存储等操作
5.哈希(Hash):存储一个对象数据的
5.1 字符串(String)
set key value:设定key持有指定的字符串value,如果该key存在则进行覆盖操作,总是返回"OK"
get key:获取key的value。如果与该key关联的value不是String类型,redis将返回错误信息,因为get命令只能用于获取String value,如果该key不存在,返回null
setex key seconds value:设置key以及对应的value,还可以设置过期时间
setnx key value:当key不存在时,设置对应的value,当key存在时,不做任何操作
incr key:将指定的key的value原子性的递增1.如果该key不存在,其初始值为0,在incr之后其值为1。如果value的值不能转成整型,如hello,该操作将执行失败并返回相应的错误信息。
decr key:将指定的key的value原子性的递减1.如果该key不存在,其初始值为0,在incr之后其值为-1。如果value的值不能转成整型,如hello,该操作将执行失败并返回相应的错误信息。
incrby key increment:将指定的key的value原子性增加increment,如果该key不存在,器初始值为0,在incrby之后,该值为increment。如果该值不能转成整型,如hello则失败并返回错误信息。
decrby key decrement:将指定的key的value原子性减少decrement,如果该key不存在,器初始值为0,在decrby之后,该值为decrement。如果该值不能转成整型,如hello则失败并返回错误信息。
使用场景如下:
1.简单的缓存存储(最常用)
2.消息的失效性(过期时间的设置)
3.分布式锁的实现(redisson)
5.2 列表(List)
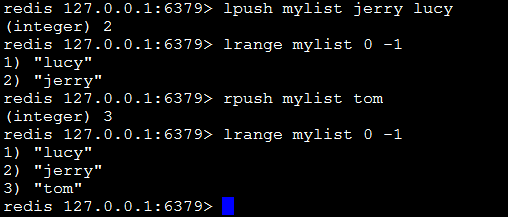
lpush key value1 value2...:在指定的key所关联的list的头部插入所有的values,如果该key不存在,该命令在插入的之前创建一个与该key关联的空链表,之后再向该链表的头部插入数据。插入成功,返回元素的个数。
rpush key value1 value2…:在该list的尾部添加元素。
lrange key start end:获取链表中从start到end的元素的值,start、end可为负数,若为-1则表示链表尾部的元素,-2则表示倒数第二个,依次类推….
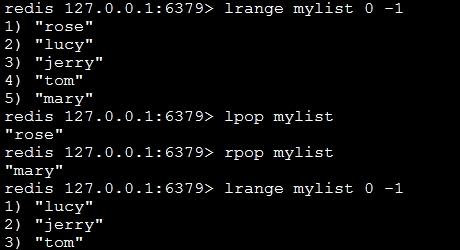
lpop key:返回并弹出指定的key关联的链表中的第一个元素,即头部元素。
rpop key:从尾部弹出元素。
llen key:返回指定的key关联的链表中的元素的数量。
使用场景如下:
消息流的场景:
1.用户的id作为key,发送的消息作为value,例如:朋友圈发布,微博发布,公众号发布...
5.3 集合(Set,不允许出现重复的元素)
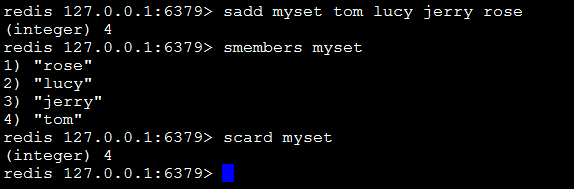
sadd key value1 value2…:向set中添加数据,如果该key的值已有则不会重复添加。
smembers key:获取set中所有的成员。
scard key:获取set中成员的数量。
sismember key member:判断参数中指定的成员是否在该set中,1表示存在,0表示不存在或者该key本身就不存在。
srem key member1 member2… :删除set中指定的成员。

srandmember key:随机返回set中的一个成员。
spop key:随机返回set中的一个成员并从set中移除。
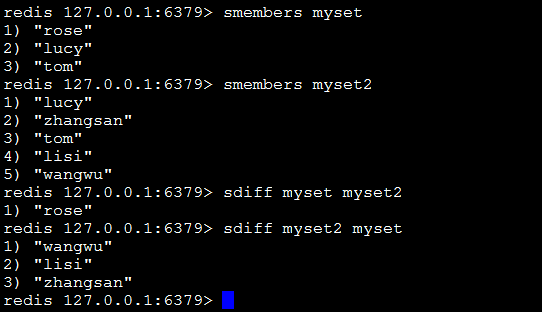
sdiff key1 key2:返回key1与key2中相差的成员,而且与key的顺序有关,即返回差集。
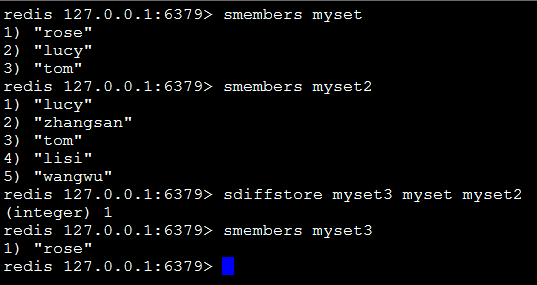
sdiffstore destination key1 key2:将key1、key2相差的成员存储在destination上。
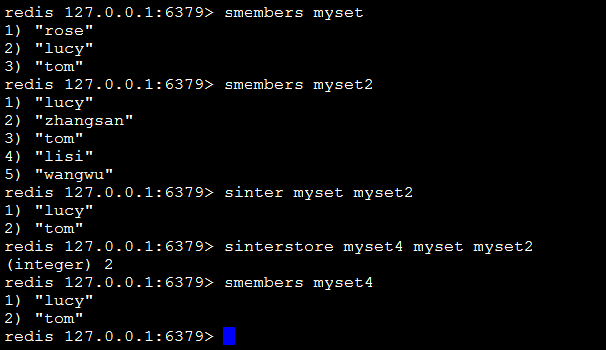
sinter key[key1,key2…]:返回交集。
sinterstore destination key1 key2:将返回的交集存储在destination上。
sunion key1 key2:返回并集。
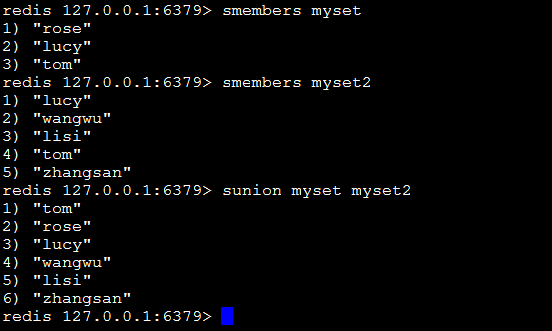
sunionstore destination key1 key2:将返回的并集存储在destination上
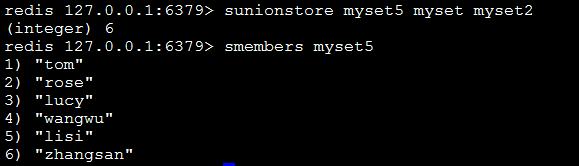
使用场景如下:
公司年会,随机抽奖小程序
1.把所有用户统一存入set集合中
2.查看所有抽奖人数
3.随机抽取指定得奖人数并从set集合中删除
实现:
1.sadd choujiang userid1,userid2,userid3...
2.smembers choujiang
3.spop choujiang [count]
微信点赞,微博收藏
1.点赞,创建集合并加入对应用户
2.取消点赞,从集合中删除对应用户
3.检查用户是否点过赞
4.获取点赞用户列表
5.获取点赞用户数量
实现:
1.sadd dianzan userid1,userid2,userid3...
2.srem dianzan userid1
3.sismember dianzan userid1
4.smembers dianzan
5.scard dianzan
可能认识的人推荐
1.两个集合取交集
实现:
1.sinter user1list,user2list...
2.sinterstore list user1list,user2list...
5.4 有序集合(sorted set)
zadd key score member score2 member2 … :将所有成员以及该成员的分数存放到sorted-set中。
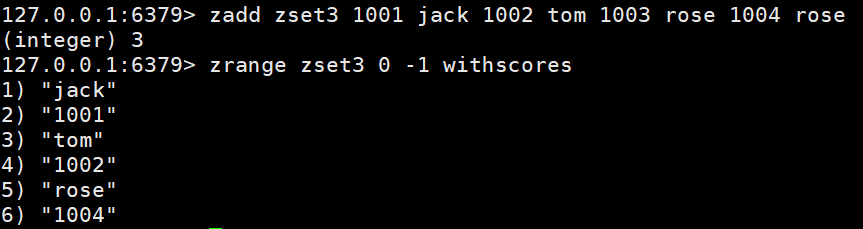
zcard key:获取集合中的成员数量。
zcount key min max:获取分数在[min,max]之间的成员。


zincrby key increment member:设置指定成员的增加的分数。
zrangebyscore key min max [withscores] [limit offset count]:返回分数在[min,max]的成员并按照分数从低到高排序。[withscores]:显示分数;[limit offset count]:offset,表明从脚标为offset的元素开始并返回count个成员。
zrevrangebyscore key min max [withscores] [limit offset count]:上面类似(score需从大到小),从高到底排序
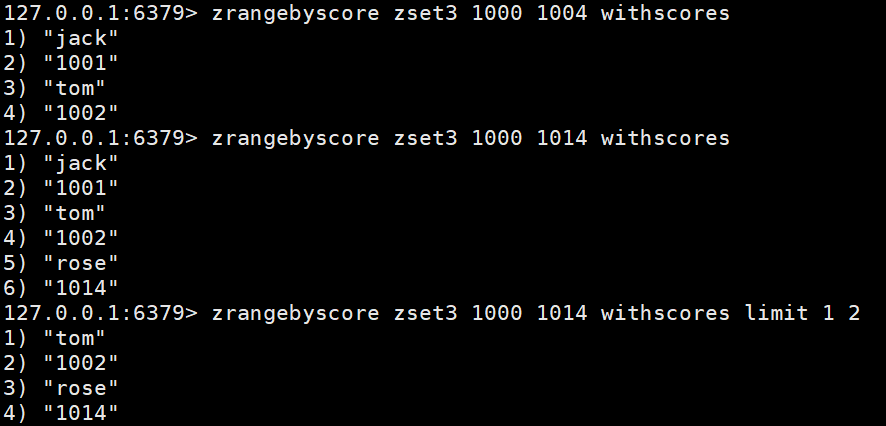
使用场景如下:
排行榜实现
1.对播放的视频,分数自增1
2.展示排行榜前十的视频
实现:
1.zincrby videos 1 video1id
2.zrevrangebyscore videos 100 0 withscores limit 0 10 (zrevrangebyscore从大到小排序)
5.5 哈希(Hash)
hset key field value:为指定的key设定field/value对(键值对)。
hget key field:返回指定的key中的field的值。
hgetall key:获取key中的所有filed-vaule。
hlen key:获取key所包含的field的数量。
hincrby key field increment:设置key中filed的值增加increment
hdel key field [field ...]:删除key中的属性
使用场景如下:
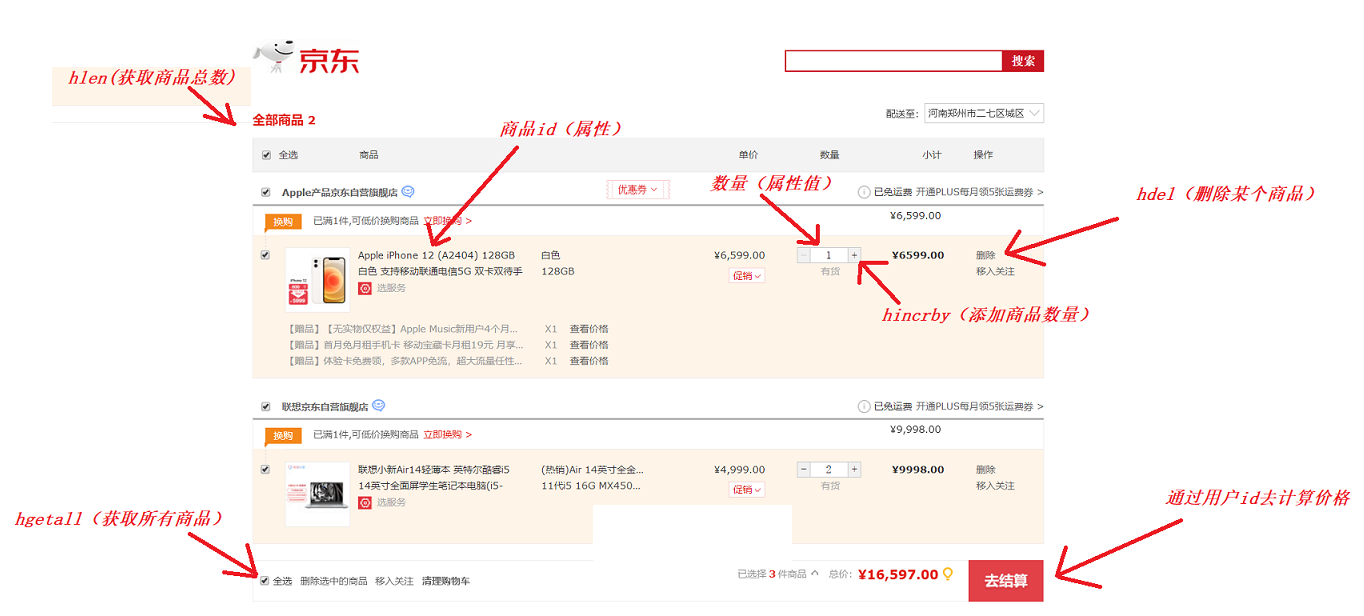
购物车场景:
1.用户的id作为key
2.商品的id作为field(属性)
3.商品的数量作为value(属性值)
购物车操作:
1.用户添加购物车:hset cart:1001 20001 1 (id为1001的用户添加了一个id为20001的商品,数量为1个)
2.增加对应商品数量:hincrby cart:1001 20001 1
3.查询商品总数:hlen cart:1001
4.删除该用户的某个商品:hdel cart:1001 20001
5.查询该用户购物车信息:hgetall cart:1001
5.6 通用操作
keys patten:获取所有与patten匹配的key,*表示任意字符,?表示一个字符。
del key1 key2....:删除指定的key。
exists key:判断该key是否存在,1表示存在,0表示不存在。
expire key second:为当前key设置过期时间(单位:秒)。
ttl key:查看当前key剩余过期时间。
flushall: 删除所有key(慎用)
flushdb: 删除所有key(慎用)
六、Jedis的使用【重点】
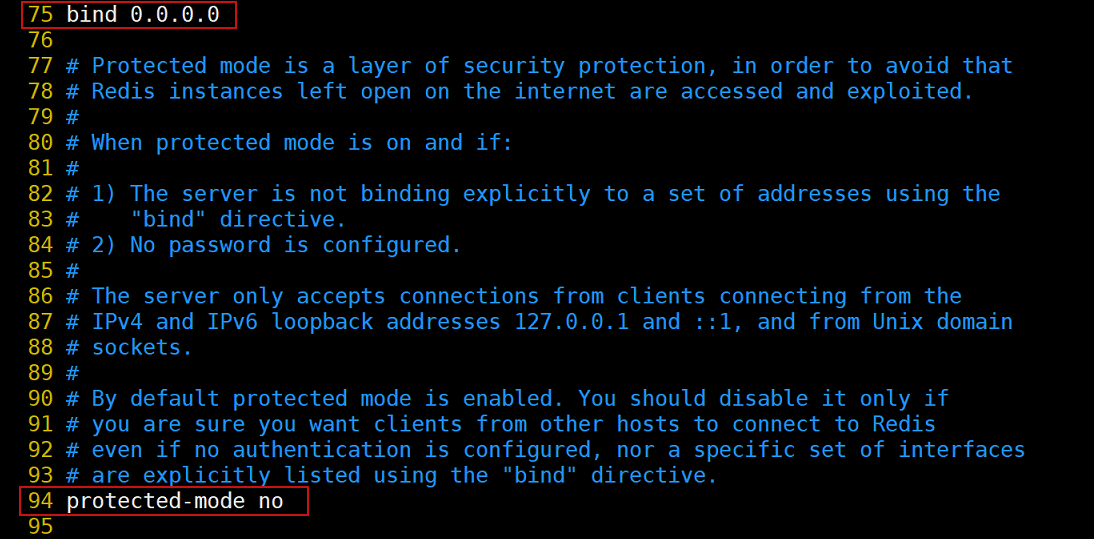
1.修改/usr/local/redis-5.0.4/bin目录下的redis.conf配置文件,然后启动redis服务端
修改redis.conf文件中的bind为:0.0.0.0,然后把保护模式关掉
如需设置密码,可以使用以下两种方式:
方式一:通过修改 redis.conf 文件,设置Redis的密码校验
requirepass 密码
方式二:在不修改 redis.conf 文件的前提下,在第一次链接Redis时,输入命令:Config set requirepass 密码
后续连接redis客户端的时候,需要先 AUTH 做一下校验
127.0.0.1:6379> auth 密码
2.创建Maven工程,导入依赖
<dependencies>
<!-- jedis客户端 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.2.3</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>compile</scope>
</dependency>
</dependencies>
3.编写实体类
package com.qf.pojo;
import lombok.Data;
@Data
public class User {
private Integer id;
private String name;
private String password;
}
4.编写测试类
package com.qf.jedis;
import com.alibaba.fastjson2.JSON;
import com.qf.pojo.User;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisTest {
@Test
public void test1(){
//获取客户端对象
Jedis jedis = new Jedis("192.168.126.129",6379);
//如果有密码,必须设置
//jedis.auth("root");
//存储String类型数据
jedis.set("content","java2203");
//取String值
System.out.println(jedis.get("content"));
//存对象
User user = new User();
user.setId(1);
user.setName("张三");
user.setPassword("123");
String userJson = JSON.toJSONString(user);
jedis.set("user",userJson);
//取对象
String jsonStringUser = jedis.get("user");
System.out.println(jsonStringUser);
User db_user = JSON.parseObject(jsonStringUser, User.class);
System.out.println(db_user);
//关闭
jedis.close();
}
@Test
public void test2(){
//通过池拿jedis对象
//配置一些参数
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
//配置参数
jedisPoolConfig.setMaxTotal(200);//最大连接数
jedisPoolConfig.setMaxIdle(20);//最大空闲
jedisPoolConfig.setMinIdle(1);//最小空闲
//创建JedisPool对象
JedisPool jedisPool = new JedisPool(jedisPoolConfig,"192.168.126.129",6379);
//获取jedis对象
Jedis jedis = jedisPool.getResource();
//如果有密码,必须设置
//jedis.auth("root");
//操作List集合
jedis.lpush("sina001","今天中午吃什么?","今天晚上喝什么");
System.out.println(jedis.lrange("sina001",0,-1));
//操作Set集合
jedis.sadd("userList","jack","rose","jack");
System.out.println(jedis.smembers("userList"));
//有序Set以及Hash
//....
//关闭
jedis.close();
}
}
七、Redis中的事务【了解】
Redis中的事务和MySQL中的事务有本质的区别,Redis中的事务是一个单独的隔离操作,事务中所有的命令都会序列化,按照顺序执行,事务在执行的过程中,不会被其他客户端发来的命令所打断,因为Redis服务端是个单线程的架构,不同的Client虽然看似可以同时保持连接,但发出去的命令是序列化执行的,这在通常的数据库理论下是最高级别的隔离。
Redis中的事务的作用就是串联多个命令,防止别的命令插队。
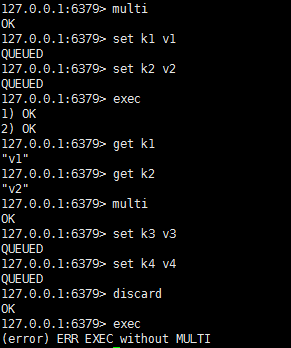
常用命令:multi、exec、discard、watch、unwatch
当输入multi命令时,之后输入的命令都会被放在队列中,但不会执行,直到输入exec后,Redis会将队列中的命令依次执行,discard用来撤销Exec之前被暂存的命令,并不是回滚。
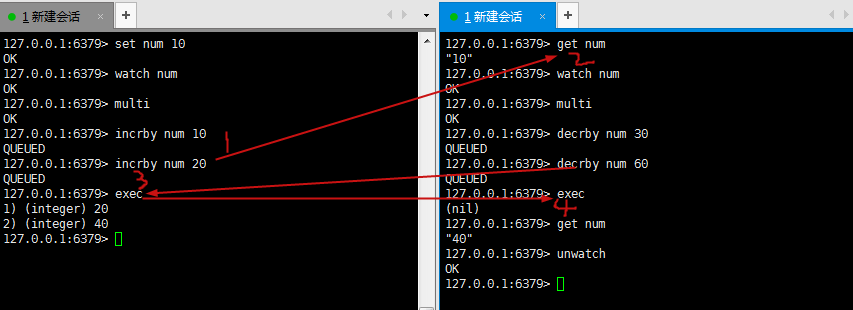
watch/unwatch
在执行multi之前,先执行watch key1 [key2...] ,watch提供的乐观锁功能(初始时一个版本号,exec之后会更新当前版本号),在你exec的那一刻,如果被watch的键发生过改动,则multi到exec之间的指令全部不执行。
watch表示监控,相当于加锁,但在执行完exec时就会解锁。
unwatch取消所有锁。
Redis中的事务的特性总结
1.单独的隔离操作
事务中的所有命令都会序列化,然后按顺序执行,在执行过程中,不会被其他客户端发送的命令打断。
2.没有隔离级别的概念
队列中的命令没有被提交之前都不会执行。
3.不能保证原子性
Redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,不会回滚
八、Redis消息订阅与发布【了解】
subscribe channel 订阅频道 例如:subscribe cctv5
publish channel content 在指定频道中发布内容 例如:publish cctv5 basketball
同时打开两个客户端,一个订阅频道,一个在频道中发布内容,订阅频道的客户端会接收到消息。

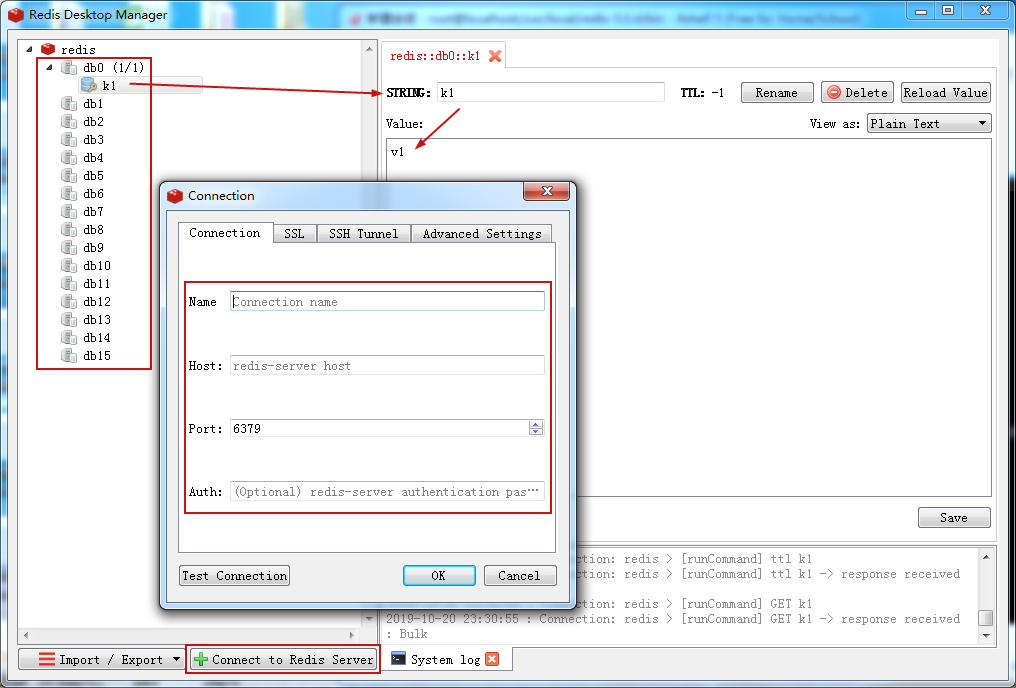
九、Redis图形化程序界面【了解】
Redis中默认有16个库,可以在不同的库中存储数据,默认使用0号库存储数据,使用select 0-15可以选择不同的库。

安装之前,需要修改redis.conf文件中的bind为:0.0.0.0(之前已经修改过了)
安装之后,输入IP地址登录即可看到如下界面:
十、Redis中的持久化【重点】
Redis有两种持久化方式:RDB和AOF。
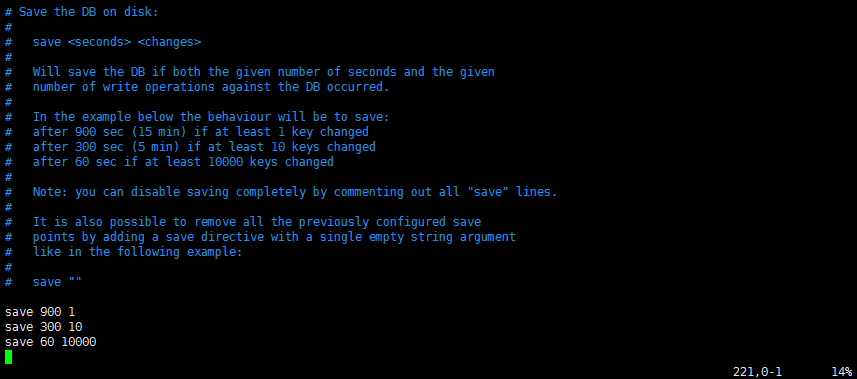
1.RDB(Redis DataBase)
将内存中的数据以快照的方式写入磁盘中,在redis.conf文件中,我们可以找到如下配置:
save 900 1
save 300 10
save 60 10000
配置含义:
900秒内,如果超过1个key被修改,则发起快照保存
300秒内,如果超过10个key被修改,则发起快照保存
60秒内,如果1万个key被修改,则发起快照保存
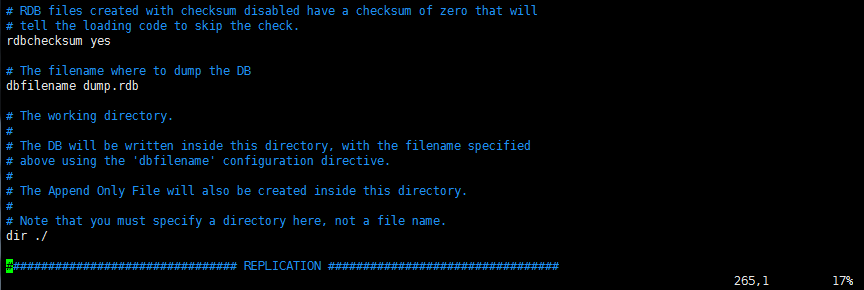
RDB方式存储的数据会在
dump.rdb文件中(在哪个目录启动redis服务端,该文件就会在对应目录下生成),该文件不能查看,如需备份,对Redis操作完成之后,只需拷贝该文件即可(Redis服务端启动时会自动加载该文件)
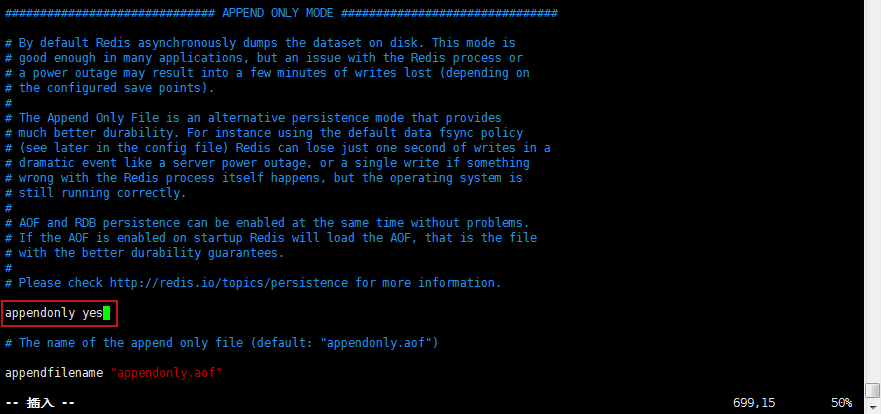
2.AOF(Append Of File)
AOF默认是不开启的,需要手动开启,同样是在redis.conf文件中开启,如下:
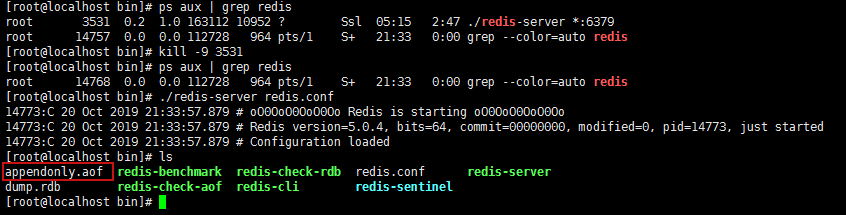
配置文件中的appendonly修改为yes,开启AOF持久化。开启后,启动redis服务端,发现多了一个appendonly.aof文件。
之后任何的操作都会保存在appendonly.aof文件中,可以进行查看,Redis启动时会将appendonly.aof文件中的内容执行一遍。
如果AOF和RDB同时开启,系统会默认读取AOF的数据。
3.总结
RDB优点与缺点
优点
如果要进行大规模数据的恢复,RDB方式要比AOF方式恢复速度要快。
RDB是一个非常紧凑(compact)的文件,它保存了某个时间点的数据集,非常适合用作备份,同时也非常适合用作灾难性恢复,它只有一个文件,内容紧凑,通过备份原文件到本机外的其他主机上,一旦本机发生宕机,就能将备份文件复制到redis安装目录下,通过启用服务就能完成数据的恢复。
缺点
RDB这种持久化方式不太适应对数据完整性要求严格的情况,因为,尽管我们可以用过修改快照实现持久化的频率,但是要持久化的数据是一段时间内的整个数据集的状态,如果在还没有触发快照时,本机就宕机了,那么对数据库所做的写操作就随之而消失了并没有持久化本地dump.rdb文件中。
AOF优点与缺点
优点
AOF有着多种持久化策略:
appendfsync always:每修改同步,每一次发生数据变更都会持久化到磁盘上,性能较差,但数据完整性较好。
appendfsync everysec: 每秒同步,每秒内记录操作,异步操作,如果一秒内宕机,有数据丢失。
appendfsync no:不同步。
AOF文件是一个只进行追加操作的日志文件,对文件写入不需要进行seek,即使在追加的过程中,写入了不完整的命令(例如:磁盘已满),可以使用redis-check-aof工具可以修复这种问题
Redis可以在AOF文件变得过大时,会自动地在后台对AOF进行重写:重写后的新的AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建AOF文件的过程中,会继续将命令追加到现有的AOF文件中,即使在重写的过程中发生宕机,现有的AOF文件也不会丢失。一旦新AOF文件创建完毕,Redis就会从旧的AOF文件切换到新的AOF文件,并对新的AOF文件进行追加操作。
缺点
对于相同的数据集来说,AOF文件要比RDB文件大。
根据所使用的持久化策略来说,AOF的速度要慢于RDB。一般情况下,每秒同步策略效果较好。不使用同步策略的情况下,AOF与RDB速度一样快。
十一、Redis的主从复制 【重点】
主从复制是指将一台Redis服务器的数据,复制到其它的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用:
1.数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
2.故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复,但实际上是一种服务的冗余.
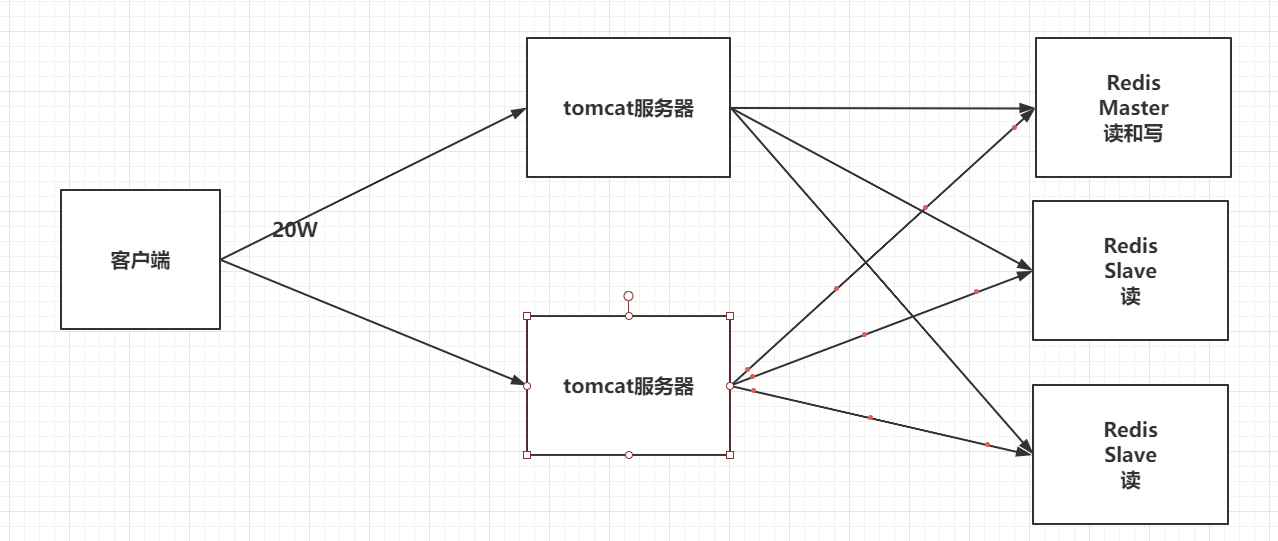
3.负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
4.高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础.
配置步骤:
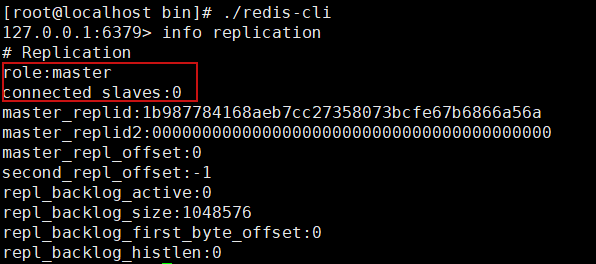
1.查看当前库的信息:
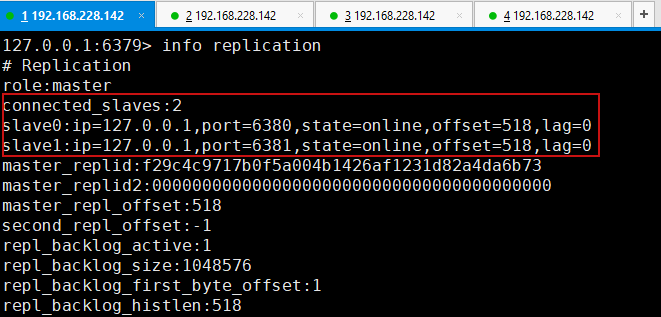
127.0.0.1:6379> info replication
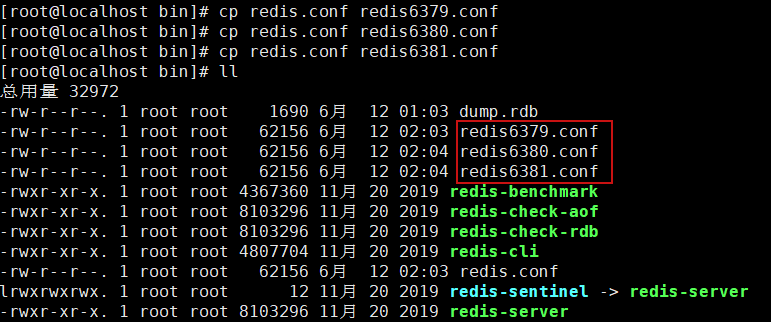
2.关闭当前运行的redis,打开四个链接,进行测试,拷贝三个redis.conf文件(改成6379,6380,6381)
3.分别修改这三个文件信息,需要修改:端口,pid名字,log文件名字,dump.rdb名字
port 6379
pidfile /var/run/redis_6379.pid
logfile "6379.log"
dbfilename dump6379.rdb
port 6380
pidfile /var/run/redis_63780pid
logfile "6380.log"
dbfilename dump6380.rdb
port 6381
pidfile /var/run/redis_6381.pid
logfile "6381.log"
dbfilename dump6381.rdb
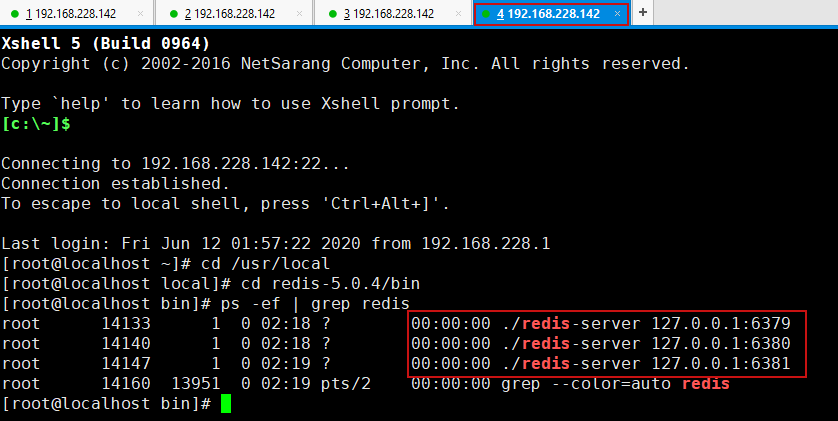
4.分别在三个链接中启动6379,6380,6381三台redis-server,在第四个链接中查看
查看状态
5.配置一主二从
默认情况下,每台Redis都是主节点,我们只需要配置从机即可,我们这里使用6379为主机,6380和6381为从机.
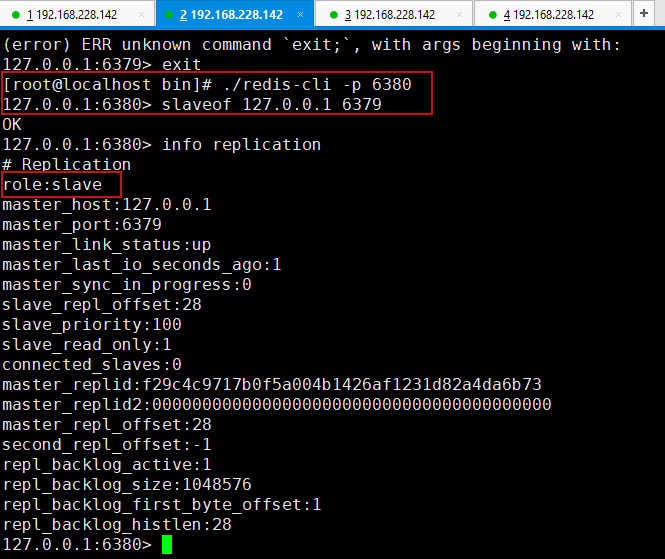
在对应6380的链接中进行配置:
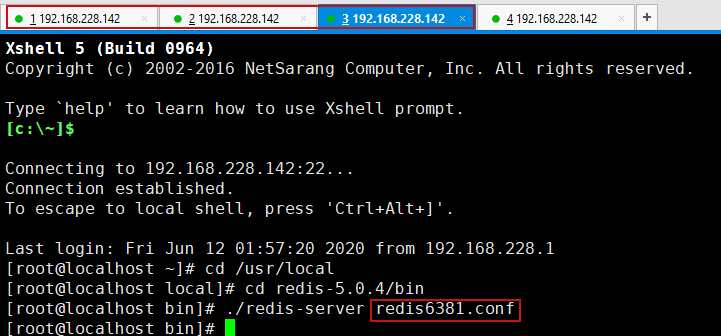
[root@localhost bin]# ./redis-cli -p 6380 127.0.0.1:6380> slaveof 127.0.0.1 6379
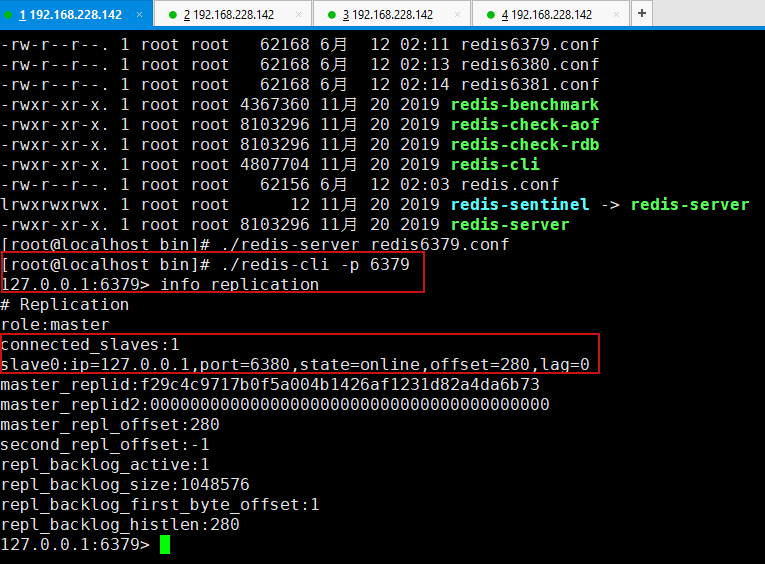
6380从机配置成功之后,可以去主机中查看对应信息
6381从机配置方式和6380一样,配置成功之后可以再去看一下主机
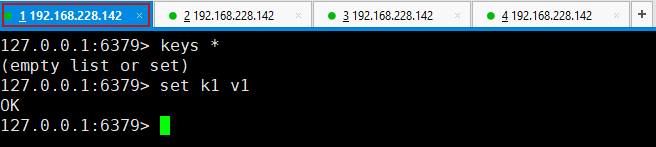
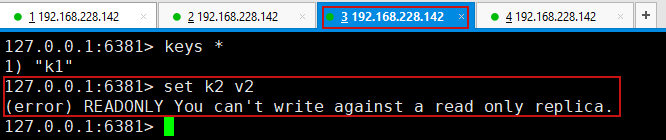
6.由于这里使用的是命令进行配置,所以是暂时的,一般公司配置会在配置文件中进行配置,属于永久性配置,相当于一打开当前服务器,该服务器就是从机,一般主机可以写,从机不能写只能读,主机中的所有信息和数据都会被从机保存!


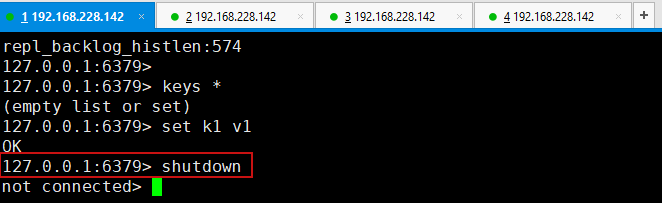
即使主机断开链接(127.0.0.1:6379>shutdown),从机仍然可以连接到主机,如果使用的是命令行配置的从机,从机一旦断开链接后,就会变回主机了,如果再次变回从机,仍旧可以获取主机中的值.
如果主机断开链接,从机可以使用命令:127.0.0.1:6380>slaveof no one 使自己成为主机
7.主从复制原理
Slave启动成功连接到master后会发送一个sync同步命令,Master接到命令后,会启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕后,master将传送整个数据文件到salve,并完成一次完整的同步.
全量复制:salve服务在接收到数据库文件数据后,将其存盘并加载到内存中.
增量复制:master继续将新的所有收集到的修改命令依次传递给salve,完成同步.
如果是配置文件配置,可直接在对应的redis.conf文件中添加: slaveof 127.0.0.1 6379 (和命令一样)
十二、Redis的哨兵模式【重点】
当主服务器宕机后,并且我们并没有及时发现,这时候就可能会出现数据丢失或程序无法运行。此时,redis的哨兵模式就派上用场了,可以用它来做redis的高可用.
每个哨兵都是监控主节点,主节点宕机,哨兵不会宕机!
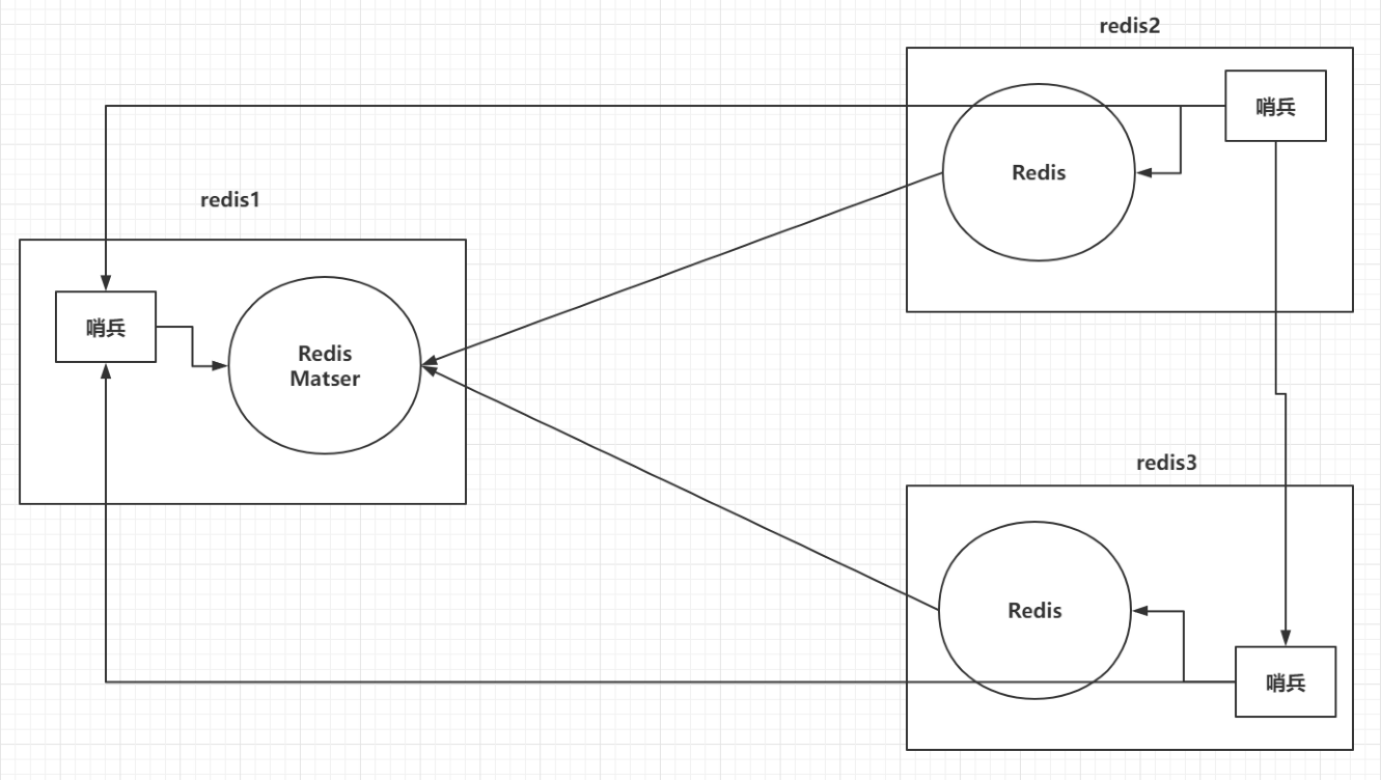
功能作用:
1.监控(monitoring):Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
2.提醒(Notifation):当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
3.自动故障转移(Automatic failover):当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
配置步骤:
1.创建哨兵配置文件
[root@localhost bin]# vim sentinel.confsentinel.conf文件内容如下:(格式:sentinel monitor 被监控名称 host port 1)
sentinel monitor myredis 127.0.0.1 6379 1
注意:需要修改redis.conf文件中的bind为:0.0.0.0(之前已经修改过了),如果是三台阿里云服务器,每个服务器都要设置sentinel.conf文件并启动哨兵,127.0.0.1改成主机的IP地址,(从机也是监控主机IP,相当于三台服务器的sentinel.conf的内容都是一样的:sentinel monitor myredis 主机IP地址 6379 1),后面的数字1表示有1个sentinel认为一个master失效时,master就算真正失效,slave会以投票的方式选举成为主机,一般设置的值为从机数量一半以上,比如说:三个从机就设置为:2
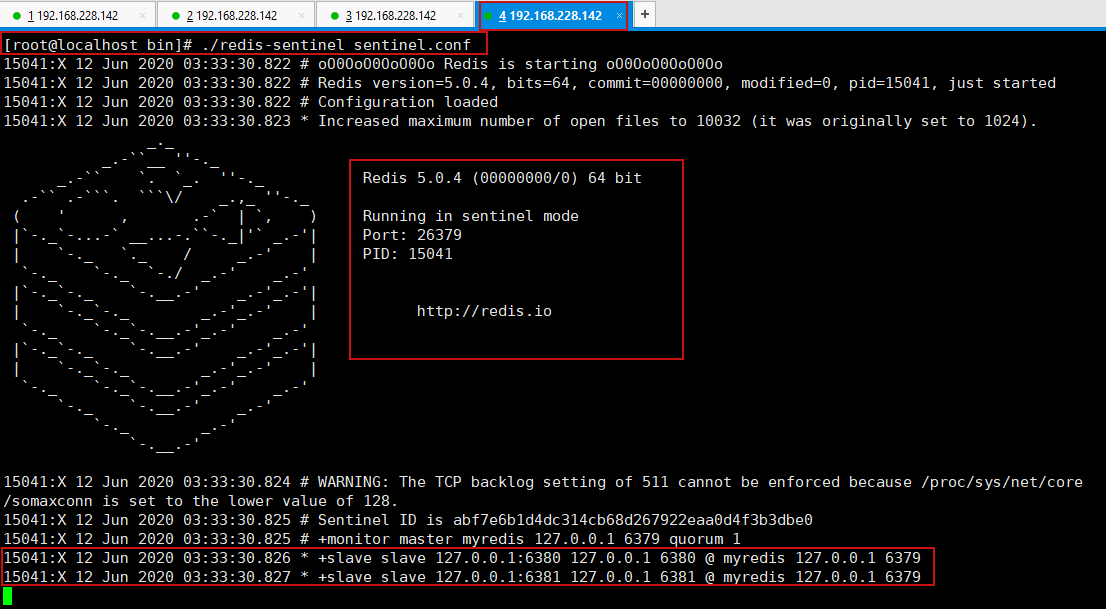
2.启动哨兵
[root@localhost bin]# ./redis-sentinel sentinel.conf
3.如果Master节点断开了(主机宕机了),过一会,会发送哨兵日志,并自动通过算法在其他两个从机中选择一个成为主机.

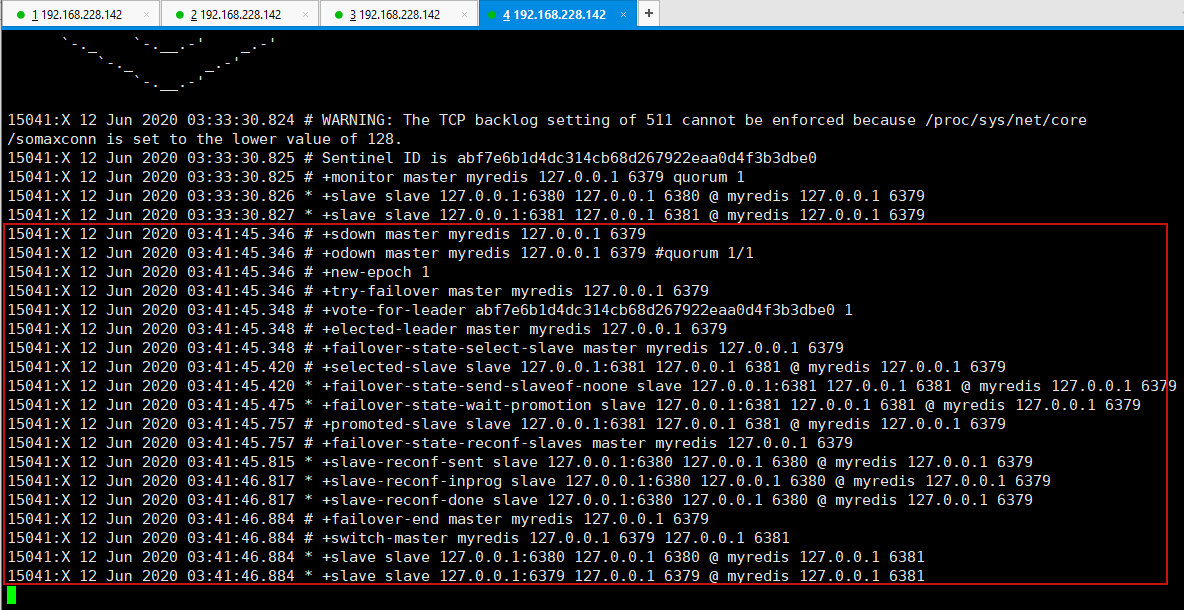
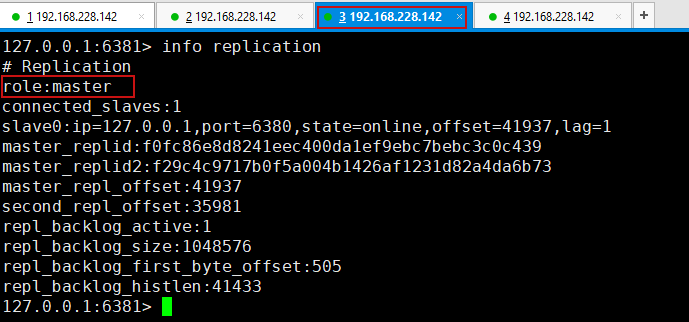
如果之前的主机6379又重新启动了,过一会,哨兵检测到了之后,会把6379设置为从机!
哨兵模式的优缺点
优点
1.哨兵集群模式是基于主从模式的,所有主从的优点,哨兵模式同样具有。
2.主从可以切换,故障可以转移,系统可用性更好。
3.哨兵模式是主从模式的升级,系统更健壮,可用性更高。
缺点
1.Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
2.实现哨兵模式的配置也不简单,甚至可以说有些繁琐
十三、Redis缓存穿透,击穿,雪崩,倾斜
1.1 缓存穿透(查不到)
概念:当用户去查询数据的时候,发现redis内存数据库中没有,于是向持久层数据库查询,发现也没有,于是查询失败,当用户过多时,缓存都没有查到,于是都去查持久层数据库,这会给持久层数据库造成很大的压力,此时相当于出现了缓存穿透。
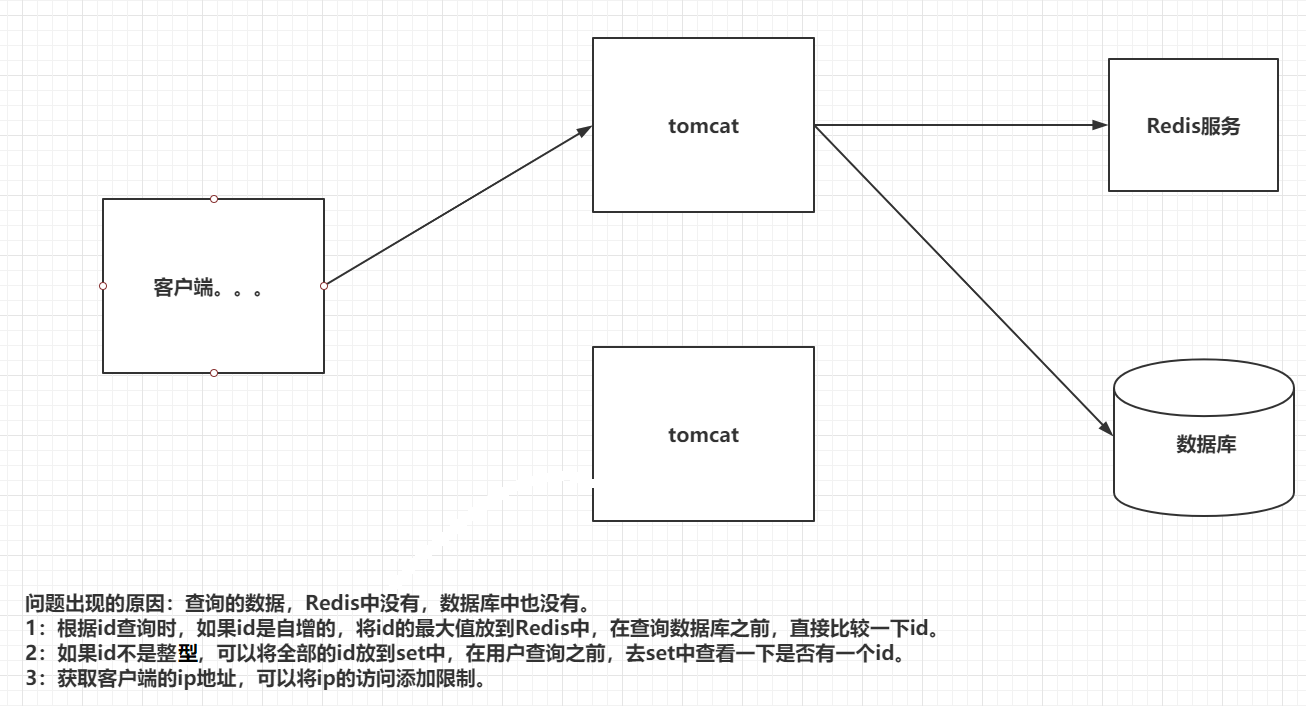
解决方案:
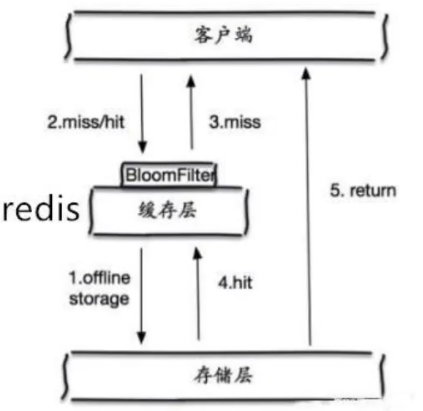
1.布隆过滤器:是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的压力,但是,布隆过滤器有误差,说myql 有该id ,不一定有,说myql 没有该id,一定没有 !
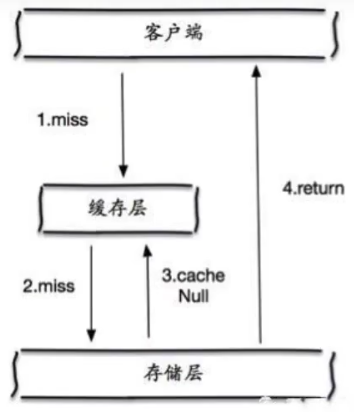
2.缓存空对象:当存储层查不到时,即使返回的空对象也将其缓存起来,同时设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护后端数据.
但会有两个问题:
1.如果空值被缓存起来,就意味着需要更多的空间存储更多的键,会有很多空值的键.
2.即使对空值设置了过期时间,还是会存在 缓存层和存储层会有一段时间窗口不一致,这对于需要保持一致性的业务会有影响.
1.2 缓存击穿(访问量大,缓存过期)
指对某一个key的频繁访问,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就会直接请求数据库,就像在一个屏障上凿开了一个洞,例如微博由于某个热搜导致宕机.
其实就是:当某个key在过期的瞬间,有大量的请求并发访问,这类数据一段是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并回写缓存,导致数据库瞬间压力过大。
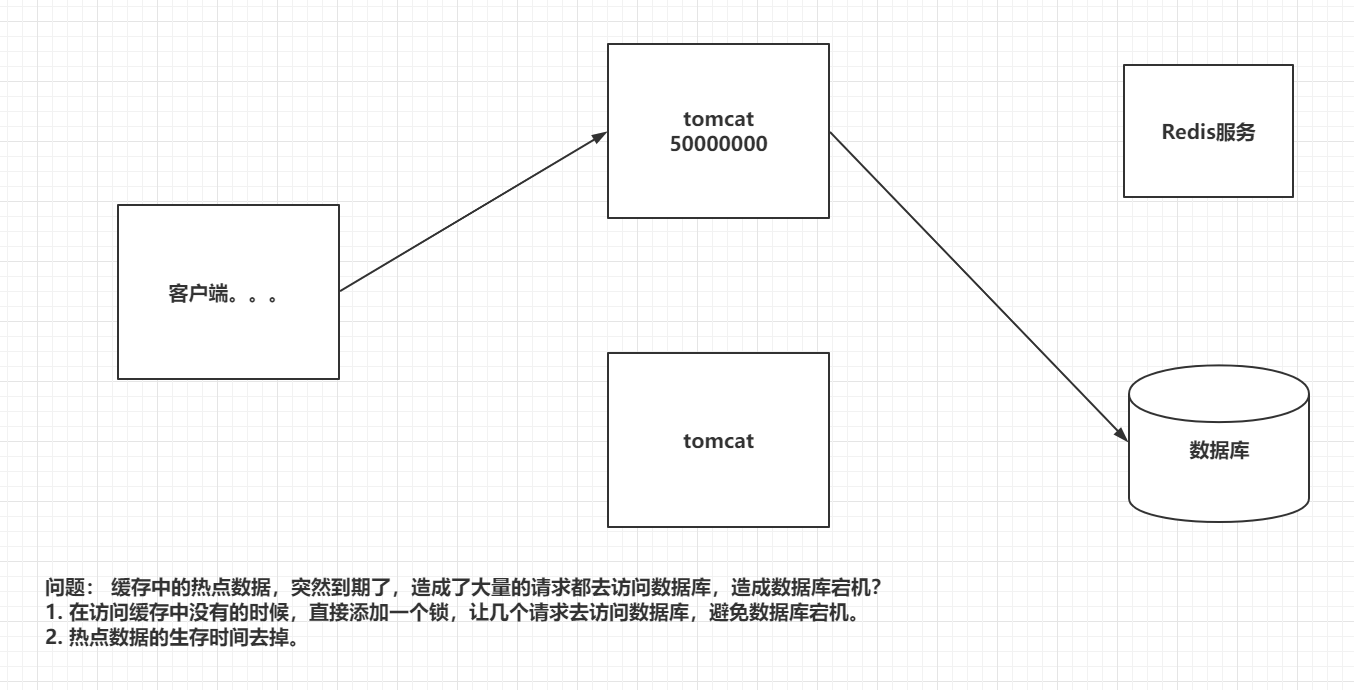
解决方案:
1.设置热点数据永不过期:从缓存层面上来说,不设置过期时间,就不会出现热点key过期后产生的问题.
2.添加互斥锁:使用分布式锁,保证对每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可,这种方式将高并发的压力转移到了分布式锁上,对分布式锁也是一种极大的考验.
1.3 缓存雪崩
指在某一个时间段,缓存集中过期失效或Redis宕机导致的,例如双十一抢购热门商品,这些商品都会放在缓存中,假设缓存时间为一个小时,一个小时之后,这些商品的缓存都过期了,访问压力瞬间都来到了数据库上,此时数据库会产生周期性的压力波峰,所有的请求都会到达存储层,存储层的调用量暴增,造成存储层挂掉的情况.
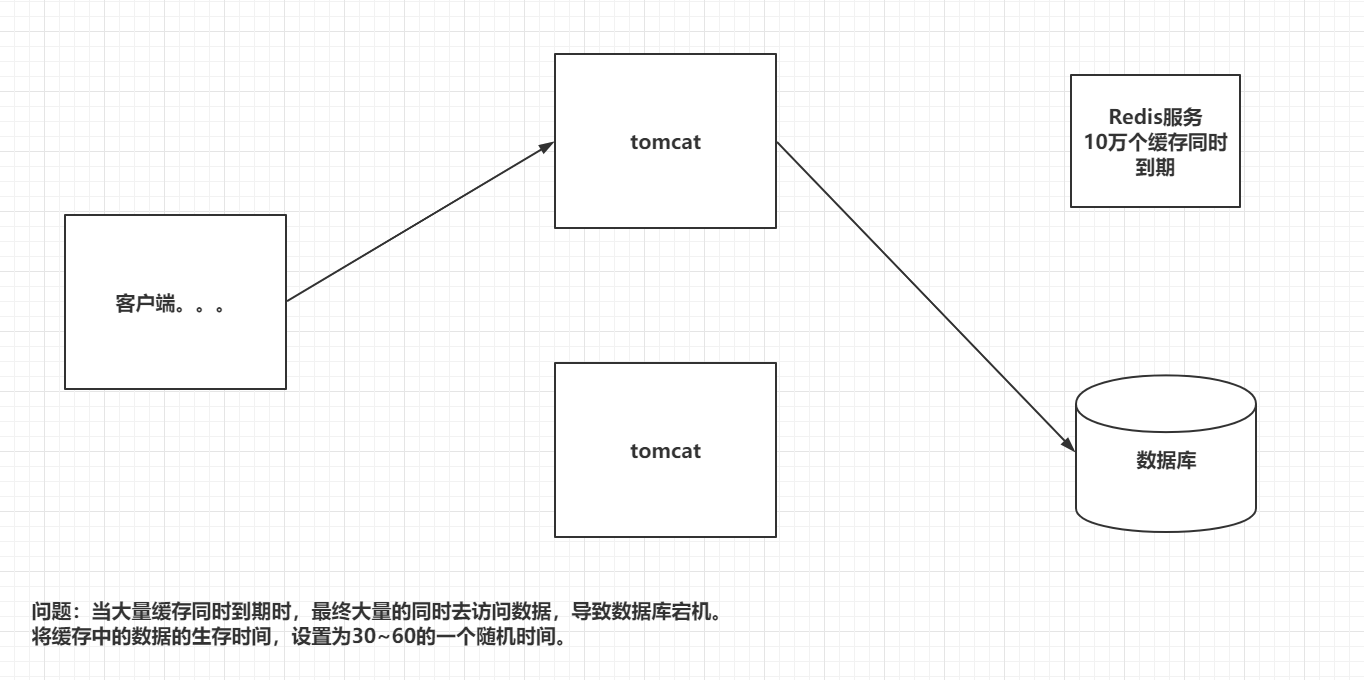
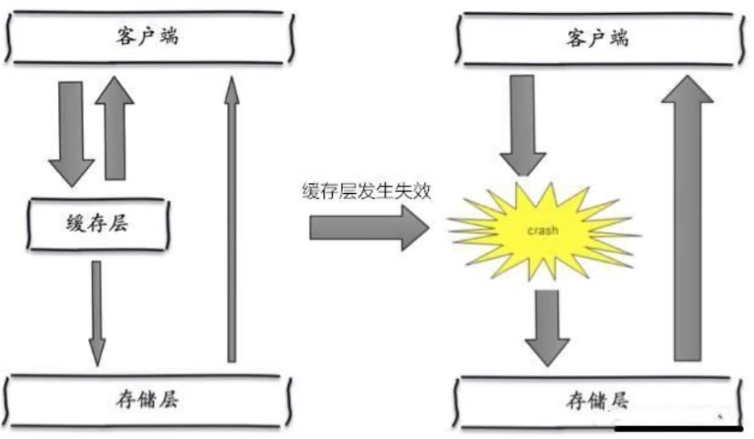
其实比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网,因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,此时的数据库还是可以顶住压力的,而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,有可能瞬间就把服务器压垮.
解决方案:
1.配置Redis的高可用:其实就是搭建集群环境,有更多的备用机.
2.限流降级:在缓存失效后,通过加锁或者队列来控制读服务器以及写缓存的线程数量,比如对某个key只允许一个线程查询数据和写缓存,其他线程等待.
3.数据预热:在项目正式部署之前,把可能用的数据预先访问一边,这样可以把一些数据加载到缓存中,在即将发生大并发访问之前手动触发加载缓存中不同的key,设置不同的过期时间,让缓存失效的时间尽量均衡.
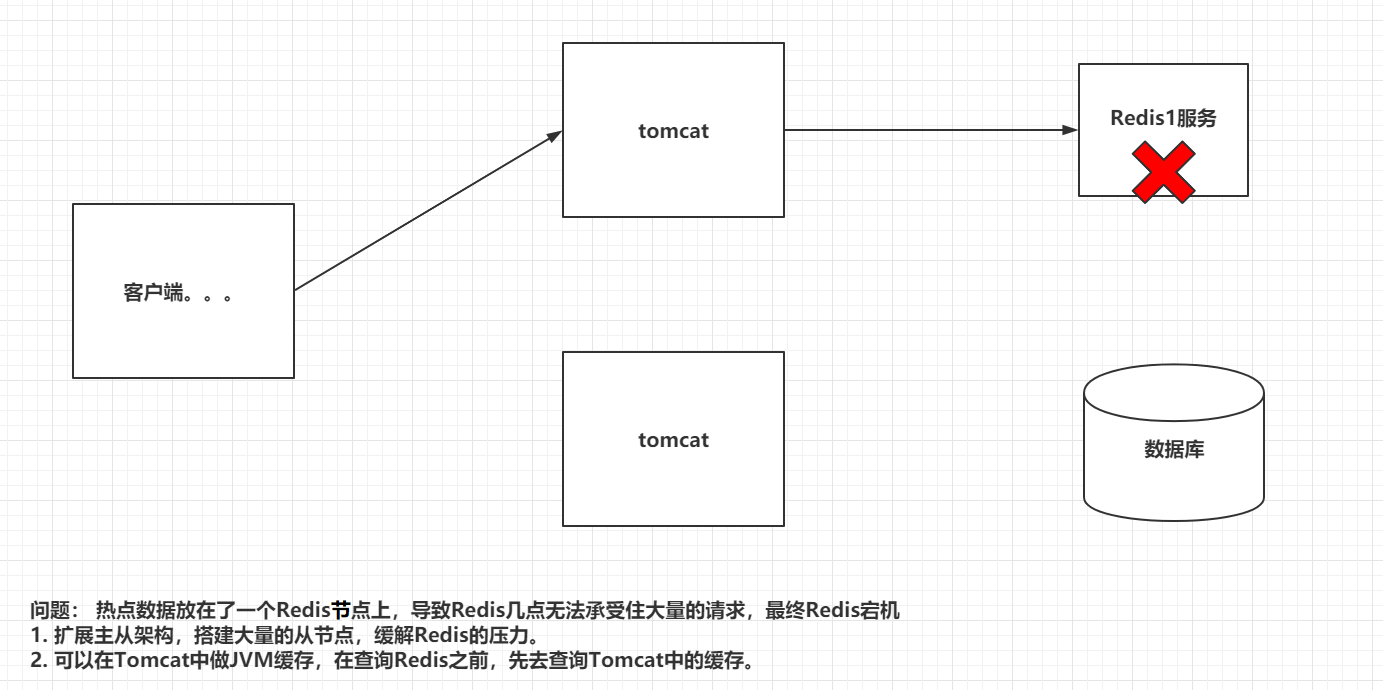
1.4 缓存倾斜
指某一台redis服务器压力过大而导致该服务器宕机.
十四、Redis集群搭建(自己动手,丰衣足食)

十五、Redis其他常见问题
1.key的生存时间到了,Redis会立即删除吗?
不会立即删除
1.1定期删除:Redis每隔一段时间就去会去查看Redis设置了过期时间的key,会再100ms的间隔中默认查看3个key。
1.2惰性删除:如果当你去查询一个已经过了生存时间的key时,Redis会先查看当前key的生存时间,是否已经到了,直接删除当前key,并且给用户返回一个空值。
2.Redis的淘汰机制
在Redis内存已经满的时候,添加了一个新的数据,执行淘汰机制。(redis.conf中配置)
2.1 volatile-lru:在内存不足时,Redis会在设置过了生存时间的key中干掉一个最近最少使用的key。
2.2 allkeys-lru:在内存不足时,Redis会在全部的key中干掉一个最近最少使用的key。
2.3 volatile-lfu:在内存不足时,Redis会在设置过了生存时间的key中干掉一个最近最少频次使用的key。
2.4 allkeys-lfu:在内存不足时,Redis会在全部的key中干掉一个最近最少频次使用的key。
2.5 volatile-random:在内存不足时,Redis会在设置过了生存时间的key中随机干掉一个。
2.6 allkeys-random:在内存不足时,Redis会在全部的key中随机干掉一个。
2.7 volatile-ttl:在内存不足时,Redis会在设置过了生存时间的key中干掉一个剩余生存时间最少的key。
2.8 noeviction:(默认)在内存不足时,直接报错。
方案:指定淘汰机制的方式:maxmemory-policy具体策略,设置Redis的最大内存:maxmemory 字节大小

 浙公网安备 33010602011771号
浙公网安备 33010602011771号