XML, HTTP协议, Web Application
1. XML文件
1.1 XML 概述
可扩展标记语言(英语:Extensible Markup Language,简称:XML)是一种标记语言。XML是从标准通用标记语言(SGML)中简化修改出来的。它主要用到的有可扩展标记语言、可扩展样式语言(XSL)、XBRL和XPath等。
XML 文件标签可以自定义,但是有严格的语法要求和规范!!! 在 JavaWEB 项目开发中,XML文件常用于配置文件使用,例如
Spring SpringMVC MyBatis
XML文件学习目标,能够看懂,可以按照规范书写,其他不考虑
学习
Servlet 规范 XML 文件配置
<servlet-name></servlet-name>
<servlet-class></servlet-class>
Spring 规范 XML 文件配置
SpringMVC 规范 XML 文件配置
MyBatis 规范 XML 文件配置
1.2 XML文件案例
<?xml version="1.0" encoding="utf-8"?>
<!--
<?xml 内容?>
XML 文件声明,可以用于声明,当前文件的版本号,对应解释使用编码集,引入的第三方约束或者依赖
-->
<students>
<student id="001">
<name>强哥</name>
<age>18</age>
<gender>男</gender>
<address>
<province>河南</province>
<city>郑州</city>
<area>二七区</area>
</address>
</student>
<student id="002">
<name>王某平</name>
<age>88</age>
<gender>男</gender>
<address>
<province>河南</province>
<city>郑州</city>
<area>二七区</area>
</address>
</student>
<student id="003">
<name>王乾</name>
<age>77</age>
<gender>男</gender>
<address>
<province>河南</province>
<city>郑州</city>
<area>二七区</area>
</address>
</student>
</students>
1.3 自定义 XML 文件注意事项
1. XML 文件中有且只有一个根节点,出现多个,解析失败!
2. XML 文件自定义标签必须有头有尾,标签名不匹配报错,严格区分大小写
<name>王乾</name>
<age>77</age>
<gender>男</gender>
3. XML 文件标签可以自定义属性,并且允许多个
<student id="003"> ... </student>
<employee id="QF000574" dept="1" managerId="QF000150"></employee>
4. XML 文件标签分类
a. 文本标签
<name>王乾</name>
b. 属性标签
id="003"
c. 根标签
<students>...</students>
5. XML 文件允许多层嵌套
<address>
<province>河南</province>
<city>郑州</city>
<area>二七区</area>
</address>
1.4 XML文件 Java 解析【了解】
Java 需要按照规范读取解析 XML 文件内容,一般 XML 文件内容用于配置文件。
Java 原码/ SUN 公司实际上是提供了关于 XML 文件解析的方式和方法,但是 忒垃圾了。。。效率不高,操作繁琐,使用麻烦,啥也不是。社区有大佬忍不住了!!!什么垃圾,我自己写一个。于是乎就有了大量的第三方工具
Dom4j ==> DOM for Java 其他的第三方 Jar 包 log4j
DOM Document Object Model 文档对象模型
Dom4j 解析 XML 文件工具 内置于 Spring SpringMVC MyBatis 框架中。
第一种方式:
DOM解析
整个XML 文件看做是一个 Document 对象,可以完成针对于 XML 文件的读取,解析,写入,保存操作
对内存需求较大,需要将整个XML文件读取到内存中才可以使用,服务器解析XML常用
第二种方式:
SAX解析
读取一行数据,解析一行数据,有且只有对于 XML 文件读取和解析能力,不具备修改和写入能力
内存占用较低,效率略高,一般用于手机 XML文件解析过程。
1.5 Dom4j 解析 XML 文件演示【了解】
package com.qfedu.a_xml;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
/**
* @author Anonymous 2022/4/13 10:13
*/
public class Demo1 {
public static void main(String[] args) throws DocumentException {
// 1. 创建 Dom4j 解析 XML 文件核心类 SAXReader
SAXReader saxReader = new SAXReader();
// 2. 通过目标 XML 文件路径得到 Document 对象
Document document = saxReader.read(new File("./data/student.xml"));
String path ="G:\\JavaEE2203\\IDEAProject\\Day37_IDEA_XML_GL\\data\\student.xml";
/*
3. 获取 XML 文件根节点
通过 Document 对象 利用 getRootElement() 获取 Element 对象 ==> 特指根节点
*/
Element rootElement = document.getRootElement();
System.out.println(rootElement);
/*
通过 根节点 对象获取包含的子节点内容
Element element(String elementName);
根据 子节点 标签名获取第一个对应名称节点对象
List elements();
获取当前节点下的所有子节点
List elements(String elementName);
获取当前节点下指定名称的所有子节点
tips: 以上两个方法, 如果没有对应数据,得到的是一个空List集合
*/
Element stu1 = rootElement.element("student");
System.out.println("--------------------------------");
@SuppressWarnings("unchecked")
List<Element> list1 = rootElement.elements();
list1.forEach(System.out::println);
System.out.println("--------------------------------");
@SuppressWarnings("unchecked")
List<Element> list2 = rootElement.elements("student");
list2.forEach(System.out::println);
System.out.println("--------------------------------");
@SuppressWarnings("unchecked")
List<Element> list3 = rootElement.elements("info");
list3.forEach(System.out::println);
@SuppressWarnings("unchecked")
List<Element> list4 = rootElement.elements("worker");
System.out.println(list4);
list4.forEach(System.out::println);
System.out.println("--------------------------------");
// 操作 id=001 的学生节点
@SuppressWarnings("unchecked")
List<Element> elements = stu1.elements();
for (Element element : elements) {
if ("address".equals(element.getName())) {
// getName 是获取 XML 节点名称
System.out.println(element.getName());
@SuppressWarnings("unchecked")
List<Element> addrDetail = element.elements();
for (Element element1 : addrDetail) {
// getText 获取 XML 节点文本数据
System.out.println(element1.getName() + " : " + element1.getText());
}
// 结束本次循环执行内容,直接进入下一次循环
continue;
}
System.out.println(element.getName() + " : " + element.getText());
}
System.out.println("--------------------------------");
/* continue 语法
for (int i = 0; i < 10; i++) {
if (i % 2 == 0) {
continue;
}
System.out.println(i);
}
*/
/*
操作 id=001 的学生节点
List attributes();
Attribute attribute(String attrName);
*/
@SuppressWarnings("unchecked")
List<Attribute> attributes = stu1.attributes();
/*
Attribute
getName(); 获取属性名
getValue(); 获取属性值
*/
attributes.forEach(a -> System.out.println(a.getName() + ":" + a.getValue()));
}
}
1.6 XPath语法【了解】
package com.qfedu.a_xml;
import org.dom4j.*;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
/**
* XPath
* XML在洪荒年代也是一个小型数据库!!!
* @author Anonymous 2022/4/13 11:35
*/
public class Demo2 {
@SuppressWarnings("unchecked")
public static void main(String[] args) throws DocumentException {
// 读取 XML 文件,并且得到 rootElement 根节点
Document document = new SAXReader().read(new File("./data/student.xml"));
Element rootElement = document.getRootElement();
// //city 不考虑节点的深度,查询所有的 city 节点
List<Element> list = rootElement.selectNodes("//city");
list.forEach(s -> System.out.println(s.getText()));
// //@id 不考虑节点深度,查询所有的 id 属性
List<Attribute> list1 = rootElement.selectNodes("//@id");
list1.forEach(attribute -> System.out.println(attribute.getName() + ":" + attribute.getValue()));
// /students//student[1] 在 students 节点下,不考虑节点深度找到第一个 Student 节点,XML 文件下标规则从 1 开始
List<Element> list2 = rootElement.selectNodes("/students//student[1]");
list2.forEach(e -> System.out.println(e.attribute("id").getValue()));
// /students//student[last()] 在 students 节点下,不考虑节点深度找到最后 Student 节点
List<Element> list3 = rootElement.selectNodes("/students//student[last()]");
list3.forEach(e -> System.out.println(e.attribute("id").getValue()));
// /students//student[age < 20] 在 students 节点下,不考虑节点深度找到 Student 节点。找出学生年龄小于20的
List<Element> list4 = rootElement.selectNodes("/students//student[age < 20]");
list4.forEach(e -> System.out.println(e.attribute("id").getValue()));
// /students//student[@id=001] 在 students 节点下,不考虑节点深度找到 Student 节点。找出 id 为 001 的学生
List<Element> list5 = rootElement.selectNodes("/students//student[@id=001]");
list5.forEach(e -> System.out.println(e.attribute("id").getValue()));
}
}
XPath 语法教程
2. HTTP协议
2.1 HTTP协议概述
超文本传输协议(英语:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网的数据通信的基础。
Java WEB Application 阶段,保证数据从前端到后台之间的交互所需依赖的协议内容。
HTTP协议中关注的内容
【报表】 一组键值对数据
请求头 ==> Java EE 规范中 Request(请求) 对象
响应头 ==> Java EE 规范中 Response(响应) 对象
2.2 常规数据信息
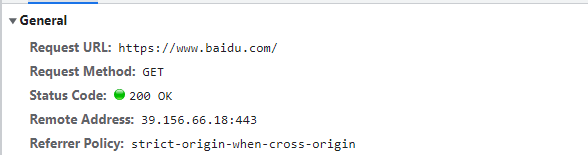
![]()
# Request URL 请求目标地址,可以是 域名 IP地址 主机名 目标数据地址为 https://www.baidu.com/
Request URL: https://www.baidu.com/
# Request Method 数据请求的方式 目前采用的形式为 GET 形式
Request Method: GET
# Status Code 状态码 1XX 2XX 3XX 4XX 5XX 200 OK You like it 做JavaWEB心态放平,不要薅头发!!!
Status ·Code: 200 OK
# Remote Address 目标资源的 IP 地址和对应端口号
Remote Address: 39.156.66.18:443
Referrer Policy: strict-origin-when-cross-origin
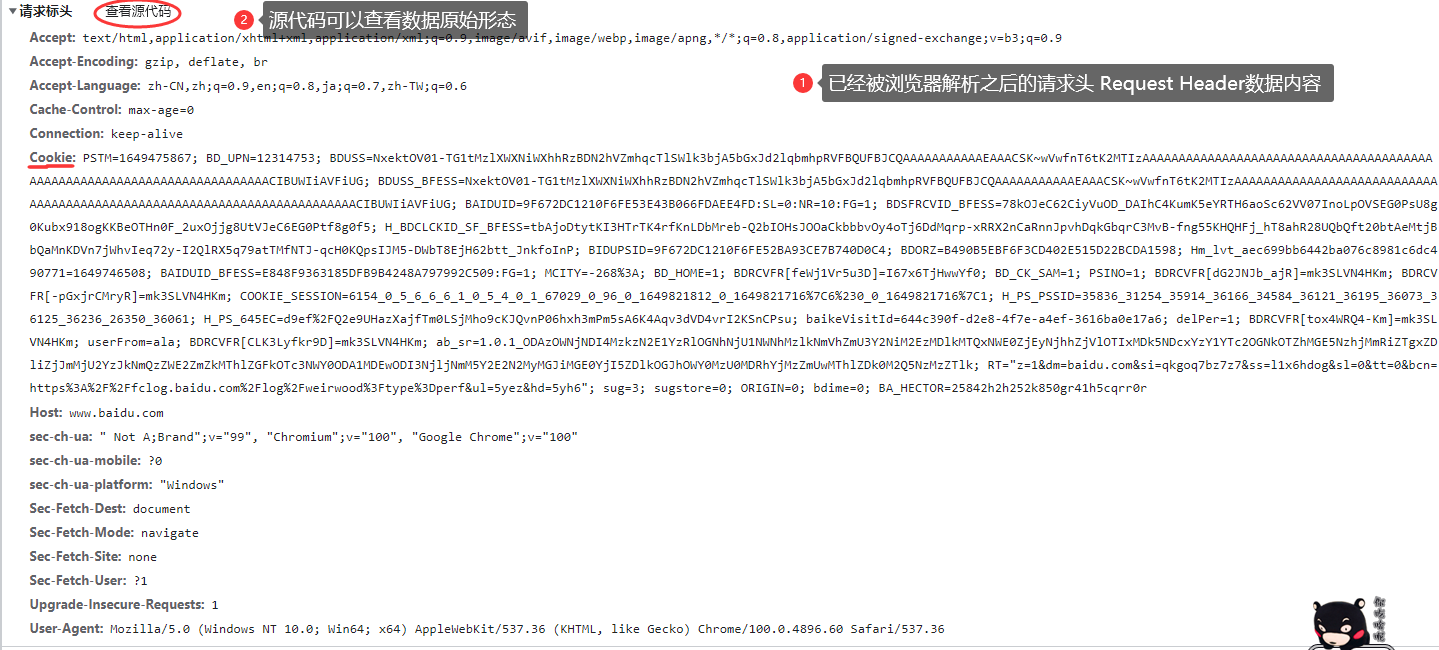
![]()
# GET 当前请求方式为 GET 请求,
# / 请求资源为当前项目根目录主页资源
# HTTP/1.1 网络数据交互对应的协议版本
GET / HTTP/1.1
# Accept 告知服务器当前浏览器可以接受的数据形式有哪些
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
# Accept-Encoding HTTP协议声明浏览器支持的编码类型 gzip br 数据压缩格式
Accept-Encoding: gzip, deflate, br
# Accept-Language HTTP协议声明浏览器目前支持的语言形式
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,ja;q=0.7,zh-TW;q=0.6
# Cache-Control 缓冲控制/缓存控制 max-age=0 表示当前资源不缓冲/缓存
Cache-Control: max-age=0
# Connection HTTP协议表明目前浏览器和服务器的连接状态 keep-alive 保持连接状态
Connection: keep-alive
# Cookie 会话控制技术【重点】,浏览器保存和服务器交互数据的聊天记录 cookie 数据形式为键值对形式不支持中文,
# 容量限制,可以记录用户上一次登陆的IP地址,用户登陆信息
# PSTM=1649475867
# PSTM CookieName 百度自行规定的 Cookie 名称
# 1649475867 CookieValue 对应数据,数据具体看业务逻辑,现在与你无关
Cookie: PSTM=1649475867; BD_UPN=12314753;
# 目标资源的域名,IP地址,主机名
Host: www.baidu.com
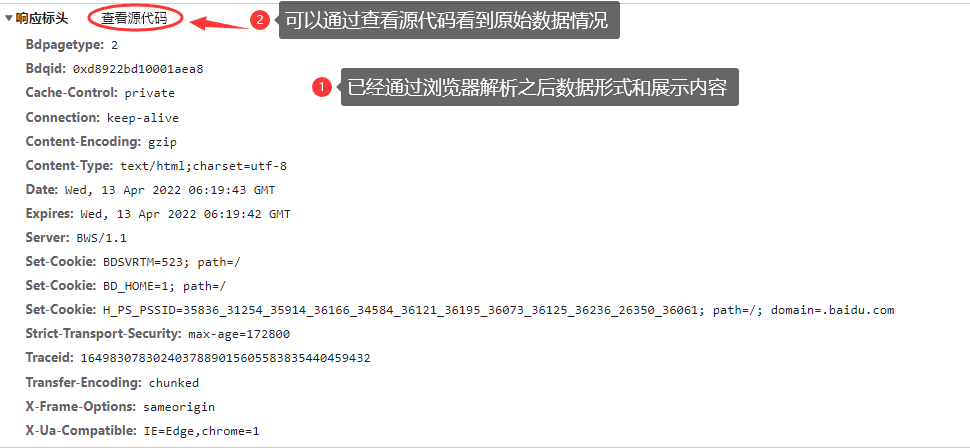
![]()
# 服务器给予客户端响应数据协议采用 HTTP/1.1 状态 200 OK 网络请求响应一切正常!!!
HTTP/1.1 200 OK
# Cache-Control 缓冲控制 private 不缓冲
Cache-Control: private
# Connection 服务器浏览器连接状态 keep-alive 保持连接
Connection: keep-alive
# Content-Encoding 响应给予浏览器的编码类型
Content-Encoding: gzip
# Content-Type 响应给予浏览器数据的形式 采用的形式为 text/html 可视化文本文件,编码集采用 UTF-8
Content-Type: text/html;charset=utf-8
# 响应时间日期 采用的时间标准是 格林威治标准时间
Date: Wed, 13 Apr 2022 07:15:08 GMT
# 请求缓冲有效时间限制
Expires: Wed, 13 Apr 2022 07:15:07 GMT
# 响应资源字节数
content—length: 100000000
# 目前资源的存在时间
age: 110414;
# 资源允许的最长时间 【重复】
Cache-Control: 2598000
# Server 服务器信息 BWS/1.1
Server: BWS/1.1
# 服务器给予 浏览器的 Cookie 要求 浏览器保存 Cookie 数据都是键值对形式 path 是cookie 有效资源路径
Set-Cookie: BDSVRTM=493; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=35836_31254_35914_36166_34584_36121_36195_36073_36125_36236_26350_36061; path=/; domain=.baidu.com
2.5 请求响应和 JavaWEB 的关系
请求 ==> 通过 HTTP 协议的 请求头进行数据提交。目标位置是服务器。在服务器上Tomcat 会根据当前用户的请求内容,信息,创建一个 Request 请求对象,存储用户提交的数据内容
用户请求 ==> HTTP 协议 ==> 请求头 ==> JavaWEB服务器 Request 对象
在 JavaWEB 服务器上 Request 对象可以获取用户请求的所有数据内容。
响应 ==> 服务器按照用户请求的 Request 对象,会随之匹配对应的 Response 响应对象。在 Response 对象中,服务器可以存储给予浏览器的数据内容,符合 HTTP 协议,浏览器就可以解析数据内容
3. 第一个 Java Web Application
3.1 Servlet 【重点,难点,细节点】
Servlet(Server Applet),全称Java Servlet。是用Java编写的服务器端程序。其主要功能在于交互式地浏览和修改数据,生成动态Web内容。狭义的Servlet是指Java语言实现的一个接口,广义的Servlet是指任何实现了这个Servlet接口的类,一般情况下,人们将Servlet理解为后者。
Servlet运行于支持Java的应用服务器中。从实现上讲,Servlet可以响应任何类型的请求,但绝大多数情况下Servlet只用来扩展基于HTTP协议的Web服务器。
最早支持Servlet标准的是JavaSoft的Java Web Server。此后,一些其它的基于Java的Web服务器开始支持标准的Servlet。
Servlet 是整个 JavaWEB 项目的核心内容!!!Servlet 操作的
核心方法参数
HttpServletRequest 符合 HTTP 协议并且基于 JavaEE Servlet 规范的 Request 请求对象
HttpServletResponse 符合 HTTP 协议并且基于 JavaEE Servlet 规范的 Response 响应对象
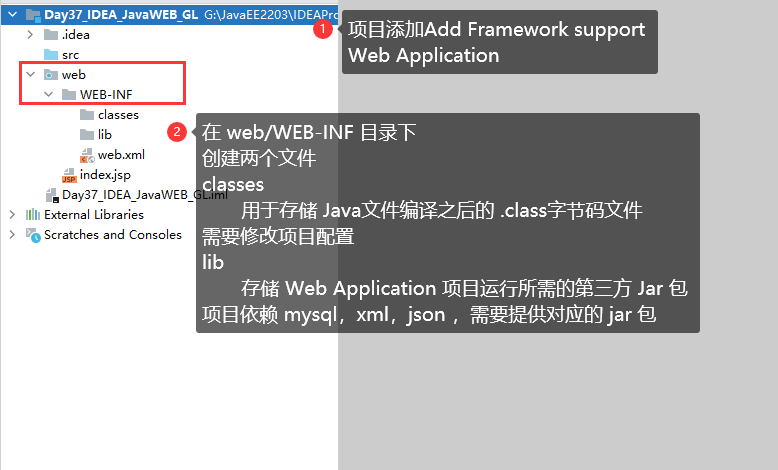
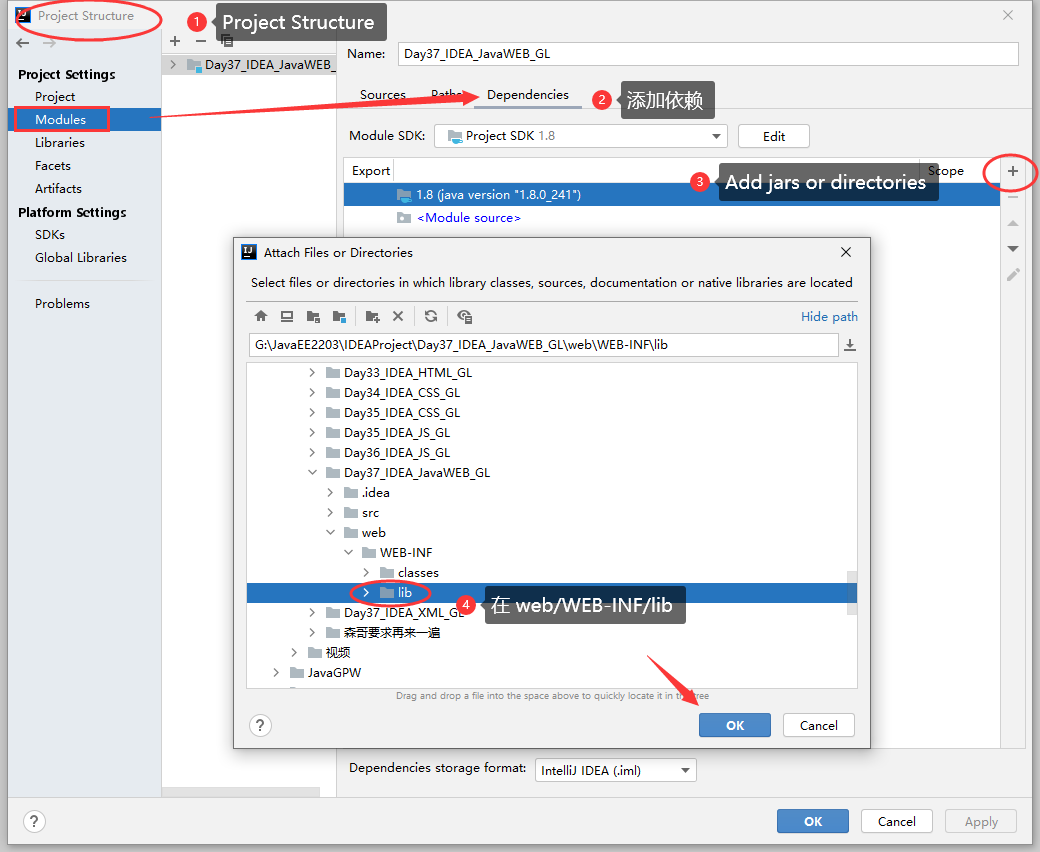
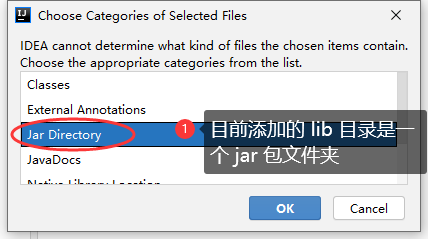
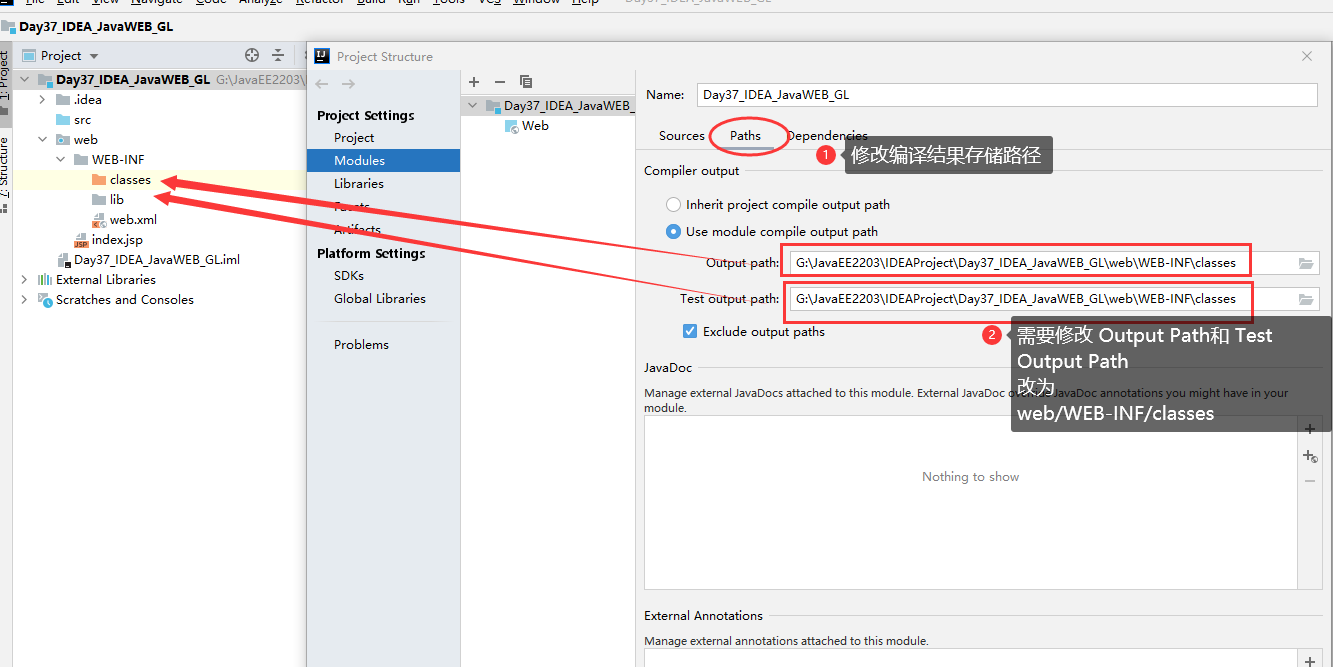
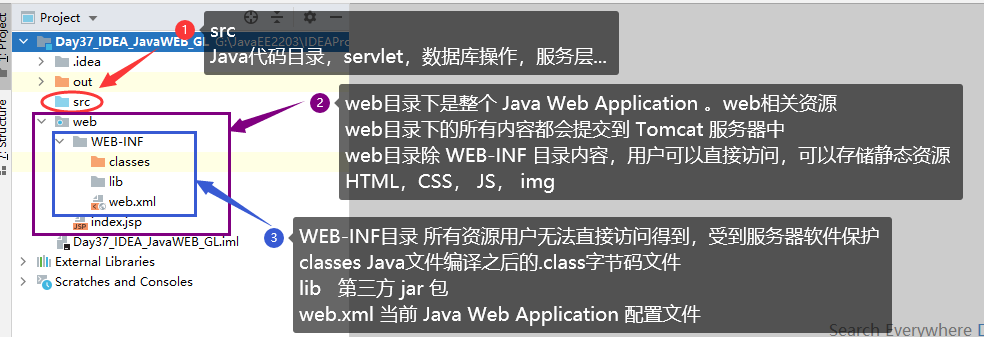
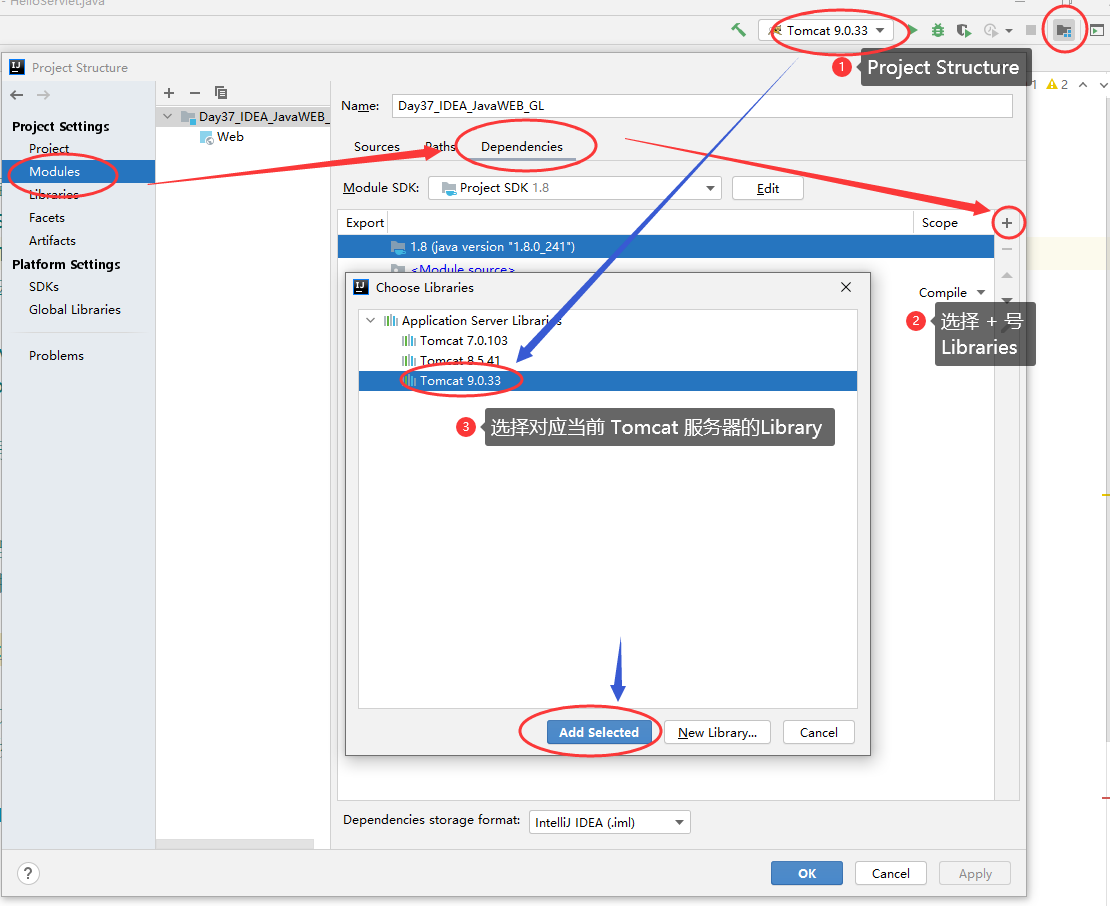
3.2 IDEA 创建 JavaWEB 项目,配置和项目结构解释
![]()
![]()
![]()
![]()
![]()
3.3 Hello Servlet【今天必须保证可以运行】
自定义实现 Servlet 程序流程
1. 自定义类 extends HttpServlet
HttpServlet 是符合 HTTP 协议和 JavaEE 规范要求 Servlet 标准一个类,里面有一些可以用于自定义实现
Servlet 程序的重写方法
【问题】
发现 HttpServlet 对应类无法导包,IDEA 提示需要创建!!!
我们需要让 Tomcat 提供 HttpServlet 类
【解决】
需要在项目中导入 Tomcat Web 项目依赖,提供 JavaWEB 项目必要的 Servlet 实现
2. 注册资源名称
告知 Tomcat 服务器,当前 Servlet 程序的资源名称是什么,用户请求当前资源对应 url 资源名称。资源名称
在一个 Tomcat 服务器中唯一
注解方式
@WebServlet("/helloServlet")
3. 重写 doGet 和 doPost 方法
doGet 对应用户 HTTP 协议的 GET 请求
doPost 对应用户 HTTP 协议的 POST 请求
void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException
void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException
4. 启动项目
小甲虫,Debug 启动
5. 浏览器资源访问
http://localhost:8080/Day37/helloServlet
![]()
package com.qfedu.a_servlet;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* 自定义实现 Servlet 程序流程
* 1. 自定义类 extends HttpServlet
* HttpServlet 是符合 HTTP 协议和 JavaEE 规范要求 Servlet 标准一个类,里面有一些可以用于自定义实现
* Servlet 程序的重写方法
* 【问题】
* 发现 HttpServlet 对应类无法导包,IDEA 提示需要创建!!!
* 我们需要让 Tomcat 提供 HttpServlet 类
* 【解决】
* 需要在项目中导入 Tomcat Web 项目依赖,提供 JavaWEB 项目必要的 Servlet 实现
*
* 2. 注册资源名称
* 告知 Tomcat 服务器,当前 Servlet 程序的资源名称是什么,用户请求当前资源对应 url 资源名称。资源名称
* 在一个 Tomcat 服务器中唯一
* 注解方式
* @WebServlet("/helloServlet")
*
* 3. 重写 doGet 和 doPost 方法
* doGet 对应用户 HTTP 协议的 GET 请求
* doPost 对应用户 HTTP 协议的 POST 请求
* void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException
* void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException
*
* 4. 启动项目
* 5. 浏览器资源访问
* http://localhost:8080/Day37/helloServlet
* @author Anonymous 2022/4/13 17:13
*/
@WebServlet("/helloServlet")
public class HelloServlet extends HttpServlet {
/*
doGet和doPost参数中的 HttpServletRequest, HttpServletResponse
是 Tomcat 服务器针对于用户请求自动生成,提供给用户使用
*/
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
System.out.println("---------------- 用户请求 helloServlet ----------------");
// 给予用户响应,响应内容是 HTML 文本内容 利用 getWriter().append() 发送给用户
resp.getWriter().append("<h1>Hello Servlet!!!!</h1>");
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 调用当前类内的 doGet 方法,将用户 POST 和 GET 数据统一处理
doGet(req, resp);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号