LinkedList、Set和Map
目录
LinkedList,Set和Map
1. LinkedList
1.1 LinkedList 介绍
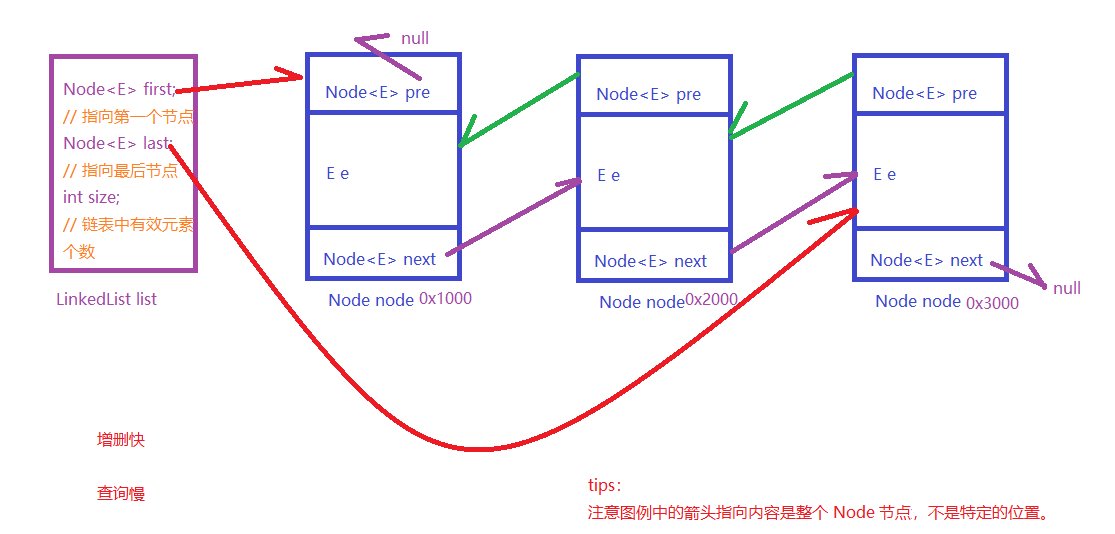
底层数据存储结构为双向链表
链表头:
class LinkedList<E> {
Node<E> first;
Node<E> last;
int size;
}
Node 是 LinkedList 内部类!!!
节点 Node<E>
class Node<E> {
Node<E> previous; // 引用 指向前一个节点 Node 引用
E e;
Node<E> next; // 引用 指向后一个节点 Node 引用
}
1.2 图例分析 LinkedList
1.3 重要方法演示
package com.qfedu.a_linkedlist;
import java.util.LinkedList;
/*
* LinkedList<E> 方法演示
*
* addFirst(E e); 添加元素到头节点之前
* addLast(E e); 添加元素到尾节点之后
* E getFirst(); 获取头节点元素
* E getLast(); 获取尾节点元素
* E removeFirst(); 删除头节点元素,返回值是头节点元素数据内容
* E removeLast(); 删除尾节点元素,返回值是尾节点元素数据内容
*/
public class Demo1 {
public static void main(String[] args) {
LinkedList<String> list1 = new LinkedList<String>();
list1.add("胡辣汤");
list1.add("小米粥");
list1.add("豆腐脑");
list1.add("两掺");
System.out.println(list1);
list1.addLast("牛肉包子");
list1.addFirst("牛肉肉盒");
System.out.println(list1);
System.out.println(list1.getFirst());
System.out.println(list1.getLast());
System.out.println(list1.removeFirst());
System.out.println(list1.removeLast());
System.out.println(list1);
}
}
2. Set
2.1 Set集合概述
特征:
无序 数据存储顺序和添加顺序不一致。
不可重复 要求元素存储不允许出现相同元素,如果添加相同元素,add方法返回值为 false
Set集合没有特征方法,使用的方法都是 Collection 方法
class HashSet<E>
class TreeSet<E>
package com.qfedu.b_set;
import java.util.HashSet;
public class Demo1 {
public static void main(String[] args) {
HashSet<Integer> set = new HashSet<Integer>();
/*
* 无序 : 数据存储顺序和添加顺序不一致。
*/
set.add(2);
set.add(6);
set.add(1);
set.add(4);
set.add(5);
set.add(3);
System.out.println(set);
HashSet<String> set2 = new HashSet<String>();
set2.add("羊肉汤");
set2.add("烩面");
set2.add("牛肉面");
set2.add("葱油拌面");
set2.add("炒拉条");
/*
* 不可重复,要求元素存储不允许出现相同元素,如果添加相同元素,add方法返回值为 false
*/
System.out.println(set2.add("油泼面"));
System.out.println(set2.add("油泼面"));
System.out.println(set2);
}
}
2.2 HashSet 存储流程概述分析
底层数据存储结构为 哈希表结构 ==> 简单来看就是一个 Excel 表格。
HashSet 存储数据主要有两个过程
1. 通过添加元素的 hashCode 方法获取添加元素的 哈希值,通过 哈希运算 计算当前元素应该在哈希表中对应单元格位置
2. 如果对应单元格存在其他元素,需要通过调用 equals 方法判断两个元素是否同一个元素,如果是同一个元素,后者无法添加,如果不一致,可以存储。
package com.qfedu.b_set;
import java.util.HashSet;
public class Demo2 {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<Person>();
/*
* 执行添加方法,都会自动调用添加元素的 hashCode 方法
*/
set.add(new Person(1, "张三", 26));
set.add(new Person(2, "李四", 26));
set.add(new Person(3, "王乾", 96));
set.add(new Person(4, "王某平", 86));
set.add(new Person(5, "玮豪哥哥", 76));
set.add(new Person(6, "周董", 66));
/*
* 第二次添加 new Person(6, "周董", 66)
* 在当前 Set 集合中有相同元素,添加失败。
* 1. 添加元素过程中,调用hashCode方法,计算对应单元格位置,发现对应单元格有之前添加的元素
* 2. 调用添加元素的 equals 方法,和之前元素比较,如果比较结果为同一个元素,根据 Set 集合规则
* 无法存在相同元素,添加失败
*/
set.add(new Person(6, "周董", 66));
Person p1 = new Person(6, "周董", 66);
Person p2 = new Person(6, "周董", 66);
System.out.println(p1.hashCode());
System.out.println(p2.hashCode());
System.out.println(set);
System.out.println(set.size());
}
}
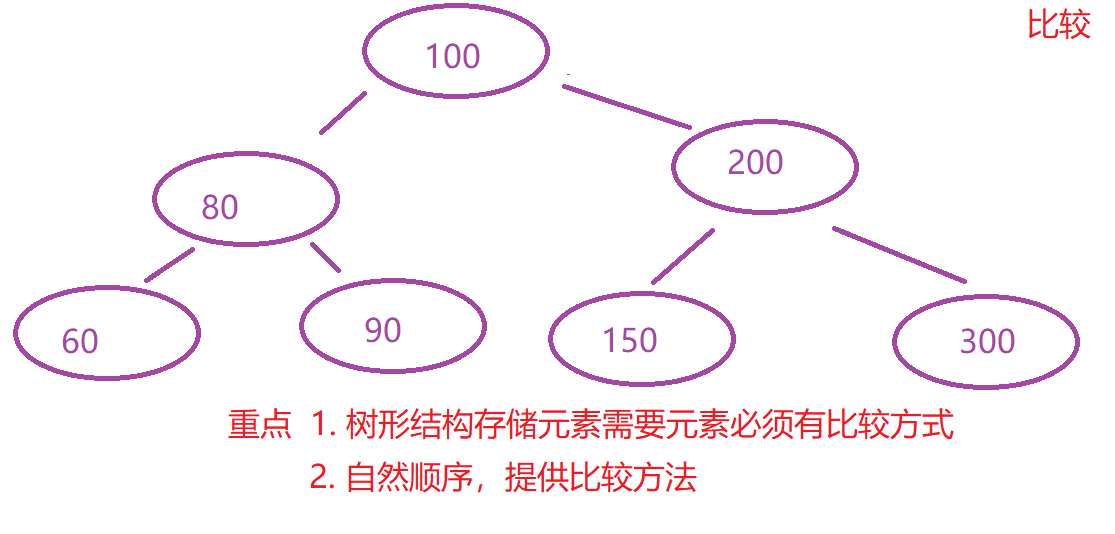
2.3 TreeSet 结构分析和存储数据要求
package com.qfedu.b_set;
/*
* 自定义类遵从 Comparable 接口,增强为一个可比较类!!!
* 采用的遵从方式是【妻管严模式】在遵从接口的过程中,直接明确当前泛型约束
* 数据类型为 SingleDog 类型,当前类为 SingleDog 所需进行比较的类型
* 也是对应 SingleDog 类型,非其他类型。
*/
public class SingleDog implements Comparable<SingleDog> {
private int id;
private String name;
private int age;
public SingleDog() {
}
public SingleDog(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "SingleDog [id=" + id + ", name=" + name + ", age=" + age + "]";
}
/*
* 遵从 Comparable<T> 接口要求实现的方法
* 返回值为 int 类型
* 返回值为 0 两者一致 ==> 利用到 TreeSet(底层数据存储为二叉树的 Set 集合) 无法添加后者元素
* 返回值为 正/负数 存在大小比较关系。
*/
@Override
public int compareTo(SingleDog o) {
System.out.println("遵从 Comparable 接口实现 compareTo 方法");
/*
* age 调用方法对象对应的 age 成员变量
* o.age 是参数对象对应的 age 成员变量
* 调用方法对象和参数对象不重要!!!完全由 TreeSet(底层数据存储为二叉树的 Set 集合) 自行决定!!!
*/
return o.age - age;
}
}
package com.qfedu.b_set;
/*
* 自定义类遵从 Comparable 接口,增强为一个可比较类!!!
* 采用的遵从方式是【妻管严模式】在遵从接口的过程中,直接明确当前泛型约束
* 数据类型为 SingleDog 类型,当前类为 SingleDog 所需进行比较的类型
* 也是对应 SingleDog 类型,非其他类型。
*/
public class SingleDog implements Comparable<SingleDog> {
private int id;
private String name;
private int age;
public SingleDog() {
}
public SingleDog(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "SingleDog [id=" + id + ", name=" + name + ", age=" + age + "]";
}
/*
* 遵从 Comparable<T> 接口要求实现的方法
* 返回值为 int 类型
* 返回值为 0 两者一致 ==> 利用到 TreeSet(底层数据存储为二叉树的 Set 集合) 无法添加后者元素
* 返回值为 正/负数 存在大小比较关系。
*/
@Override
public int compareTo(SingleDog o) {
System.out.println("遵从 Comparable 接口实现 compareTo 方法");
/*
* age 调用方法对象对应的 age 成员变量
* o.age 是参数对象对应的 age 成员变量
* 调用方法对象和参数对象不重要!!!完全由 TreeSet(底层数据存储为二叉树的 Set 集合) 自行决定!!!
*/
return o.age - age;
}
}
package com.qfedu.b_set;
import java.util.Comparator;
/**
* 自定义比较器类,遵从 Comparator 接口,同时泛型直接约束确定为 SingleDog类型
* 当前自定义比较器是处理比较 SingleDog 类型的
* @author Anonymous
*
*/
public class MyComparator implements Comparator<SingleDog> {
/*
* 返回值为 int 类型
* 返回值为 0 两者一致 ==> 利用到 TreeSet(底层数据存储为二叉树的 Set 集合) 无法添加后者元素
* 返回值为 正/负数 存在大小比较关系。
*/
@Override
public int compare(SingleDog o1, SingleDog o2) {
System.out.println("自定义比较器遵从 Comparator 接口,实现 compare 方法");
return o1.getAge() - o2.getAge();
}
}
3. Map
3.1 Map 双边队列
键值对 Key = Value
例如:
{name:张三, age:16, gender:男, address=河南省郑州市二七区航海中路60号}
==>
Person类
{name:张三, name:张四} 类似于 一个类内有两个同名的成员变量???是否允许出现???
针对于 键值对模型
Key 是在整个数据中唯一的
value 是对应key 且允许 value 重复
Java 中利用 interface Map<K, V> 用于对应键值对模型数据,而且在开发中大量使用。
K key V Value
Map 结构使用两个泛型,一个 K 约束 键 V 约束 值
Map整体Java体系
interface Map<K, V>
--| class HashMap<K, V>
底层数据存储方式为 哈希表结构的 Map 双边队列,对于整个数据而言 Key 唯一,采用 Key 对应数据哈希值决定当前【键值对】在哈希表中的存储位置。
--| class TreeMap<K, V>
底层数据存储结构为 平衡二叉树结构,也是根据对应整个Map 唯一的 Key ,要求Key有比较顺序或者提供对应的比较方式。Comparator 接口 Comparable 接口
3.2 Map 双边队列涉及到的方法【抄十遍】
增
put(K k, V v);
根据实例化 Map 双边队列对象约束的键值对泛型类型,添加对应的键值对
putAll(Map<? extends K, ? extends V> map);
添加参数 Map 双边队列到当前 Map 中,要求参数Map数据存储类型和调用方法 Map 存储数据类型一致或者其子
类
删
V remove(Object key);
根据指定 Key 删除对应的键值对对象,返回值是对应的 Value 数据
改
put(K k, V v);
如果当前 Map 双边队列中有对应 Key ,使用当前参数 value 替换原 Map 存储 value
查
int size();
Map双边队列中有效键值对个数
boolean isEmpty();
判断当前 Map 双边队列是否为空
boolean containsKey(Object key);
判断当前 Map 双边队列中,是否有指定 Key 存在
boolean containsValue(Object value);
判断当前 Map 双边队列中,是否有指定 Value 存在
Collection<V> values();
返回整个 Map 双边队列所有 Value 对应的 Collection<V>
Set<K> keySet();
返回整个 Map 双边队列所有 Key 对应的 Set<K> 集合
tips: 不需要抄
方法结尾为 Set 返回值类型是 Set 集合
方法结尾为对应单词的复数 例如: s es ies 返回值类型一般是 数组类型,List 集合,Collection 集合
3.3 重点方法 entrySet 方法
Map<K, V> ==> K, V ==> Entry对象
Set<Map.Entry<K, V>> entrySet();
通过 Map 双边队列对象,获取当前 Map 双边队列的所有键值对(Entry类型) Set 集合。
Entry 是 Map 内部类
对应当前 Map 双边队列的 键值对对象(Key=Value) ==> Entry
Entry 在整个 Map 双边队列中不可重复,可以通过 entrySet方法 获取得到整个 Map 双边队列的所有键值对对象 Entry 对应的 Set 集合
class Entry<K, V> {
K k;
V v;
public K getKey() {
return k;
}
public V getValue() {
return v;
}
}
例如:
Map<String, Integer> map ==> {"宫保鸡丁":15, "老干妈":10};
Set<Entry<String, Integer>> set = map.entrySet();
set<Entry> ===> {
Entry<String, Integer> => {K:"宫保鸡丁", V:15},
Entry<String, Integer> => {K:"老干妈", V:10}
}
package com.qfedu.c_map;
import java.util.HashMap;
import java.util.Map.Entry;
import java.util.Set;
/*
* EntrySet 方法
*/
public class Demo2 {
public static void main(String[] args) {
HashMap<String, Integer> map1 = new HashMap<String, Integer>();
map1.put("宫保鸡丁", 15);
map1.put("羊肉烩面", 12);
map1.put("班记油泼面", 15);
map1.put("羊肉泡馍", 20);
map1.put("黄焖鸡米饭", 16);
map1.put("驴肉火烧", 8);
Set<Entry<String, Integer>> entrySet = map1.entrySet();
for (Entry<String, Integer> entry : entrySet) {
System.out.print(entry.getKey() + ":");
System.out.println(entry.getValue());
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号