Linux配置JDK和Hadoop(CentOS7)
1.安装jdk,因为hadoop是使用java写的。所以需要配jdk。
查看当前的jdk。 rpm –qa|grep jdk。会显示当前的jdk,把它删了。
删除命令是yum –y remove jdk 文件名。可以直接把刚才查出来的文件名复制过来。应该是有2个。
如果不行,使用这个。rpm -e --nodeps 文件名
使用filezilla上传工具上传jdk文件。
登陆filezilla,连接失败,可能有2个原因。1是防火墙,2是网络模式。
防火墙:防火墙没关,再次关闭。
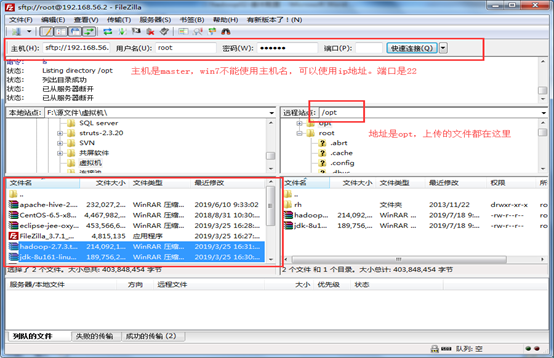
(端口号为:22)
把jdk文件传上来后。回到虚拟机部分。
进入opt文件夹。 cd /opt
查看此文件夹下的文件 ls
解压jdk tar –xzvf jdk 文件名 (把jdk和Hadoop 压缩包解压)
解压后,查看文件 ls 会发现有一个蓝名文件,就是jdk文件。红名的是压缩包。
2.配置JDK
进入这个jdk文件路径,cd jdk 输入这么多,按tab键补全。然后使用pwd命令获取当前路径,把这个路径复制一下。
export HADOOP_HOME=
export PATH=$PATH:$HADOOP_HOME/bin
配置完成后 source /etc/profile 使文件生效
在命令行,输入 Java –version 查看jdk信息。正确即ok。
3.配置Hadoop
进入hadoop解压后的文件下 cd /etc/hadoop
vi
vi
# 写在<configuration>中
<property>
<name>fs.default.name</name> #设置端口号,2.X版本的都是8020,1.X的是9000
<value>hdfs://master:8020</value> #master是主机名
</property>
<property>
<name>hadoop.tmp.dir</name> #临时文件存放路径
<value>/opt/hdfs/tmp</value>
</property>
name标签的文本不变。Value的值是hdfs://主机名:端口号。我们在hadoop的2.*的版本中使用的端口都是8020.
vi
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name> #namenode节点
<value>/opt/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name> #datanode节点
<value>/opt/hdfs/data</value>
</property>
Configuration是原有的,中间加了三个property。第一个是备份机制,一般是3份。第二个是namenode的临时路径。将来用的时候生成的一些东西在这里。第三个是datanode的临时文件路径。namnode是切块存储数据的元数据对应表(我们后续是吧数据分在不同的主机上的,那么a主机放的是什么东西,放在什么位置,b主机放的什么东西,放在哪,需要一个对应表,namenode就是放这个对应表的),datanode放的是数据。
<property>
<name>mapreduce.framework.name</name>
<value>master</value> #master是主机名
</property>
slaves-------修改localhost为主机名
master #master是主机名
如果提示commad not fonund表示 /etc/profile文件有错。正常显示一大段文本。
格式化的动作以后使用就不需要在做了。但是要是改了配置文件就需要再格式化一次(多次格式化会导致 datanode 和 namenode 的id不一致
格式完之后进入hadoop-2.7.3文件下边,进入sbin文件夹,找到start-all.sh,然后启动。命令是 ./start-all.sh ./是启动shell文件的命令

使用jsp查看,有六个进程
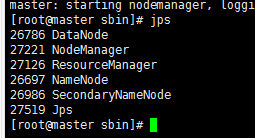
———如有缺少进程查看Hadoop文件下的logs日志文件,找到对应缺少节点的.log日志文件查找错误代码,如有缺少datanode请参考 https://www.cnblogs.com/A-Nan-q/p/14163956.html
192.168.56.2:50070 或 主机:50070
显示hadoop页面,配置完成!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号