小丸子踏入python之路:python_day04(科学计算库NumPy)
NumPy网址:http://www.numpy.org/
NumPy的概述
NumPy是用Python进行科学计算的基本包。它包含了其他东西:
- 一个强大的n维数组对象。
- 复杂的(广播)函数
- 集成C/ c++和Fortran代码的工具。
- 有用的线性代数,傅里叶变换,和随机数能力。
NumPy库的安装:
在anaconda中已经安装了这个库,不用自己安装。
如何查看anaconda中安装的库呢?
打开 anaconda prompt,输入conda list后回车即可。
如果真的需要安装,则直接输入:pip install (tensorflow)即可
- NumPy可以打开 .txt文档
import numpy #用NumPy的genfromtxt()方法打开一个.txt的文件 world_alcohol = numpy.genfromtxt("D:\softwares\python_test.txt", delimiter = ",", dtype = str) print(type(world_alcohol)) #输出打开文件的类型 print(world_alcohol) #输出内容 #print(help(numpy.genfromtxt)) #可通过help()来获得函数的详细说明
2.NumPy的array数据结构
numpy.array() 功能:创建一个数组。
import numpy vector = numpy.array([5, 10, 15, 20]) #创建一个向量 matrix = numpy.array([[5, 10, 15],[20, 25, 30],[35, 40, 45]]) #创建一个矩阵 print (vector) #输出向量 print (matrix) #输出矩阵 print(type(vector),type(matrix)) #输出其类型为 .ndarray #print(help(numpy.array))
运行结果:

3.ndarray数据类型的属性【即维度(行列数).shape】
用numpy.array()生成的不管是向量还是矩阵都是 .ndarray类型的。可以用.shape来得到其行列数
import numpy
#调用.ndarray类型数据的属性 用.shape (矩阵的行列数)
vector = numpy.array([1,22,333,4444]) #创建一个向量
print(vector.shape) #打印向量vector的属性
#将以上两步骤合并
#print(numpy.array([1,22,333,4444]).shape)
matrix = numpy.array([[2,3,4,5],[5,6,7,8],[7,8,9,10]])
print(matrix.shape)
运行结果:
(4,) #此向量有四个元素
(3,4) #此矩阵为3行4列
4. ndarray中元素的数据类型是统一的
在python中的list中可以输入任何类似的数据,但是在.ndarray中,元素的数据必须是相同的,当出现不同时,其在创建时会自动将其转换为相同类型的数据元素。
import numpy
numbers_1 = numpy.array([1,2,3,4]) #创建一个向量
print(numbers_1) #打印此向量
print(numbers_1.dtype) #打印此向量元素的类型
numbers_2 = numpy.array([1,2,3,4.0])
print(numbers_2)
print(numbers_2.dtype)
numbers_3 = numpy.array([1,2,3,'4'])
print(numbers_3)
print(numbers_3.dtype)
运行结果:
[1 2 3 4] #当向量元素全部为整数时 int32 [1. 2. 3. 4.] #当将向量的最后一个元素改成4.0后 float64 ['1' '2' '3' '4'] #当将向量的最后一个元素改成 ‘4’后 <u11
5.用numpy处理.txt文件
文件数据形式如下:

读取此文件,并指定数据的分隔符为 “,”由于第一行不是数据,可将其去掉。
import numpy
#读取wodld_alcohol.txt文件,并指定分隔符为“,”(delimiter = ',')指定读进来的数据的类型为str,并且去掉文件中的第一行(skip_header=1)
world_alcohol = numpy.genfromtxt('D:\softwares\world_alcohol.txt',delimiter = ',',dtype = str,skip_header = 1)
print(world_alcohol)
运行结果:

其运行后的结果也是用矩阵表示的,所有可以通过元素所在矩阵中的位置,读取想要抽取出来的数据。
举例说明:
uruguay = world_alcohol[1,4] #选矩阵的第二行第五列数据(因为其下标是从0开始的,所以应该是[1,4])
third_country = world_alcohol[2,2] #选矩阵的第三行第二列数据(同样下标是从0开始的,所以应该为[2,2])
print(uruguay)
print(third_country)
运行结果:

6.打印向量或矩阵中指定位置的值
#打印向量前3个值 vector = numpy.array([5,10,15,20]) print(vector[0:3]) # python中的切片问题,是从0开始的。并且[0:3]表示:包括0不包括3
运行结果:

#打印矩阵指定位置的数据
matrix = numpy.array([
[5,10,15],
[20,25,30],
[35,40,45]
])
print(matrix[:,1]) #打印矩阵的第二列。。行值全选,列值选1 ([:,1]的样子,逗号前表示行,逗号后表示列)
print(matrix[:1])
print(matrix[:,0:2]) #打印矩阵的前两列
print(matrix[1:3,0:2]) #打印矩阵的后两行与前两列的交集处
运行结果:

7. 用“==”与ndarray中每个元素进行比较
将==后边的数与向量中的每个元素进行比较,如果相等,Python解释器返回True:否则返回False。
import numpy
vector = numpy.array([5,10,15,20])
vector == 10 #将10与向量中的每个元素进行比较,相等返回true,否则返回false
运行结果:
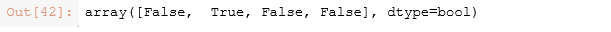
对于矩阵,用法相同。
import numpy
matrix = numpy.array([
[5,10,15],
[10,15,20],
[15,20,25]
])
print(matrix) #将15与矩阵中的每一个元素比较,相等返回true,否则返回false
matrix == 15
运行结果:

8.在7的基础上,得到了true的,将是true的值取出
8.1
vector = numpy.array([5,10,15,20])
equal_to_ten = (vector == 10) #取出比较后的结果
print(equal_to_ten) #打印
print(vector[equal_to_ten]) #打印为true对应的那个值
运行结果

8.2
vector = numpy.array([5,10,15,20])
equal_to_ten_and_five = (vector == 10) & (vector ==5) #取出比较后的结果
print(equal_to_ten_and_five)
运行结果:

8.3
vector = numpy.array([5,10,15,20])
equal_to_ten_or_five = (vector == 10) | (vector ==5) #取出比较后的结果
print(equal_to_ten_or_five)
运行结果:

9. NumPy中的类型转换
可以用 ndarray.astype() 方法来转换array中的数据类型。
#可以用 ndarray.astype() 方法来转换array中的数据类型。
vector = numpy.array(["1","2","3"])
print(vector.dtype)
print(vector)
vector = vector.astype(float)
print(vector.dtype)
print(vector)
运行结果:

10.numpy中求array中的最小/大值
#求array元素中的最小值
vector = numpy.array([5,10,15,20])
print("最小值 = ",vector.min())
print("最大值 = ",vector.max())
运行结果:

11.numpy中对矩阵进行按行/列求和
#指定维度,对矩阵进行按行/列 求和
matrix = numpy.array([
[5,10,15],
[20,15,20],
[1,20,25]
])
print(matrix.sum(axis = 1)) #axis = 1 对矩阵进行按行求
print(matrix.sum(axis = 0)) #axis = 0 对矩阵进行按列求和
运行结果:

12. np.arange() 用来创建一个数组 (通常用其来造一个索引,或从0开始的一个排列)
import numpy as np #造用numpy的别名 np,用np来代替numpy
import numpy as np #造一个numpy的别名np
print(np.arange(15)) #得到一个[0--14]的向量
a = np.arange(15).reshape(3,5) #将[0--14]的一个向量转换为3×5的矩阵形式
a
运行结果:

13.基于12的关于a的属性
print("a的shape值 = " ,a.shape) #返回a的行列数
print("a的维数 = ", a.ndim) #返回a的维数
print("a的元素类型 = ", a.dtype.name)
print("a的元素数 = ", a.size)
运行结果:

14.矩阵初始化的方法 【常用于初始化模型的矩阵】
14.1 创建一个元素全为0的(3×4)矩阵,默认元素类型为float
import numpy as np
np.zeros((3,4)) #创建一个元素全为0的(3×4)矩阵,默认元素类型为float
运行结果:

14.2 创建一个元素全为1的三维矩阵(2×3×4),并将元素类型改为int32
import numpy as np
np.ones((2,3,4),dtype = np.int32) #创建一个3维的矩阵,并且初始值定为1,且将其元素类型改为int32
运行结果:

15.用arange()创建数字序列/矩阵
15.1 用arange()创建序列向量
import numpy as np
#创建一个数字序列,np.arange(起始值,终止值,每次的增加值)
#从谁开始,到谁结束,每次+谁
np.arange(10,30,5)
运行结果:
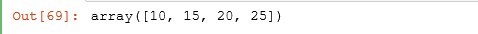
import numpy as np
#创建一个数字序列,np.arange(起始值,终止值(小于它),每次的增加值)
np.arange(0,2,0.3)
运行结果:

15.2 用arange().reshape()创建矩阵
import numpy as np
#创建一个数字序列,np.arange(起始值,终止值(小于它),每次的增加值)
#用.reshape(a,b)确定矩阵的型 (a行b列)
np.arange(0,1.8,0.3).reshape(2,3)
运行结果:

16.NumPy的随机模块(random()) [用于初始化权重矩阵Θ]
用NumPy的random.random()模块,生成的随机数在【0,1】之间
np.random.random() 意思是:调用np的random模块,再进入random模块下的random()方法
import numpy as np
np.random.random((2,3)) #生成一个元素为随机数的2×3矩阵
运行结果:

17.用np.linspace()生成矩阵
import numpy as np from numpy import pi #用np.linspace()与np.arange()生成矩阵元素的方法有所不同, #np.linspace()是在起始值和终止值之间平均的生成100个(或其他个)数 np.linspace(0, 2*pi, 100)
#np.sin(np.linspace(0, 2*pi, 100))
运行结果:

18.NumPy的“+”,“-”,“×”,“÷”等操作
18.1 向量的操作
import numpy as np
a = np.array([20,30,40,50])
b = np.arange(4) #相当于np.arange(0,4,1)
print("a = ",a)
print("b = ",b)
c = a - b
print("c = ",c)
c = c - 1
print("c - 1 = ",c)
print("b**2 = ",b**2)
print("a<35 = ",a<35)
运行结果:

18.2 矩阵的操作
A*B 表示求两个矩阵的内积(对应位置相乘)
A.dot(B) 表示矩阵的乘法 与np.dot(A,B)一样
import numpy as np
A = np.array([[1,1],
[0,1]])
B = np.array([[2,0],
[3,4]])
print("A = ", A)
print("-----------------------")
print("B = ",B)
print("-----------------------")
print("A*B = ",A*B) #A和B的内积
print("-----------------------")
print("A.dot(B) = ", A.dot(B)) #矩阵乘法
print("-----------------------")
print("dot(A,B) = ", np.dot(A,B)) #同为矩阵乘法
结果:

19.NumPy的特殊运算
np.exp():返回e的n次方,e是一个常数为2.71828
np.sqrt():开方
import numpy as np
B = np.arange(3)
print(B)
print(np.exp(B)) #返回e的B次幂
print(np.sqrt(B)) #返回B的开方
运行结果:

np.floor() :进行向下取整
a.ravel(): 把矩阵伸长为一个向量
a.shape = (a1,a2): 把a矩阵转换成 a1×a2 型的矩阵
a.T :对矩阵a进行转置
import numpy as np
#先通过随机数生成一个3×4的矩阵,因为取值在【0,1】,所以×10 ,再通过np.floor()函数,向下取值
#最终得到矩阵a
a = np.floor(10*np.random.random((3,4)))
print(a)
print("-------------------")
print(a.ravel()) #通过.raval()函数将矩阵a伸长为一个向量
print("--------------------")
a.shape = (6,2) #通过.shape函数将向量定义为6×2的形式
print(a)
print("--------------------")
print(a.T) #a的转置
运行结果:

20.用numpy进行矩阵的拼接以及切分
20.1 用numpy进行矩阵的拼接
(np.vstack((拼接矩阵A,拼接矩阵B))和np.hstack((拼接矩阵A,拼接矩阵B)))
import numpy as np
#用np.vstack((拼接矩阵A,拼接矩阵B))和np.hstack((拼接矩阵A,拼接矩阵B))操作进行矩阵的拼接
#np.vstack()和np.hstack()的参数都是一个元组(a,b)
a = np.floor(10*np.random.random((2,2)))
b = np.floor(10*np.random.random((2,2)))
print(a)
print("-------------------")
print(b)
print("-------------------")
print(np.vstack((a,b))) #按行拼接矩阵
print("-------------------")
print(np.hstack((a,b))) #按列拼接矩阵
运行结果:

20.2 用numpy进行矩阵的分割
(np.hsplit(待分割的矩阵,需要平均分割的份数a) 竖着切)
np.vsplit(待分割的矩阵,需要平均分割的份数a) 横着切
import numpy as np
#将矩阵竖着切
#用np.hsplit(待分割的矩阵,需要平均分割的份数a) 此时会得到a个array
#或直接用元组(a,b)指定要切分的位置。
#np.hsplit(待分割矩阵,(a,b)在a处和b处分别切一刀)
a = np.floor(10*np.random.random((2,12))) #创建一个2×12的矩阵
print(a)
print("-----------------")
print(np.hsplit(a,3)) #将矩阵竖着切
print("-----------------")
print(np.hsplit(a,(3,5)))
print("---------------------------------")
#将矩阵横着切
#用np.vsplit(待分割的矩阵,需要平均分割的份数a) 此时会得到a个array
#或直接用元组(a,b)指定要切分的位置。
#np.vsplit(待分割矩阵,(a,b)在a处和b处分别切一刀)
b = np.floor(10*np.random.random((12,2))) #创建一个12×2的矩阵
print(b)
print(np.vsplit(b,3)) #将矩阵横着切
print("-----------------")
print(np.vsplit(b,(4,7))) #在第四行和第七行分别切一刀
运行结果:



21.NumPy中的复制
21.1 不算复制的复制(赋值)
a 和 b指的是用一个东西
import numpy as np
#一、简单的赋值不会复制数组对象或其数据
# a 和 b指的是同一个数据,有相同的id,对他们各自操作不能分开。
#即a 和 b是对同一ndarray目标的不同两个名字
a = np.arange(12)
b = a
print("b is a :",b is a)
b.shape = (3,4) #改变b的型
print("a的shape: ",a.shape)
print("b的shape: ",b.shape)
print("a的id: ",id(a))
print("b的id: ",id(b))
运行结果:

21.2 浅复制 (a.view())
a和b的id与shape都可不同,但是数据却是相同的
import numpy as np
#用a.view()进行浅复制
a = np.arange(12)
c = a.view()
print("c is a :",c is a)
c.shape = (2,6)
print("a的shape: ",a.shape)
print("c的shape: ",c.shape)
c[0,4] = 1234
print(c) #改变c中的一个元素值
print("---------------------")
print(a) #在改变了c的后,a的也跟着改变了
print("a的id: ",id(a))
print("c的id: ",id(c))
运行结果:

21.3 深复制 (a.copy()) 完全复制
用a.copy()进行了一个完全复制,是两个不同的id,元素相同,可分别进行操作。
import numpy as np
#完全复制,并且对各自的操作不影响另一个,是两个独立的矩阵
a = np.arange(8).reshape(2,4)
d = a.copy()
print("d is a: ",d is a)
d[0,0] = 9999 #更改d的第一个值
print(a) #a的值并没有发生变化
print("---------------------------")
print(d)
print("a的id: ",id(a)) #a和d的id也不同
print("d的id: ",id(d))
运行结果:

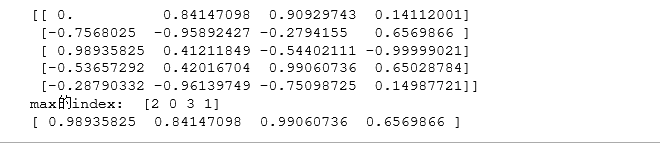
22.用.argmax()搜寻矩阵行/列中的最大值
通过.argmax()来返回矩阵中最大值所对应的index索引。
若.argmax(axis=0)返回的是矩阵中每一列最大值的索引,而.argmax(axis=1)则返回每一行最大值的索引
import numpy as np
#通过.argmax()来返回矩阵中最大值所对应的index索引。
#若.argmax(axis=0)返回的是矩阵中每一列最大值的索引,而.argmax(axis=1)则返回每一行最大值的索引
data = np.sin(np.arange(20)).reshape(5,4) #对0-19这个序列取sin值后,再设置为5×4的型
print(data)
ind = data.argmax(axis = 0) #axis=0,表示搜寻列的最大值
print("max的index: ",ind)
data_max = data[ind,range(data.shape[1])] #打印出最大索引对应的数据
print(data_max)
运行结果:
23.用np.tile()批量扩展矩阵
np.tile(向量a, (元组))——np.tile(向量a,(行变为a的n倍,列变为a的m倍))
import numpy as np
a = np.arange(0,40,10) #生成一个序列
print(a)
b = np.tile(a,(4,2)) #得到新的矩阵,使得行是a的4倍,列是a的倍
print(b)
运行结果:

24.基于np.sort()的NumPy的排序问题
用np.sort()进行排序,当axis=1,按行排序。
当axis=0,按列排序
用np.argsort()返回的是排序后对应值的索引index
import numpy as np
#用np.sort()进行排序,当axis=1,按行排序。
# 当axis=0,按列排序
a = np.array([[4,3,5],[1,2,1]])
print(a)
print("-----------------------")
b = np.sort(a,axis=1)
print(b)
a.sort(axis = 1)
print("-----------------------")
print(a)
a = np.array([4,3,1,2])
j = np.argsort(a) #得到的是从小到大数值排列的索引值[2,3,1,0]
print("-----------------------")
print(j)
print("-----------------------")
print(a[j]) #通过索引值得到排序的值
运行结果:

http://localhost:8888/notebooks/NumPy_test.ipynb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号