

记我的第一个python爬虫
捣鼓了两天,终于完成了一个小小的爬虫代码。现在才发现,曾经以为那么厉害的爬虫,在自己手里实现的时候,也不过如此。但是心里还是很高兴的。
其实一开始我是看的慕课上面的爬虫教学视屏,对着视屏的代码一行行的敲,两天的学习之后,终于看完了,代码也敲完了。视频中老师说,让我们来运行一下 看看效果,然后就看到爬取的结果一点点的出来了。我也对着自己的程序运行了一下,一堆看不懂的错误,上网查了之后一点点都改掉了。终于没有错误了。一运行,what???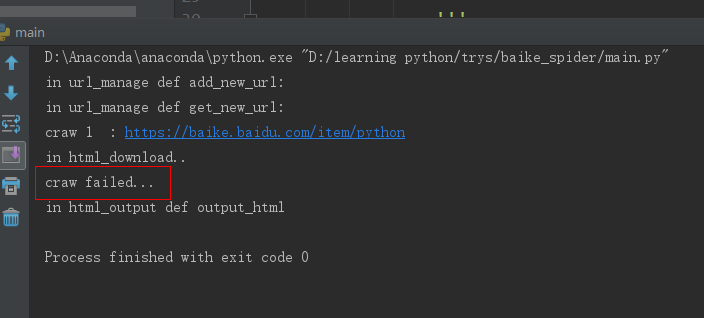
合着就爬取了一个?还是我给的根网址。这种情况最让人难受,语法错误有没有,也能运行,就是不安你说的做。不听话。
我发现他只执行到 download()函数就停止了,于是进入这个函数查看,是不是有错误,先看一下主函数,部分程序如下:
html_cont = self.downloader.download(new_url) #下载这个页面 new_urls,new_data = self.parser.parse(new_url,html_cont) #解析得到新的url和数据 self.urls.add_new_urls(new_urls) self.output.collect_data(new_data) if count == 100: #只允许爬取1000个链接网页 break; count = count+1 except: print "craw failed..." self.output.output_html() #输出爬取信息
在download()函数里面是这个:
import urllib2 class HTML_download(object): def download(self, url): print 'in html_download..' if url is None: return None response = urllib2.urlopen(url) if response.getcode(url) != 200: #说明访问失败,一般返回200说明访问成功 return None else: return response.read()
他打印完 print 函数就停止了,跳到了异常处理里面,所以我认为是这个里面的问题。但是代码又都是按照视屏中敲的,能有什么问题呢?
好吧,既然问题找不到,那咱们就咱把这部分单独拿出来实现一下,看看行不行,于是有了下面的代码:
#!Anaconda/anaconda/python #coding: utf-8 from bs4 import BeautifulSoup import re import urllib2 import urlparse URL = "https://baike.baidu.com/item/Python/407313?fr=aladdin" count = 1 #计算共有多少爬取结果 response = urllib2.urlopen(URL) #打开一个网页 soup = BeautifulSoup(response,'html.parser',from_encoding='utf-8') #创建 beautifulsoup 对象 #<a target="_blank" href="/item/%E6%BA%90%E4%BB%A3%E7%A0%81/3969" data-lemmaid="3969">源代码</a> print "get all the URL...." links = soup.find_all('a',href=re.compile(r"/item/")) for link in links: count+= 1 new_url = link['href'] new_full_url = urlparse.urljoin(URL, new_url) #与完整网页链接结合,构成完整网页,不然输出的是不完整的网页链接 print link.name,new_full_url,link.get_text() print '共 %d 个爬取结果'%(count)
虽然很短,但是能爬取相关网页。
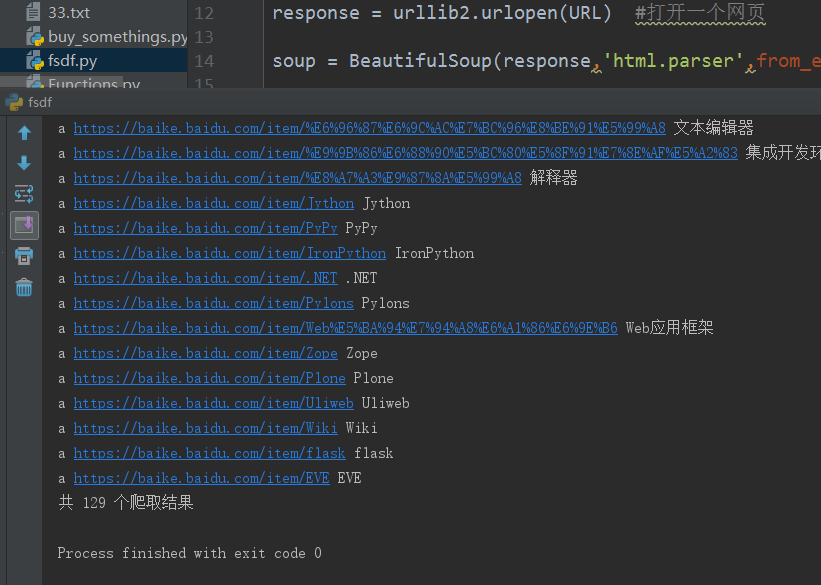
看来还是能爬取的,说明download()函数没有问题 ,那么问题就只能出现在下面几个函数里面了,还有可能就是可能是函数间的参数传递不对。导致程序异常停止。
后来发现,原来问题出在这里:
if response.getcode() != 200:
在getcode()函数里面并不需要参数,上面一个程序里面传入了参数url
自此,我的原爬虫程序就能执行了,虽然途中也遇到 了一些其他的问题,但是也都一一解决了。
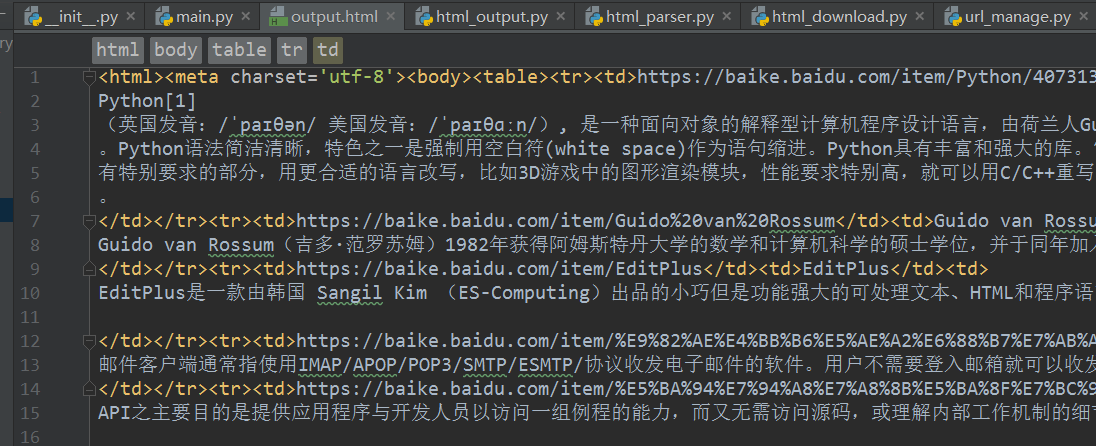
虽千万里,吾往矣。
