基于深度学习的图书管理推荐系统(附python代码)
基于深度学习的图书管理推荐系统
1、效果图

1/1 [==============================] - 0s 270ms/step
[13 11 4 19 16 18 8 6 9 0]
[0.1780757 0.17474999 0.17390694 0.17207369 0.17157653 0.16824844
0.1668652 0.16665359 0.16656876 0.16519257]
keras_recommended_book_ids深度学习推荐列表 [9137, 10548, 1, 10546, 2, 1024, 10, 10550, 7, 512]
2、算法原理
使用Keras框架实现一个简单的深度学习推荐算法。Keras是建立在Python之上的高级神经网络API。Keras提供了一种简单、快速的方式来构建和训练深度学习模型。
根据用户对书籍的评分表,使用Emmbeding深度学习训练得到一个模型,预测用户可能评分高的书籍,并把前5本推荐给用户。
Emmbeding是从离散对象(如书籍 ID)到连续值向量的映射。
这可用于查找离散对象之间的相似性。
Emmbeding向量是低维的,并在训练网络时得到更新。
设计一个模型,将用户id作为用户向量,物品id作为物品向量。
分别Emmbeding两个向量,再Concat连接起来,最后加上3个全连接层构成模型,进行训练。
使用adam优化器,用均方差mse来衡量预测评分与真实评分之间的误差
流程图:
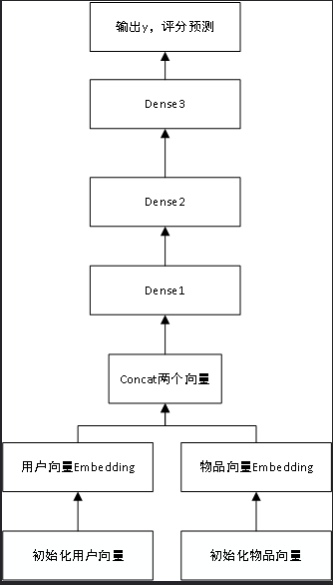
3、算法流程
1、从数据库中读取评分表信息并转成二维数组
2、数据预处理,把用户id,物品id映射成顺序字典
3、统计用户数量、物品数量
4、划分训练集与测试集
5、构建Embedding模型并进行数据训练得到模型
6、调用模型预测评分高的物品并推荐给用户
4、主体代码
# -*- coding: utf-8 -*-
"""
@contact: 微信 1257309054
@file: recommend_keras.py
@time: 2024/3/30 16:21
@author: LDC
使用Keras框架实现一个深度学习推荐算法
"""
import os
import django
from django.conf import settings
os.environ["DJANGO_SETTINGS_MODULE"] = "book_manager.settings"
django.setup()
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymysql
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
from book.models import UserSelectTypes, LikeRecommendBook, Book, RateBook
from keras.layers import Input, Embedding, Flatten, Dot, Dense, Concatenate, Dropout
from keras.models import Model
from keras.models import load_model
def get_select_tag_book(user_id, book_id=None):
# 获取用户注册时选择的书籍类别各返回10门书籍
category_ids = []
us = UserSelectTypes.objects.get(user_id=user_id)
for category in us.category.all():
category_ids.append(category.id)
unlike_book_ids = [d['book_id'] for d in
LikeRecommendBook.objects.filter(user_id=user_id, is_like=0).values('book_id')]
if book_id and book_id not in unlike_book_ids:
unlike_book_ids.append(book_id)
book_list = Book.objects.filter(tags__in=category_ids).exclude(id__in=unlike_book_ids).distinct().order_by(
"-like_num")[:10]
return book_list
def get_data():
'''
从数据库获取数据
'''
conn = pymysql.connect(host=settings.DATABASE_HOST,
user=settings.DATABASE_USER,
password=settings.DATABASE_PASS,
database=settings.DATABASE_NAME,
charset='utf8mb4',
use_unicode=True)
sql_cmd = 'SELECT book_id, user_id,mark FROM rate_book'
dataset = pd.read_sql(sql=sql_cmd, con=conn)
conn.close() # 使用完后记得关掉
return dataset
def preprocessing(dataset):
'''
数据预处理
'''
book_val_counts = dataset.book_id.value_counts()
book_map_dict = {}
for i in range(len(book_val_counts)):
book_map_dict[book_val_counts.index[i]] = i
# print(map_dict)
dataset["book_id"] = dataset["book_id"].map(book_map_dict)
user_id_val_counts = dataset.user_id.value_counts()
# 映射字典
user_id_map_dict = {}
for i in range(len(user_id_val_counts)):
user_id_map_dict[user_id_val_counts.index[i]] = i
# 将User_ID映射到一串字典
dataset["user_id"] = dataset["user_id"].map(user_id_map_dict)
return dataset, book_map_dict, user_id_map_dict
def train_model():
'''
训练模型
'''
dataset = get_data() # 获取数据
dataset, book_map_dict, user_id_map_dict = preprocessing(dataset) # 数据预处理
n_users = len(dataset.user_id.unique()) # 统计用户数量
print('n_users', n_users)
n_books = len(dataset.book_id.unique()) # 统计书籍数量
print('n_books', n_books)
# 划分训练集与测试集
train, test = train_test_split(dataset, test_size=0.2, random_state=42)
# 开始训练
# creating book embedding path
book_input = Input(shape=[1], name="Book-Input")
book_embedding = Embedding(n_books + 1, 5, name="Book-Embedding")(book_input)
Dropout(0.2)
book_vec = Flatten(name="Flatten-Books")(book_embedding)
# creating user embedding path
user_input = Input(shape=[1], name="User-Input")
user_embedding = Embedding(n_users + 1, 5, name="User-Embedding")(user_input)
Dropout(0.2)
user_vec = Flatten(name="Flatten-Users")(user_embedding)
# concatenate features
conc = Concatenate()([book_vec, user_vec])
# add fully-connected-layers
fc1 = Dense(128, activation='relu')(conc)
Dropout(0.2)
fc2 = Dense(32, activation='relu')(fc1)
out = Dense(1)(fc2)
# Create model and compile it
model2 = Model([user_input, book_input], out)
model2.compile('adam', 'mean_squared_error')
history = model2.fit([train.user_id, train.book_id], train.mark, epochs=10, verbose=1)
model2.save('regression_model2.h5')
loss = history.history['loss'] # 训练集损失
# 显示损失图像
plt.plot(loss, 'r')
plt.title('Training loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()
print('训练完成')
def predict(user_id, dataset):
'''
将预测评分高的图书推荐给该用户user_id
'''
model2 = load_model('regression_model2.h5')
'''
先拿到所有的图书索引ISBN,并去重成为book_data。
再添加一个和book_data长度相等的用户列表user,不过这里的user列表中的元素全是1,
因为我们要做的是:预测第1个用户对所有图书的评分,再将预测评分高的图书推荐给该用户。
'''
book_data = np.array(list(set(dataset.book_id)))
user = np.array([user_id for i in range(len(book_data))])
predictions = model2.predict([user, book_data])
# 更换列->行
predictions = np.array([a[0] for a in predictions])
# 根据原array,取其中数值从大到小的索引,再只取前top10
recommended_book_ids = (-predictions).argsort()[:10]
print(recommended_book_ids)
print(predictions[recommended_book_ids])
return recommended_book_ids
def embedding_main(user_id, book_id=None, is_rec_list=False):
'''
1、获取数据、数据预处理
2、划分训练集与测试集
3、训练模型、模型评估
4、预测
user_id: 用户id
book_id: 用户已经评分过的书籍id,需要在推荐列表中去除
is_rec_list: 值为True:返回推荐[用户-评分]列表,值为False:返回推荐的书籍列表
'''
dataset = get_data() # 获取数据
# print(dataset.head())
if user_id not in dataset.user_id.unique():
# 用户未进行评分则推荐注册时选择的图书类型
print('用户未进行评分则推荐注册时选择的图书类型')
if is_rec_list:
return []
# 推荐列表为空,按用户注册时选择的书籍类别各返回10门
return get_select_tag_book(user_id, book_id)
dataset, book_map_dict, user_id_map_dict = preprocessing(dataset)
# user_id需要转换为映射后的user_id传到predict函数中
predict_book_ids = predict(user_id_map_dict[user_id], dataset) # 预测的书籍Id
recommend_list = [] # 最后推荐的书籍id
# 把映射的值转为真正的书籍id
for book_id in predict_book_ids:
for k, v in book_map_dict.items():
if book_id == v:
recommend_list.append(k)
print('keras_recommended_book_ids深度学习推荐列表', recommend_list)
if not recommend_list:
# 推荐列表为空,且is_rec_list: 值为True:返回推荐[用户-评分]列表
if is_rec_list:
return []
# 推荐列表为空,按用户注册时选择的书籍类别
return get_select_tag_book(user_id, book_id)
if is_rec_list:
# 推荐列表不为空,且且is_rec_list: 值为True:返回推荐[用户-评分]列表
return recommend_list
# 过滤掉用户反馈过不喜欢的书籍
unlike_book_ids = [d['book_id'] for d in
LikeRecommendBook.objects.filter(user_id=user_id, is_like=0).values('book_id')]
# 过滤掉用户已评分的数据
already_mark_ids = [d['book_id'] for d in RateBook.objects.filter(user_id=user_id).values('book_id')]
unrecommend = list(set(unlike_book_ids + already_mark_ids))
if book_id and book_id not in unrecommend:
unrecommend.append(book_id)
book_list = Book.objects.filter(id__in=recommend_list).exclude(id__in=unrecommend).distinct().order_by("-like_num")
return book_list
if __name__ == '__main__':
train_model() # 训练模型
embedding_main(2) # 调用模型
输出:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号