pandas模块常用函数解析之Series(详解)
pandas模块常用函数解析之Series
关注公众号“轻松学编程”了解更多。
以下命令都是在浏览器中输入。
cmd命令窗口输入:jupyter notebook
打开浏览器输入网址http://localhost:8888/
一、导入模块
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
二、Series
Series是一种类似于一维数组的对象,由下面两个部分组成:
- values:一组数据(ndarray类型)
- index:相关的数据索引标签
1、Series的创建
两种创建方式
1.1 由列表或numpy数组创建
默认索引为0到N-1的整数型索引
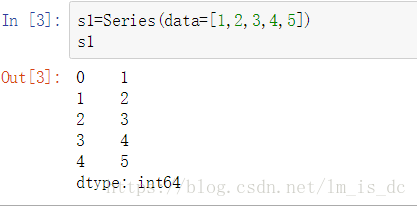
#使用列表创建Series
s1=Series(data=[1,2,3,4,5])
s1
type(s1)
结果为:
pandas.core.series.Series
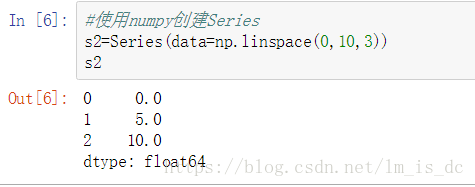
#使用numpy创建Series
s2=Series(data=np.linspace(0,10,3))
s2
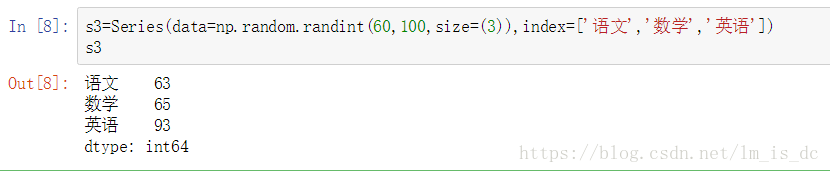
使用Index参数指定索引
s3=Series(data=np.random.randint(60,100,size=(3)),
index=['语文','数学','英语'])
s3
使用name参数
s4=Series(data=np.random.randint(60,100,size=(3)),
index=['语文','数学','英语'],name='分数')
s4

1.2 由字典创建
不能再使用index,但是依然存在默认索引(即0,1,2,3…) 。
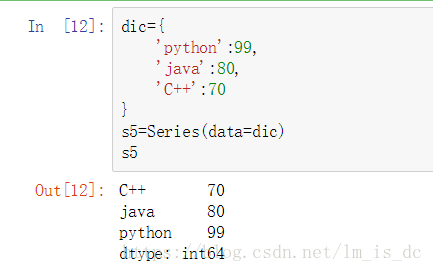
dic={
'python':99,
'java':80,
'C++':70
}
s5=Series(data=dic)
s5
注意:数据源(data)要为一维数组。
2、Series的索引和切片
可以使用中括号取单个索引(此时返回的是元素类型),
或者中括号里一个列表取多个索引(此时返回的是一个Series类型)。分为显示索引和隐式索引:
2.1显式索引
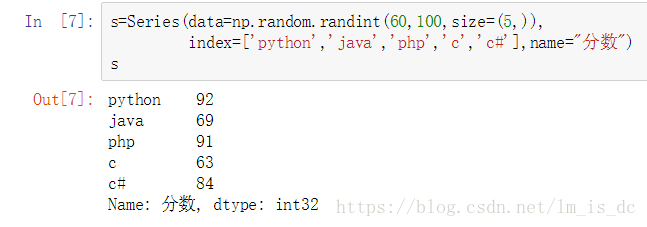
s=Series(data=np.random.randint(60,100,size=(5,)),
index=['python','java','php','c','c#'],name="分数")
s
s['python']
结果为:
92
#取多个索引
s[['php','java']]
结果为:
php 91
java 69
Name: 分数, dtype: int32
#使用.loc[]
s.loc['java']
结果为:
69
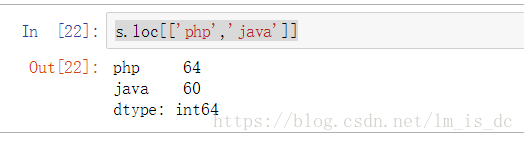
s.loc[['php','java']]
2.2 隐式索引
#s[0]对应为s['python]
s[0]
结果为:
92
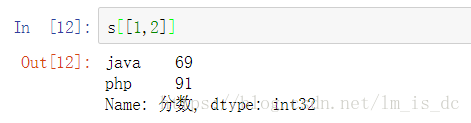
s[[1,2]]
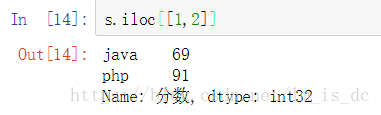
s.iloc[0]
结果为:
92
s.iloc[[1,2]]
2.3 显式索引切片
使用冒号进行切片:
- 显示索引切片:index和loc
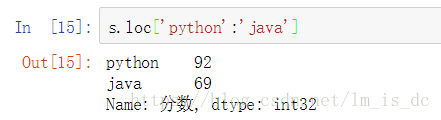
s.loc['python':'java']
2.4隐式索引切片
使用冒号进行切片:
- 隐式索引切片:整数索引值和iloc
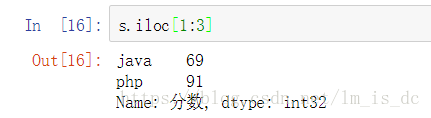
s.iloc[1:3]
3、Series的基本概念
可以把Series看成一个定长的有序字典。
向Series增加一行:相当于给字典增加一组键值对。
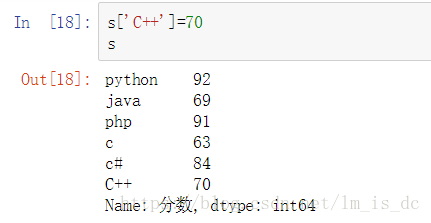
#增加
s['C++']=70
s
可以通过shape,size,index,values等得到series的属性
s.shape
结果为:
(6,)
s.size
结果为:
6
s.index
结果为:
Index(['python', 'java', 'php', 'c', 'c#', 'C++'], dtype='object')
s.values
结果为:
array([92, 69, 91, 63, 84, 70], dtype=int64)
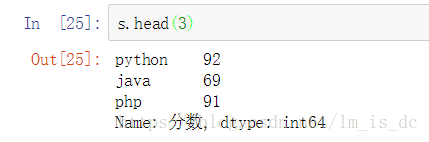
可以使用s.head(),**tail()**分别查看前n个和后n个值 ,默认n=5。
s.head(3)
s.tail(3)
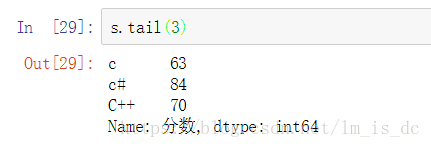
当索引没有对应的值时,可能出现缺失数据显示NaN(not a number)的情况 。
可以使用pd.isnull(),pd.notnull(),或s.isnull(),notnull()函数检测缺失数据
4、 Series的运算
4.1 + - * /
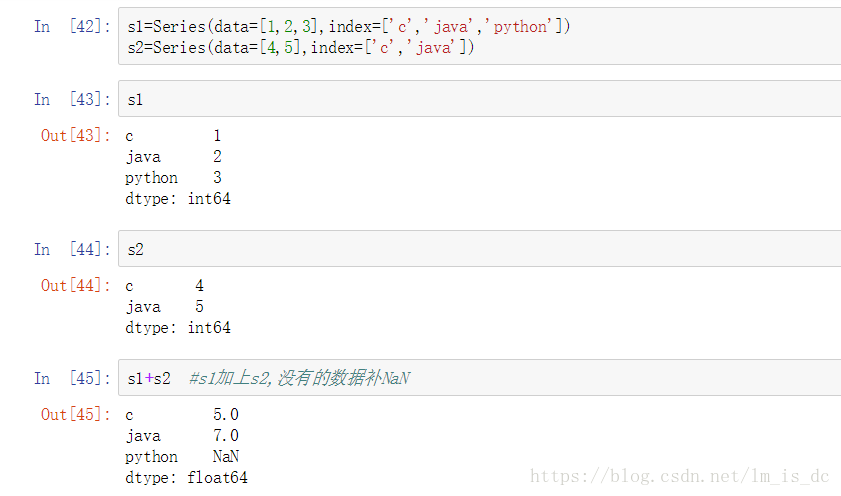
4.2 add() sub() mul() div()
s1.add(s2) #s1加上s2
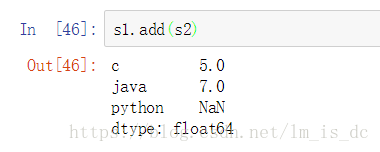
4.3 Series之间的运算
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
下面是Python 操作符与pandas操作函数的对应表:
| Python Operator | Pandas Method(s) |
|---|---|
+ | add() |
- | sub(), subtract() |
* | mul(), multiply() |
/ | truediv(), div(), divide() |
// | floordiv() |
% | mod() |
** | pow() |
5、取 Series 的最大\小值的索引值
可以使用:
获取最大值索引:argmax() 、 idxmax ()
获取最小值索引:argmin() 、 idxmin ()
s=Series(data={
"语文":120,
"数学":109,
"英语":130
})
s



6、把索引变成列
使用reset_index()函数
s=Series(data={
"语文":120,
"数学":109,
"英语":130
},name="分数")
s

s.reset_index(name='分数')

7、获取索引位置
s=Series(data=['a','b','c','d'])
np.argwhere(s[['a']])[0][0]
输出:
0
8、数组维数转换
s=Series(data=['a','b','c','d'])
#转换成一列四行的2维数组
#newaxis相当于是None的意思
s[:,np.newaxis]

效果等同:
s.reshape(-1,1)
9、使用np.hstack()合并数组
x=Series(data=[1,2,3,4])
y=Series(data=[1,2,3,4])

#先把x和y转成二维数组,然后再合并
np.hstack((x.reshape(-1,1),y.reshape(-1,1)))
类似与x轴和y轴合并成坐标点。

后记
【后记】为了让大家能够轻松学编程,我创建了一个公众号【轻松学编程】,里面有让你快速学会编程的文章,当然也有一些干货提高你的编程水平,也有一些编程项目适合做一些课程设计等课题。
也可加我微信【1257309054】,拉你进群,大家一起交流学习。
如果文章对您有帮助,请我喝杯咖啡吧!
公众号


关注我,我们一起成长~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号