python使用pandas进行数据处理
pandas数据处理
关注公众号“轻松学编程”了解更多。
以下命令都是在浏览器中输入。
cmd命令窗口输入:jupyter notebook
打开浏览器输入网址http://localhost:8888/
##导入模块
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
1、删除重复元素
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True
-
keep参数:指定保留哪一重复的行数据
-
取值范围:{‘first’, ‘last’, False}, default ‘first’
keep=False表示取全部重复的行
-
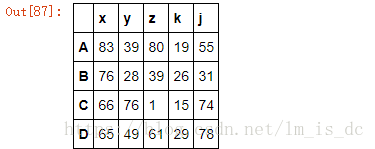
df1=DataFrame(data=np.random.randint(0,100,size=(4,5)),
index=['A','B','C','D'],
columns=['x','y','z','k','j'])
df1
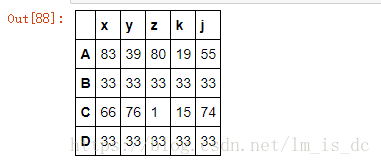
#修改'B'和'D'行数据为相同值
df1.loc['B']=33
df1.loc['D']=33
df1
1.1 使用duplicated查看重复元素行
#保留第一行重复值
df1.duplicated(keep='first')

只有’D’行为True,说明’D’行的数值与其它行是重复的。
1.2 获取重复行的DataFrame的行索引
indexs=df1.loc[df1.duplicated(keep='first')].index
indexs
结果为:
Index(['B', 'D'], dtype='object')
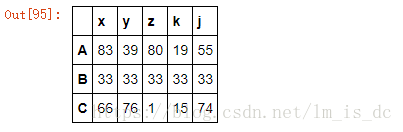
1.3 使用drop(indexs)删除重复行
#inplace=True,把结果作用于原表df1
df1.drop(indexs,axis=0,inplace=True)
df1
2、 映射
映射的含义:创建一个映射关系列表(一般用字典表示),把values元素和一个特定的标签或者字符串绑定(给一个元素值提供不同的表现形式)
包含三种操作:
- replace()函数:替换元素
- 最重要:map()函数:新建一列
- rename()函数:替换索引
2.1 replace()函数:替换元素
使用replace()函数,对values进行映射操作。
参数inplace默认值为False,映射;
inplace=True,替换 。
2.1.1 Series映射操作
- 单值映射
- 普通映射
- 字典映射(推荐)
- 多值映射
- 列表映射
- 字典映射(推荐)
- 参数
- to_replace:被映射的元素
- inplace默认为False,表示映射,inplace=True表示替换
- method:对指定的值使用相邻的值填充映射
- limit:设定填充次数
1)单值普通映射
s1=Series(data=[3,8,5,8,6])
s1

s1.replace(to_replace=8,value='eight')

只是做一个映射,s1没有被改变

2)多值列表替换
s1.replace(to_replace=[3,5],value=['three','five'])

3)多值字典替换
s1.replace(to_replace={5:'five',8:'eight'})

4) 使用参数method和limit
method=‘bfill’表示用后面的值填充
method=‘ffill’表示用前面的值填充
limit表示填充的个数
s=Series(data=[1,2,2,2,3,4])
s

#向后填充,只填充一次
s.replace(to_replace=2,method='bfill',limit=1)

只有一个2被后面的3映射,其它的没有被映射。
2.1.2 DataFrame映射操作
-
单值映射
- 普通映射: 映射所有符合要求的元素:to_replace=15,value=‘e’
- 按列指定单值映射: to_replace={列标签:映射值} value=‘value’
-
多值映射
- 列表映射: to_replace=[] value=[]
- 字典映射(推荐) to_replace={to_replace:value,to_replace:value}
注意:DataFrame中,无法使用method和limit参数
1)单值映射
普通映射
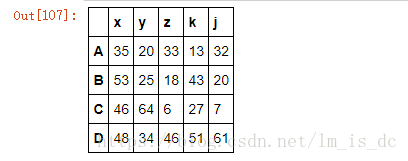
df1=DataFrame(data=np.random.randint(0,100,size=(4,5)),
index=['A','B','C','D'],columns=['x','y','z','k','j'])
df1
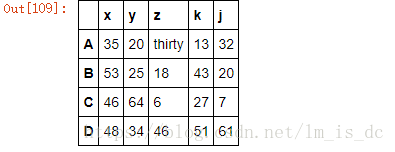
df1.replace(to_replace=33,value='thirty')
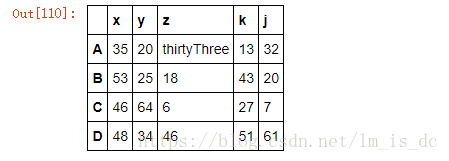
按列指定单值映射:
df1.replace(to_replace={'z':33},value='thirtyThree')
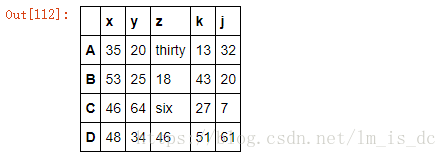
2)多值映射
df1.replace(to_replace=[33,6],value=['thirty','six'])
注意:DataFrame中,无法使用method和limit参数
2.2 map()函数:新建一列
map函数并不是df的方法,而是series的方法
-
map(字典) 字典的键要足以匹配所有的数据,否则出现NaN: —df[‘c’].map({85:‘bw’,100:‘yb’})
-
map()可以映射新一列数据
-
map()中可以使用lambd表达式
-
map()中可以使用方法,可以是自定义的方法
eg:map({to_replace:value})
-
注意 map()中不能使用sum之类的函数,for循环
2.2.1 新增一列
dic={
'name':['张三','李四'],
'salary':[4000,7000]
}
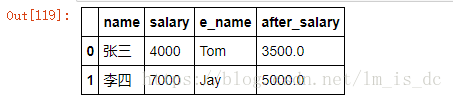
df=DataFrame(data=dic)
df

#给张三和李四映射一个英文名,并把添加一列英文名
e_name=df.name.map({'张三':'Tom','李四':'Jay'})
df['e_name']=e_name
df

2.2.2 使用lambda表达式
map()函数可以当做一种运算工具,至于执行何种运算,是由map函数的参数决定的(参数:lambda,函数)
#定义一个缴纳个人所得税函数
#当薪资大于3000时,超过的部分缴纳50%的税
def afterSalary(s):
if s> 3000:
return s-(s-3000)*0.5
return s
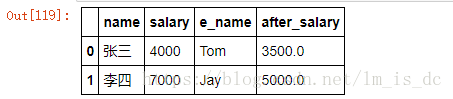
after_salary=df.salary.map(afterSalary)
df['after_salary']=after_salary
df
使用lambda匿名函数:
after_salary=df.salary.map(lambda s: s if s <=3000 else s-(s-3000)*0.5 )
df['after_salary']=after_salary
df
注意:并不是任何形式的函数都可以作为map的参数。只有当一个函数具有一个参数且有返回值,那么该函数才可以作为map的参数。
2.3 rename()函数:替换索引
使用rename()函数替换行索引
- index 替换行索引
- columns 替换列索引
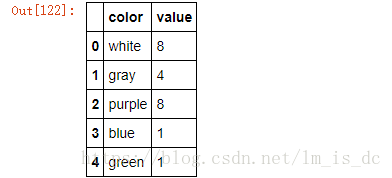
df4 = DataFrame({'color':['white','gray','purple','blue','green'],
'value':np.random.randint(10,size = 5)})
df4
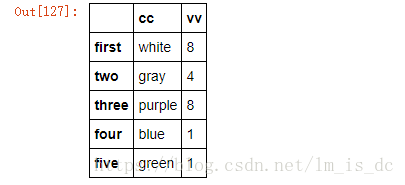
#替换行索引和列索引
new_index = {0:'first',1:'two',2:'three',3:'four',4:'five'}
new_col={'color':'cc','value':'vv'}
df4.rename(new_index,columns=new_col)
只是做了一个映射,df4的值没有改变,如果想要改变,那么使用inplace=True
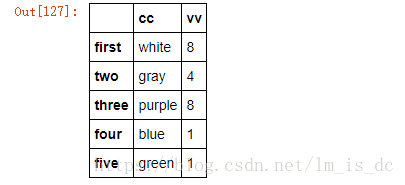
df4.rename(new_index,columns=new_col,inplace=True)
df4
3、 使用聚合操作对数据异常值检测和过滤
使用df.std()函数可以求得DataFrame对象每一列的标准差
- 创建一个1000行3列的df 范围(0-1),求其每一列的标准差
#随机产生一个DataFrame
df=DataFrame(data=np.random.random(size=(1000,3)),
columns=['A','B','C'])
df.head()
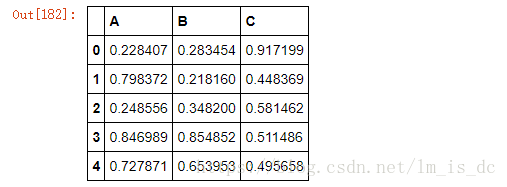
df.std(axis=0)
对每一列应用筛选条件,去除标准差太大的数据:
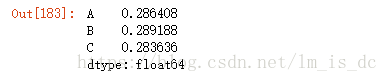
假设过滤条件为 C列数据大于两倍的C列标准差
#题目可以理解成保留C列数据小于两倍的C列标准差的数据
#获取行索引
indexs=df['C'] < df['C'].std()*2
#根据行索引得到新的DataFrame
df.loc[df['C'] < df['C'].std()*2
4、 排序
4.1、使用.take()函数排序
- take()函数接受一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序
- eg:df.take([1,3,4,2,5])
#随机生成一个二维数组
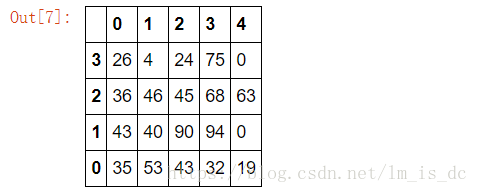
df=DataFrame(data=np.random.randint(0,100,size=(4,5)))
df
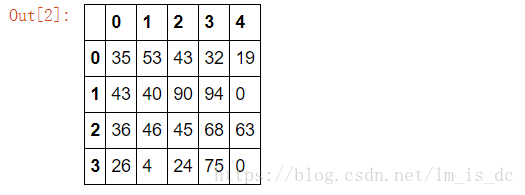
#对列索引进行重新排序
df.take([4,3,2,1,0],axis=1)
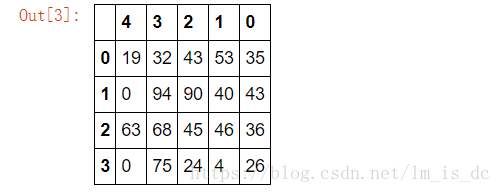
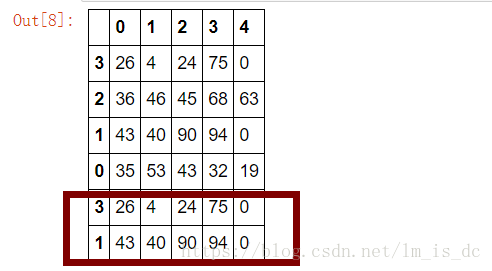
#对行索引进行重新排序
df.take([3,2,1,0],axis=0)
take(indices)中的索引参数indices元素个数可以是多个,但取值范围必须是df中已存在的索引。
#多个元素索引
df.take([3,2,1,0,3,1],axis=0)
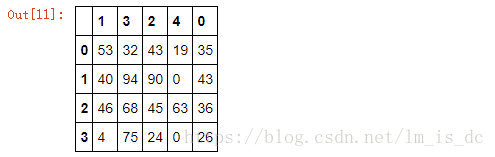
- np.random.permutation(x)可以生成x个从0-x的随机数列
#随机生成数列
np.random.permutation(5)
结果为:
array([0, 4, 2, 1, 3])
#np.random.permutation()与df.take()搭配使用,可达到随机打乱索引的目的
#在随机抽样中经常用到
df.take(np.random.permutation(5),axis=1)
4.2 随机抽样
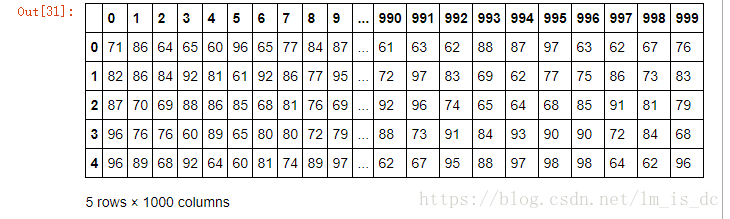
当DataFrame规模足够大时,直接使用np.random.permutation(x)函数,配合take()函数实现随机抽样 。
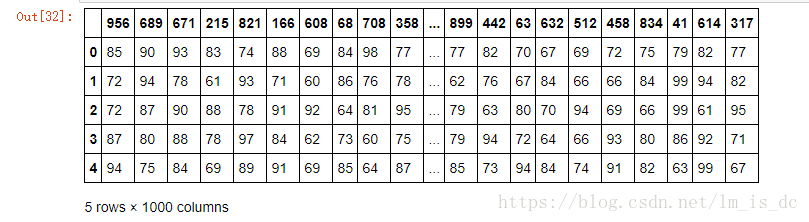
#创建一个5行1000列的二维数组
df=DataFrame(data=np.random.randint(60,100,size=(5,1000)))
df.head()
#随机抽样
df1=df.take(np.random.permutation(1000),axis=1)
df1.head()
5、 数据分类处理【重点】
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
-
groupby()函数
-
groups属性查看分组情况
5.1 分组
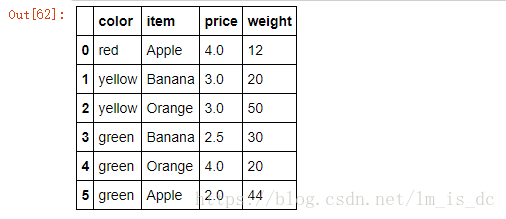
#创建二维数组
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})
df
#该函数可以进行数据的分组,但是不显示分组情况
#按'item'进行分组
df.groupby(by='item')
结果为:
<pandas.core.groupby.DataFrameGroupBy object at 0x000001BE351B0630>
5.2 查看分组
#使用goups属性查看分组情况
df.groupby(by='item').groups

按’item’分成了3组。
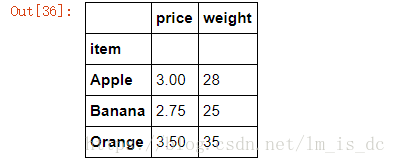
5.3 分组后的聚合操作
-
分组后的聚合操作:
分组后的成员中可以被进行运算的值会进行运算,不能被运算的值不进行运算
比如求均值,只有数值型字段才能进行运算,而字符型字段不能进行运算,也不会进行运算。
#求分组后的均值
df.groupby(by='item').mean()
groupby()中的参数by是根据哪个索引进行分组。
5.3.1 求分组后价格的均值
df.groupby(by='item')['price'].mean()
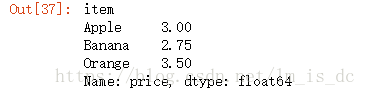
5.3.2 对分组后价格的均值进行map映射
mean_price=df.item.map(df.groupby(by='item')['price'].mean())
mean_price

5.3.3 把映射结果添加到df
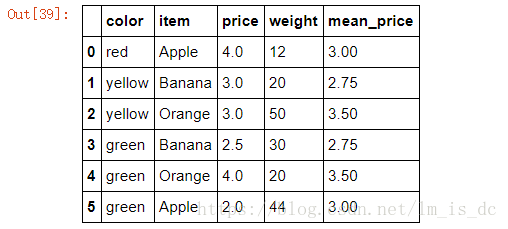
df['mean_price']=mean_price
df
5.3.4 计算出苹果的平均价格
方式一:
#先对'item'分组,然后对'price'求均值,最后取'Apple'的均值
df.groupby(by='item')['price'].mean()['Apple']
结果为:3.0
方式二:
##先对'item'分组,然后求均值,最后取'Apple'中的'price'的均值
df.groupby(by='item').mean().loc['Apple','price']
结果为:3.0
推荐使用方式一,方式二先计算全部能够进行计算的列索引的均值,耗费性能。
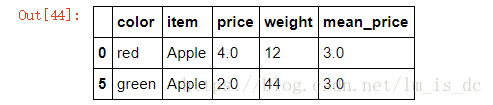
5.3.5 找出哪些行是苹果的信息 使用==进行判断
#获取'Apple'的行索引
df['item']=='Apple'

#根据行索引获取信息
df.loc[df['item']=='Apple']
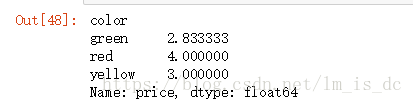
####5.3.6 按颜色查看各种颜色的水果的平均价格
color_price_mean=df.groupby(by='color')['price'].mean()
color_price_mean
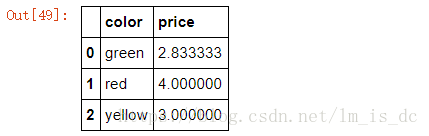
1)使用reset_index()把索引转成列
color_price_mean.reset_index()
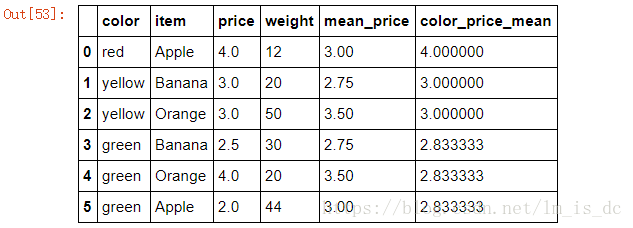
5.3.7 汇总:将各种颜色水果的平均价格和df进行汇总
1)使用map对’color’列索引进行映射,然后汇总
df['color_price_mean']=df.color.map(color_price_mean)
df
注意:当df中的某列中只有一个None时,pd可以将其转换成np.nan,但是如果存在连续多个None则pd不会进行NAN的转换。
6、 高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
- df.groupby(‘item’)[‘price’].sum() <==> df.groupby(‘item’)[‘price’].apply(sum)
- transform和apply都会进行运算,在transform或者apply中传入函数即可
- transform和apply也可以传入一个lambda表达式
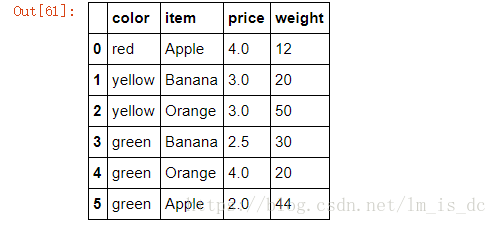
#创建二维数组
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})
df
6.1 apply函数
使用apply函数求出水果的平均价格
#按'item'列索引进行分组,取'price'这一属性进行聚合操作
#apply(sum)中的sum是内置的求和函数的函数名
#对分组后的'price'求和后除以2,得到平均值
df.groupby(by='item')['price'].apply(sum)/2

#sum()<===>apply(sum)
df.groupby(by='item')['price'].sum()/2

6.2自制定一个求平均数的函数
def my_mean(s):
sum=0
for i in s:
sum+=i
return sum/s.size
df.groupby(by='item')['price'].apply(my_mean)

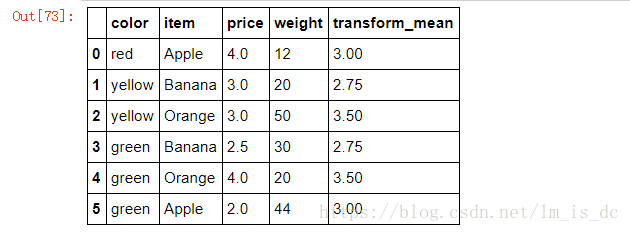
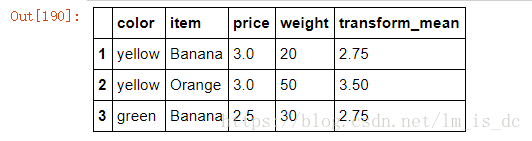
6.3 transform函数
m=df.groupby(by='item')['price'].transform(my_mean)
m

汇总:
df['transform_mean']=m
df
注意
- transform 会自动匹配列索引返回值,不去重
- apply 会根据分组情况返回值,去重
7、query()查询数据
df.query(expr):expr为查询条件
df.query('color=="red"')
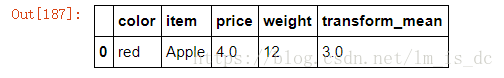
#条件与使用&
df.query('color=="yellow" & item=="Banana"')

#条件或使用|
df.query('color=="yellow" | item=="Banana"')
后记
【后记】为了让大家能够轻松学编程,我创建了一个公众号【轻松学编程】,里面有让你快速学会编程的文章,当然也有一些干货提高你的编程水平,也有一些编程项目适合做一些课程设计等课题。
也可加我微信【1257309054】,拉你进群,大家一起交流学习。
如果文章对您有帮助,请我喝杯咖啡吧!
公众号


关注我,我们一起成长~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号