
python机器学习使用PCA降维识别手写数字
PCA降维识别手写数字
关注公众号“轻松学编程”了解更多。
PCA 用于数据降维,减少运算时间,避免过拟合。
PCA(n_components=150,whiten=True)
-
n_components参数设置需要保留特征的数量,如果是小数,则表示保留特征的比例;
设为大于零的整数,会自动的选取n个主成分-
-
whiten: 默认为False,若为True表示做白化处理,白化处理主要是为了使处理后的数据方差都一致
PCA降维识别手写数字
导包
import numpy as np
import pandas as pd
import time
from pandas import Series,DataFrame
from sklearn.svm import SVC
#主成分分析
from sklearn.decomposition import PCA
# 交叉验证
from sklearn.model_selection import GridSearchCV
from IPython.display import display
import matplotlib.pyplot as plt
%matplotlib inline
读取数据
data = pd.read_csv('./data/digits.csv')
data.head()
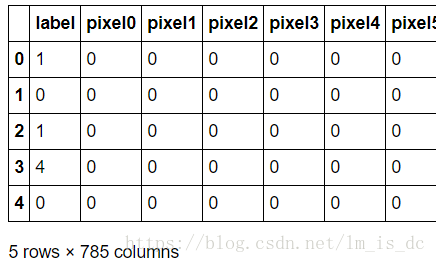
data.shape
一共有42000张图片。
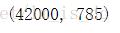
plt.figure(figsize=(2,2))
plt.imshow(data.loc[0][1:].values.reshape(28,28))
# 图片之所以显示不同数字,因为像素值pixel 不同
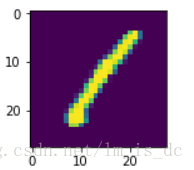
data中label一列中的值代表的是哪个数字。
#特征数据
X = data.iloc[:,1:]
#目标数据
y = data.label

有些属性都是一样的,对分类起不到作用,可以把它们从特征属性中剔除,从而达到降维的效果,缩短模型训练时间,提高准确率。
降维处理
# 784属性降维到150
X.shape
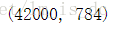
#自动选取150个主成分特征
pca = PCA(n_components=150,whiten=True)
#训练模型
pca.fit(X)
#降维处理
X_pca = pca.transform(X)
X_pca.shape
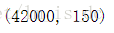
使用交叉验证获取算法模型最优参数
'''gamma : float, optional (default='auto')
Kernel coefficient for 'rbf', 'poly' and 'sigmoid'.
If gamma is 'auto' then 1/n_features will be used instead.'''
#gamma = 1/150 = 0.00667
g = [0.001,0.003,0.006,0.01,0.05]
c = [0.5,0.8,1,1.5,3]
#创建支持向量机算法模型。内核函数默认使用'rbf
svc = SVC()
#寻找算法最优参数:5个属性(5个参数)组合条件 5^5 = 3125个组合
gCV = GridSearchCV(svc,
param_grid={
'C': c,
# C是SVC中的错误惩罚系数,值越大,模型就越不能容忍错误,
#训练次数就越多,也越容易过拟合
'gamma':g # gamma是SVC中调整曲线形状的系数
})
start = time.time()
#训练模型
gCV.fit(X_pca[:5000],y[:5000])
end = time.time()
print((end-start)/60,'分钟')
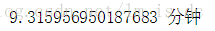
获取最优模型
#获取模型
svc_best_ = gCV.best_estimator_
svc_best_

对最优模型评分
gCV.best_score_
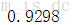
训练模型并评分
#训练模型
svc_best_.fit(X_pca[:5000],y[:5000])
#预测
y_ = svc_best_.predict(X_pca[-40:])
display(y_,y[-40:].values)

svc_best_.score(X_pca[-5000:],y[-5000:])
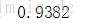
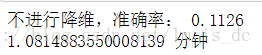
不进行降维比较
# 不进行降维:准确率降低
start = time.time()
svc_best_.fit(X[:5000],y[:5000])
end = time.time()
acu = svc_best_.score(X[-5000:],y[-5000:])
print('不进行降维,准确率: %0.4f'%(acu))
print((end-start)/60,'分钟')
后记
【后记】为了让大家能够轻松学编程,我创建了一个公众号【轻松学编程】,里面有让你快速学会编程的文章,当然也有一些干货提高你的编程水平,也有一些编程项目适合做一些课程设计等课题。
也可加我微信【1257309054】,拉你进群,大家一起交流学习。
如果文章对您有帮助,请我喝杯咖啡吧!
公众号


关注我,我们一起成长~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号