Base64加密算法以及在IDA中的识别
Base64加密算法以及在IDA中的识别
一、何为Base64算法?
Base64是一种基于64个可打印字符来表达二进制数据的表示方法。由于2的6次方等于64,所以每6个比特为一个单元。对于某个可打印字符。为什么这样说呢?我们首先了解一下Base64是如何设计的。3个字节有24个比特,在Base64中6个比特一个单元,所以对应着4个Base64单元,也就是3个单元(字节)可由4个可打印字符来表示。Base64可以用来作为电子邮件的传输编码。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样一共有62个字符。
二、Base64编码的用途
Base64可以用于处理文本数据的场合,表示、传输、存储一些二进制数据,包括电子邮件及XML等复杂数据。
三、Base64编码表
在不同的Base64编码中,Base64编码中由64个字符组成的字符不一样。因为是64个字符,第64个字符对应的十六进制是0x3F,十进制是63,二进制是111111.而着也就解释了为什么是6个比特为一个单元,在Base64中对应的某个可打印字符。
下面是Base64索引表:

四、Base64算法的实现
我们先把字符串"Man"作为需要编码的输入例子:
Man
先用在线网站编码试试,https://tool.chinaz.com/Tools/Base64.aspx.得到的字符串为
可以看到,我们发现字符串"Man"的Base64编码是"TWFu".如何实现的?别急,首先字符'M',我们查一下ASCII码,'M'对应的ASCII码为77,二进制为01001101.字符'a'对应的ASCII编码为97,二进制位01100001.字符'n'的ASCII编码为110,二进制为:01101110.
组合起来后就变成了一个24位的字符串"010011010110000101101110".接下来,我们从左往右,每次抽6位一组(6位有2^6=64种不同的组合),因此每一组的6位又代表一个数字(0 ~ 63),接下来,我们查看一下索引表,找到这个数字的字符,就是我们最后的结果
下图会更为直观.(图片是引用别人家博客的):

- 24位字符串:"010011010110000101101110"的第一组6位数是"010011",换算成十进制是就是19,我们如果查找索引表的话,发现19对应的字符是"T",所以第一组6位数对应的字符就是"T";
- 同理,第二组6位数"010110",对应的十进制数是22,查找索引表,22对应的字符是"W".
- 同理,第三组6位数是"000101",对应的十进制是5,查表之后,5对应的字符是"F".
- 同理,第四组6位数是"101110",对应的十进制是46,查表得,46对应的是字符'u'
- 我们发现,3个ASCII字符,一共24位,最后编码成了4个ASCII字符,32位。
从最初始的24位字符串到最后的32位字符串,可以发现Base64编码的结果要比原来的值更大,而且大1/3.因此,Base64编码实质上就是把一个个24比特位组成的二进制组合转换成32比特位组成的二进制组合。
当然,如果我只有2个ASCII字符需要Base64编码呢?这二个字符也才16位,并不是6的倍数!不够24位,那怎么分组呢?Base64密码的设计者当然想到了这一带你,如果少了"位",用0填充.若是少了一组,直接用"="代替.
如果,我们需要编码的字符串为"Ma",我们把他们转换为相应的二进制(图片是引用别人家博客的):

-
同理,第一组6位字符串为"010011",对应的十进制为19,在索引表里面对应的是字符'T'
-
同理,第二组6位字符串为"010110", 对应的十进制为22,在索引表里面对应的是字符'W'
-
同理,第三组6位字符串位0001?? 不够了,咋搞?这里只有4位,剩下会自动填充为0.所以最后的6位数实际上为000100,对应的十进制是4,在索引表里面对应的是字符'E'.
-
但最后面6位啥都没有,别急,对于这种情况,我们直接用"="代替空的6个比特位.

刚才说了3个字符(24位) 才能够转换4个6位的分组。如果我只有一个ASCII字符咋办?跟上面做法一样: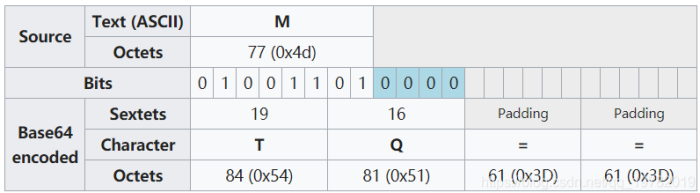
-
同理,字符"M"只有8位,甚至凑不成16位
-
第一组对应的6位字符串为"010011",对应的十进制数是19,查找索引表得知,对应字符为'T'
-
第二组,...,不够6位,只有2位,拿0补齐呗,6位为010000,对应的十进制数为16,对应字符为'M'
-
后面还缺二组6位数据怎么办?用=填充代替即可。
那其实,基于Base算法种的"="填充基址,我们其实可以通过Base64编码的字符串有几个"="来判断最后一组24位中有几个"填充字节".如果有1个“==”,则最后1组包含2个ASCII字符。如果有两个“=”,则最后一组只包含1个ASCII字符。
因此,通过这样的Base64转换,我们可以得到这样的一个结论:Base64的输出与输入比是4:3。特别的,当输入是n个字节时(1个字节等于8位),输出会是(4/3)*n个字节。
上面部分转载自:https://blog.csdn.net/qq_19782019/article/details/88117150.
五、C语言实现Base64算法
C语言代码如下:
#include <stdio.h> #包含标准输入输出函数的头文件
#include <stdlib.h> #包含动态内存分配函数的头文件,有malloc和free函数
#include <string.h> #字符串处理函数的头文件,有strlen函数
#define uint32_t unsigned int
//Base64编码的字符表
const char base64_table[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
char* base64_encode(const unsigned char* data, size_t input_length) {
size_t output_length = 4 * ((input_length + 2) / 3);//编码后的字符串长度
/*
input_length + 2是为了考虑剩余的字节,因为每个剩余的字节需要占用2个Base64字符的位置
(input_length + 2) / 3 这个指的是加上2并除以3,向下取整,得到完整3字节块的组数,因为3个字节块可以转换成4个Base64可打印字符。
*4是转化成Base64字符串的长度.
*/
char* encoded_data = (char*)malloc(output_length + 1);//用于存储编码后字符串的字符数组指针
//多出的1用于存储字符串结尾的空字符
if (encoded_data == NULL) {
perror("Memory allocation failed");
return NULL;
}
for (size_t i = 0, j = 0; i < input_length;) {
unsigned int octet_a = i < input_length ? data[i++] : 0; //第一个字节.如果i小于输入的字符串长度,则把相应的[data]赋给octet_a
uint32_t octet_b = i < input_length ? data[i++] : 0;//第二个字节
uint32_t octet_c = i < input_length ? data[i++] : 0;//第三个字节
uint32_t triple = (octet_a << 0x10) + (octet_b << 0x08) + octet_c;
encoded_data[j++] = base64_table[(triple >> 3 * 6) & 0x3F];
encoded_data[j++] = base64_table[(triple >> 2 * 6) & 0x3F];
encoded_data[j++] = base64_table[(triple >> 1 * 6) & 0x3F];
encoded_data[j++] = base64_table[(triple >> 0 * 6) & 0x3F];
}
for (size_t i = 0; i < input_length % 3; i++) {
encoded_data[output_length - 1 - i] = '=';
}
encoded_data[output_length] = '\0';
return encoded_data;
}
int main() {
const unsigned char data[] = "Hello, World!";
size_t input_length = strlen((const char*)data);
char* encoded_data = base64_encode(data, input_length);
if (encoded_data != NULL) {
printf("Base64 Encoded Data: %s\n", encoded_data);
free(encoded_data);
}
return 0;
}
uint32_t triple = (octet_a << 0x10) + (octet_b << 0x08) + octet_c;
//这句话的意思实际上是分为高8位,中8位,低8位
octet_a是一个无符号整数变量,表示输入数据的第一个字节
octet_b是一个无符号整数变量,表示输入数据的第二个字节
octet_c是一个无符号整数变量,表示输入数据的第三个字节
octet_a << 0x10 将 octet_a 左移 16 位,即将 octet_a 的值移到 triple 的高位。
octet_b << 0x08 将 octet_b 左移 8 位,即将 octet_b 的值移到 triple 的中间位。
octet_c 不进行位移,直接保留在 triple 的低位。
通过将这三个部分进行位运算的加法操作,将它们合并为一个32位的整数 triple,其中 octet_a 占据 triple 的高位,octet_b 占据中间位,octet_c 占据低位。
encoded_data[j++] = base64_table[(triple >> 3 * 6) & 0x3F];
encoded_data[j++] = base64_table[(triple >> 2 * 6) & 0x3F];
encoded_data[j++] = base64_table[(triple >> 1 * 6) & 0x3F];
encoded_data[j++] = base64_table[(triple >> 0 * 6) & 0x3F];
/*
第一句代码
encoded_data[j++] = base64_table[(triple >> 3 * 6) & 0x3F];
因为triple是一个无符号32位整型,我首先要从左到右,取它的前6位。因为每个字节占据8位。所以我要先将位移运算符>>将triple向右移动3 * 8位,即18位,使得需要处理的6位编码位于最低的6位上。
我们来举一个例子,假如现在有一个24位的字符串为
101101101010101010010101
分组后101101 101010 101010 010101
因为Base64编码,要从左到右对6位一组的编码进行处理。
所以我这里我要将101101移动到最低的6位上面去
000000 000000 000000 101101
然后&0x3F (111111)
即取它的低6位.
然后根据base64_table索引到对应的字符去.
其他几个同理~~~
*/
for (size_t i = 0; i < input_length % 3; i++) {
encoded_data[output_length - 1 - i] = '=';
}
/*
for 循环用于处理剩余的字节。i 从 0 开始递增,直到小于 input_length % 3 时停止循环。这是因为剩余的字节数量为 input_length % 3,我们需要在编码后的字符串末尾添加相应数量的等号。
在循环体内部,encoded_data[output_length - 1 - i] 表示编码后字符串中需要添加等号的位置。由于数组索引从0开始,因此通过 output_length - 1 - i 可以确定等号需要放置的索引位置。
将等号字符('=')赋值给 encoded_data[output_length - 1 - i],完成对编码后字符串的填充。
这段代码的目的是确保编码后的字符串的长度是4的倍数。Base64编码规定,如果输入数据的长度不是3的倍数,最后的编码结果需要用等号字符进行填充。每个剩余的字节对应一个等号字符,以保证编码后字符串的长度符合要求。
总结起来,这段代码的作用是在编码后字符串的末尾添加适当数量的等号字符,以满足Base64编码规则。
*/
六、IDA中进行Base64算法的识别
- VS2022
- Debug
main代码如下所示:
int __cdecl main_0(int argc, const char **argv, const char **envp)
{
void *Block; // [esp+D0h] [ebp-30h]
size_t v5; // [esp+DCh] [ebp-24h]
char Str[20]; // [esp+E8h] [ebp-18h] BYREF
__CheckForDebuggerJustMyCode(&unk_41C016);
strcpy(Str, "Hello, World!");
v5 = j_strlen(Str);
Block = (void *)sub_4113B6(Str, v5);
if ( Block )
{
printf("Base64 Encoded Data: %s\n", (char)Block);
free(Block);
}
return 0;
}
直接跟进到sub_4113B6函数即可.
int __cdecl sub_4113B6(int a1, int a2)
{
return sub_411790(a1, a2);
}
_BYTE *__cdecl sub_411790(int a1, unsigned int a2)
{
int v3; // [esp+Ch] [ebp-130h]
int v4; // [esp+Ch] [ebp-130h]
int v5; // [esp+Ch] [ebp-130h]
unsigned int i; // [esp+D4h] [ebp-68h]
unsigned int v7; // [esp+E0h] [ebp-5Ch]
int v8; // [esp+F8h] [ebp-44h]
int v9; // [esp+104h] [ebp-38h]
int v10; // [esp+110h] [ebp-2Ch]
int v11; // [esp+110h] [ebp-2Ch]
unsigned int v12; // [esp+11Ch] [ebp-20h]
_BYTE *v13; // [esp+128h] [ebp-14h]
unsigned int v14; // [esp+134h] [ebp-8h]
__CheckForDebuggerJustMyCode(&unk_41C016);
v14 = 4 * ((a2 + 2) / 3);
v13 = malloc(__CFADD__(v14, 1) ? -1 : v14 + 1);
if ( v13 )
{
v12 = 0;
v10 = 0;
while ( v12 < a2 )
{
v3 = *(unsigned __int8 *)(v12 + a1);
++v12;
v9 = v3;
if ( v12 >= a2 )
{
v4 = 0;
}
else
{
v4 = *(unsigned __int8 *)(v12 + a1);
++v12;
}
v8 = v4;
if ( v12 >= a2 )
{
v5 = 0;
}
else
{
v5 = *(unsigned __int8 *)(v12 + a1);
++v12;
}
v7 = v5 + (v9 << 16) + (v8 << 8);//对应源码中的高6位+中6位+低6位的uint32
v13[v10] = aAbcdefghijklmn[(v7 >> 18) & 0x3F]; //从这里的>>18可以看出,对应着源代码中的octet_a
v11 = v10 + 1;
v13[v11] = aAbcdefghijklmn[(v7 >> 12) & 0x3F];//对应着octet_b
v13[++v11] = aAbcdefghijklmn[(v7 >> 6) & 0x3F];//对应着octet_c
v13[++v11] = aAbcdefghijklmn[v5 & 0x3F];//最低的6位
v10 = v11 + 1;
}
for ( i = 0; i < a2 % 3; ++i )
v13[v14 - 1 - i] = 61;//来判断是否有剩余的字节,我们需要在后面添加等号
v13[v14] = 0;
return v13;
}
else
{
perror("Memory allocation failed");
return 0;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号