
2020羊城杯easyre
2020羊城杯easyre
- 无壳64位程序
- GCC编译
回显如下所示:

放IDA中继续分析:
int __cdecl main(int argc, const char **argv, const char **envp)
{
int v3; // eax
int v4; // eax
int v5; // eax
char Str[48]; // [rsp+20h] [rbp-60h] BYREF
char Str1[64]; // [rsp+50h] [rbp-30h] BYREF
char v9[64]; // [rsp+90h] [rbp+10h] BYREF
char v10[64]; // [rsp+D0h] [rbp+50h] BYREF
char Str2[60]; // [rsp+110h] [rbp+90h] BYREF
int v12; // [rsp+14Ch] [rbp+CCh] BYREF
_main();
strcpy(Str2, "EmBmP5Pmn7QcPU4gLYKv5QcMmB3PWHcP5YkPq3=cT6QckkPckoRG");
puts("Hello, please input your flag and I will tell you whether it is right or not.");
scanf("%38s", Str);
if ( strlen(Str) != 38
|| (v3 = strlen(Str), (unsigned int)encode_one(Str, v3, v10, &v12))
|| (v4 = strlen(v10), (unsigned int)encode_two(v10, v4, v9, &v12))
|| (v5 = strlen(v9), (unsigned int)encode_three(v9, v5, Str1, &v12))
|| strcmp(Str1, Str2) )
{
printf("Something wrong. Keep going.");
return 0;
}
else
{
puts("you are right!");
return 0;
}
}
程序逻辑如下所示:
- 输入字符串到Str数组里
- strlen(Str) != 38可得知flag长度必须为38
- 字符串经过了3次加密分别是,encode_one、encode_two、encode_three
- 经过3次加密后与Str2进行比较.
算法分析:
Encode_one
encode_one
__int64 __fastcall cmove_bits(unsigned __int8 a1, char a2, char a3)
{
return (unsigned __int8)((int)(unsigned __int8)(a1 << a2) >> a3);
}
void __fastcall encode_one(char *a1, int a2, char *a3, int *a4)
{
int v4; // esi
int v5; // esi
int v6; // esi
int v7; // [rsp+34h] [rbp-1Ch]
int v8; // [rsp+38h] [rbp-18h]
int v10; // [rsp+48h] [rbp-8h]
int i; // [rsp+4Ch] [rbp-4h]
unsigned __int8 *v12; // [rsp+70h] [rbp+20h]
v12 = (unsigned __int8 *)a1;
if ( a1 && a2 )
{
v10 = 0;
if ( a2 % 3 )
v10 = 3 - a2 % 3;
v8 = a2 + v10;
v7 = 8 * (a2 + v10) / 6;
for ( i = 0; i < v8; i += 3 )
{
*a3 = alphabet[(char)*v12 >> 2];
if ( a2 + v10 - 3 == i && v10 )
{
if ( v10 == 1 )
{
v4 = (char)cmove_bits(*v12, 6u, 2u);
a3[1] = alphabet[v4 + (char)cmove_bits(v12[1], 0, 4u)];
a3[2] = alphabet[(char)cmove_bits(v12[1], 4u, 2u)];
a3[3] = 61;
}
else if ( v10 == 2 )
{
a3[1] = alphabet[(char)cmove_bits(*v12, 6u, 2u)];
a3[2] = 61;
a3[3] = 61;
}
}
else
{
v5 = (char)cmove_bits(*v12, 6u, 2u);
a3[1] = alphabet[v5 + (char)cmove_bits(v12[1], 0, 4u)];
v6 = (char)cmove_bits(v12[1], 4u, 2u);
a3[2] = alphabet[v6 + (char)cmove_bits(v12[2], 0, 6u)];
a3[3] = alphabet[v12[2] & 0x3F];
}
a3 += 4;
v12 += 3;
}
if ( a4 )
*a4 = v7;
}
}
alphabet_table:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
这里的alphabet_table是一个标准的base64表,按理base64加密算法来说,base64最常见的操作是移位,这里的移位去哪了呢?在cmove_bits函数中,是存在着((a1 << a2) >> a3)这种移位.我们看一下传入的参数分别为v12[1],0,4u.
- 也就是对v12[1]向左移动0位,向右移动4位。
这很明显是一个base64算法的特征,所以我们大致可以判断encode_one实际上是对于输入的明文进行第一层的Base64加密。
Encode_two
encode_two
void __fastcall encode_two(const char *a1, int a2, char *a3, int *a4)
{
if ( a1 )
{
if ( a2 )
{
strncpy(a3, a1 + 26, 0xDui64);
strncpy(a3 + 13, a1, 0xDui64);
strncpy(a3 + 26, a1 + 39, 0xDui64);
strncpy(a3 + 39, a1 + 13, 0xDui64);
}
}
}
encode_two传入的参数分别是a3,v5,v10,&v4
- a3代表的是第一次经过Base64加密后的数据
- v10代表是经过第二次加密后的数据
所以这里的encode_two函数,实际上就是一个对原数据进行了一个分组.
我们把a3代表1,a3+13代表2,a3+26代表3,a3+39代表4,可以得知以下结论
- 1 - 3
- 2 - 1
- 3 - 4
- 4 - 2
- 左边代表原数据的位置,右边代表分组过后的数据所在位置.
Encode_three
Encode_three代码如下:
__int64 __fastcall encode_three(const char *a1, int a2, char *a3, int *a4)
{
char v5; // [rsp+Fh] [rbp-11h]
int i; // [rsp+14h] [rbp-Ch]
const char *v8; // [rsp+30h] [rbp+10h]
v8 = a1;
if ( !a1 || !a2 )
return 0xFFFFFFFFi64;
for ( i = 0; i < a2; ++i )
{
v5 = *v8;
if ( *v8 <= 64 || v5 > 90 )
{
if ( v5 <= 96 || v5 > 122 )
{
if ( v5 <= 47 || v5 > 57 )
*a3 = v5;
else
*a3 = (v5 - 48 + 3) % 10 + 48;
}
else
{
*a3 = (v5 - 97 + 3) % 26 + 97;
}
}
else
{
*a3 = (v5 - 65 + 3) % 26 + 65;
}
++a3;
++v8;
}
return 0i64;
}
可以看出这个函数是一个自定义逻辑算法。
对于在ASCII码在65-90之间的字符,进行以下运算
*a3 = (v5 - 65 + 3) % 26 + 65;
对于在ASCII码在97-122之间的字符,进行以下运算
*a3 = (v5 - 97 + 3) % 26 + 97;
对于在ASCII码在48-57之间的字符,进行以下运算
*a3 = (v5 - 48 + 3) % 10 + 48;
这里如果对于恺撒加密有涉及的人,是比较熟悉的。恺撒加密的算法,我在另外一篇博客提到过,
恺撒加密实际上,是一种替换加密的技术,是基于明文在字母表上的偏移的一种加密技术。要注意的是,字母表不一定要为26个字母,只是根据密码设计的需求而已。而恺撒加密中最常见的加密方法就是同余了,即:
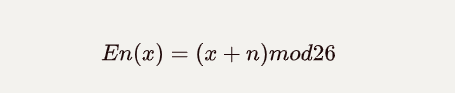
明文+偏移量要控制在26之内,因为字母表是26个。
所以这里的encode_three函数,实际上是对65-90,97-122,48-57的字符做一个偏移量为3的恺撒加密。
同时在main函数里面,最后的Str1经过三次加密后,必须要和Str2相等,所以Str2相当于最后的密文,Str1相当于我们要求的明文,即flag.
Str2:"EmBmP5Pmn7QcPU4gLYKv5QcMmB3PWHcP5YkPq3=cT6QckkPckoRG"
解密流程:
既然我们已经知道了程序的整个加密逻辑,如下所示:
- encode_one(Base64标准加密)
- encode_two(切片分组)
- encode_three(恺撒加密,key=3)
decode_one
所以我们要先写一个恺撒解密的Python脚本,脚本如下:
def decrypt_caesar(str,key=3):#根据key的不同可以改变
test = ""
for i in str:
if ord(i) >= 65 and ord(i) <= 90:
test += chr(65 + ((ord(i) - 65 -3) % 26))#这个是从A到Z
elif ord(i) >= 97 and ord(i) <= 122:
test += chr(97 + ((ord(i) - 97 -3) % 26))#这个是从a到z一共有26个字母,要控制在表里面
elif ord(i) >= 48 and ord(i) <= 57:#这里可以根据题目中的字母表进行改变
test += chr(48 + ((ord(i) - 48 - 3) % 10))
else:
test += i
return test
b = "EmBmP5Pmn7QcPU4gLYKv5QcMmB3PWHcP5YkPq3=cT6QckkPckoRG"
a = decrypt_caesar(b)
print(a)
#BjYjM2Mjk4NzMR1dIVHs2NzJjY0MTEzM2VhMn0=zQ3NzhhMzhlOD
decode_two
我们知道在encode_two里面,分组所对应的逻辑如下所示:
1(分组前的排序) - 3(分组后的排序)
2 - 1
3 - 4
4 - 2
strncpy(a3, a1 + 26, 0xDui64);
strncpy(a3 + 13, a1, 0xDui64);
strncpy(a3 + 26, a1 + 39, 0xDui64);
strncpy(a3 + 39, a1 + 13, 0xDui64);
所以对应的脚本如下所示:
a = "BjYjM2Mjk4NzMR1dIVHs2NzJjY0MTEzM2VhMn0=zQ3NzhhMzhlOD"
for i in range(0,len(a),13):
print(a[i:i+13])
"""
BjYjM2Mjk4NzM #3
R1dIVHs2NzJjY #1
0MTEzM2VhMn0= #4
zQ3NzhhMzhlOD #2
"""
我们再手动拼接一下即可."R1dIVHs2NzJjYzQ3NzhhMzhlODBjYjM2Mjk4NzM0MTEzM2VhMn0="
decode_three
直接上Base64解密脚本即可:
import base64
a = "R1dIVHs2NzJjYzQ3NzhhMzhlODBjYjM2Mjk4NzM0MTEzM2VhMn0="
b = base64.b64decode(a)
print(b)
#b'GWHT{672cc4778a38e80cb362987341133ea2}'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号