
Switch语句的反汇编以及在IDA中的识别
Switch语句的反汇编以及在IDA中的识别
Switch分为四种情况,这里只介绍三种。
- 分支较少时,不生成大表,也不生成小表,会生成if...else语句
- 分支达到一定数量时,生成大表,且大表跟顺序无关
- 大表可以理解为一个存储了多个地址的连续表,通过Register*4可以来寻址。
- 分支达到一定数量,生成大表,但是中间缺少很多case时,还会生成一张小表。
- 小表的作用可以理解为把大表的空缺地址,移动到了小表,把空缺的case值所在的地方填为default的地址
Pratice
添加case后面的值,一个一个增加,观察反汇编代码的变化(何时生成大表).
首先我们把case设为1、2、3、4,而且为连续时,我们通过vc6,观察对应的switch语句的反汇编
#include "stdafx.h"
void Function(int x)
{
switch(x)
{
case 1:
printf("1");
break;
case 2:
printf("2");
break;
case 3:
printf("3");
break;
default:
printf("Error");
break;
}
}
int main(void){
Function(1);//然后在Function(1)处下断点
return 0;
}

可以看到,上述图中,当case的数量在很少的时候,编译器会将其转换为if...else类型的汇编。
即jmp+cmp+jcc指令类型的汇编。
当我们把case的例子设为6个甚至更多呢?
代码如下所示:
#include "stdafx.h"
void Function(int x)
{
switch(x)
{
case 1:
printf("1");
break;
case 2:
printf("2");
break;
case 3:
printf("3");
break;
case 4:
printf("4");
break;
case 5:
printf("5");
break;
case 6:
printf("6");
break;
default:
printf("Error");
break;
}
}
int main(void){
Function(1);//设置断点,查看反汇编
return 0;
}
汇编代码如下所示:
Function:
0040B960 55 push ebp
0040B961 8B EC mov ebp,esp
0040B963 83 EC 44 sub esp,44h #开拓堆栈
0040B966 53 push ebx
0040B967 56 push esi
0040B968 57 push edi #保护现场
0040B969 8D 7D BC lea edi,[ebp-44h]
0040B96C B9 11 00 00 00 mov ecx,11h
0040B971 B8 CC CC CC CC mov eax,0CCCCCCCCh
0040B976 F3 AB rep stos dword ptr [edi] # 填充缓冲区
0040B978 8B 45 08 mov eax,dword ptr [ebp+8] #将我们外部传入的参数给eax
0040B97B 89 45 FC mov dword ptr [ebp-4],eax#将eax的值传给局部变量
0040B97E 8B 4D FC mov ecx,dword ptr [ebp-4]#传给ecx
0040B981 83 E9 01 sub ecx,1 # ecx-1
0040B984 89 4D FC mov dword ptr [ebp-4],ecx
0040B987 83 7D FC 05 cmp dword ptr [ebp-4],5
0040B98B 77 64 ja $L543+0Fh (0040b9f1)
0040B98D 8B 55 FC mov edx,dword ptr [ebp-4]
0040B990 FF 24 95 0F BA 40 00 jmp dword ptr [edx*4+40BA0Fh]
$L533:
0040B997 68 78 0F 42 00 push offset string "1" (00420f78)
0040B99C E8 7F 57 FF FF call printf (00401120)
0040B9A1 83 C4 04 add esp,4
0040B9A4 EB 58 jmp $L543+1Ch (0040b9fe)
$L535:
0040B9A6 68 24 0F 42 00 push offset string "2" (00420f24)
0040B9AB E8 70 57 FF FF call printf (00401120)
0040B9B0 83 C4 04 add esp,4
0040B9B3 EB 49 jmp $L543+1Ch (0040b9fe)
$L537:
0040B9B5 68 2C 01 42 00 push offset string "3" (0042012c)
0040B9BA E8 61 57 FF FF call printf (00401120)
0040B9BF 83 C4 04 add esp,4
0040B9C2 EB 3A jmp $L543+1Ch (0040b9fe)
$L539:
0040B9C4 68 1C 00 42 00 push offset string "4" (0042001c)
0040B9C9 E8 52 57 FF FF call printf (00401120)
0040B9CE 83 C4 04 add esp,4
0040B9D1 EB 2B jmp $L543+1Ch (0040b9fe)
$L541:
0040B9D3 68 74 0F 42 00 push offset string "8" (00420f74)
0040B9D8 E8 43 57 FF FF call printf (00401120)
0040B9DD 83 C4 04 add esp,4
0040B9E0 EB 1C jmp $L543+1Ch (0040b9fe)
$L543:
0040B9E2 68 88 0F 42 00 push offset string "%d %d %d %d %d" (00420f88)
0040B9E7 E8 34 57 FF FF call printf (00401120)
0040B9EC 83 C4 04 add esp,4
0040B9EF EB 0D jmp $L543+1Ch (0040b9fe)
0040B9F1 68 18 02 42 00 push offset string "Error" (00420218)
0040B9F6 E8 25 57 FF FF call printf (00401120)
0040B9FB 83 C4 04 add esp,4
0040B9FE 5F pop edi
0040B9FF 5E pop esi
0040BA00 5B pop ebx
0040BA01 83 C4 44 add esp,44h
0040BA04 3B EC cmp ebp,esp
0040BA06 E8 95 57 FF FF call __chkesp (004011a0)
0040BA0B 8B E5 mov esp,ebp
0040BA0D 5D pop ebp
0040BA0E C3 ret
可以看到在上述汇编代码中,出现了cmp dword ptr [ebp-4],5的汇编指令,随后会如果大于5的话,会跳转到(0040b9f1)地址去。而0040b9f1地址刚好是打印字符串Error的地方,也就是跳转到switch的default的地方。
这里的sub ecx,1我们后面会讲到。那我们不通过if...else的方式,是如何跳转到相应的常量对应的case语句呢?
这里我们是通过一种jmp dword ptr [edx*4+40BA0Fh]的方法进行跳转的。
jmp前置知识
- jmp + 地址,直接修改EIP的值为地址
- 这里的dword ptr相当于把内存中的[edx+4+40BA0Fh]中的4个字节,直接改变EIP!
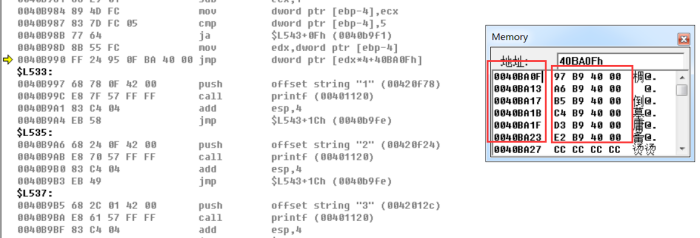
这里我们通过调试可知,这里的40BA0Fh是存储了如40B997H,40B9A6H,40B9B5H,40B9C4H,40B9D3H,40B9E2H等地址。
如果我们细心一点的话,我们可以发现后面打印1字符串语句的地址恰好是40B997H。这个是真的这么凑巧吗?
并不是,这个是编译器的一种优化,俗称大表!我们想一下,如果case的语句达到上千甚至上万,一条case语句相当于三条if...else汇编语句,非常的夸张,对于编译器而言,耗费的精力非常大!所以这里编译器通过优化,把连续的case语句的地址,写成了一张通过寻址的地址表。
这里我们知道,我们在main函数中传入的参数为1,通过sub ecx,1之后,现在的ebp-4局部变量的值为0,此时edx的值为0.
所以这里的jmp dword ptr [40BA0Fh]刚好对应的就是偏移为0的地址表,即跳转到0040BA0FH的地址处去.即打印字符串1.
所以我们可以得出一个结论
- 当我们在逆向switch语句时,当case语句数量较少时,会以if...else反汇编呈现
- 当case语句较多且连续时,会通过Register*4+地址表address的方法来寻址!!!
那如果将3中的常量值的顺序打乱,观察反汇编代码(观察顺序是否会影响生成大表).
如果我们将case语句后面的常量值顺序打乱呢?
代码如下所示:
#include "stdafx.h"
void Function(int x)
{
switch(x)
{
case 6:
printf("1");
break;
case 2:
printf("2");
break;
case 3:
printf("3");
break;
case 4:
printf("4");
break;
case 5:
printf("5");
break;
case 1:
printf("6");
break;
default:
printf("Error");
break;
}
}
int main(void){
Function(1);
return 0;
}
反汇编代码如下所示
Function:
0040B960 55 push ebp
0040B961 8B EC mov ebp,esp
0040B963 83 EC 44 sub esp,44h
0040B966 53 push ebx
0040B967 56 push esi
0040B968 57 push edi
0040B969 8D 7D BC lea edi,[ebp-44h]
0040B96C B9 11 00 00 00 mov ecx,11h
0040B971 B8 CC CC CC CC mov eax,0CCCCCCCCh
0040B976 F3 AB rep stos dword ptr [edi]
0040B978 8B 45 08 mov eax,dword ptr [ebp+8]
0040B97B 89 45 FC mov dword ptr [ebp-4],eax
0040B97E 8B 4D FC mov ecx,dword ptr [ebp-4]
0040B981 83 E9 01 sub ecx,1
0040B984 89 4D FC mov dword ptr [ebp-4],ecx
0040B987 83 7D FC 05 cmp dword ptr [ebp-4],5
0040B98B 77 64 ja $L543+0Fh (0040b9f1)
0040B98D 8B 55 FC mov edx,dword ptr [ebp-4]
0040B990 FF 24 95 0F BA 40 00 jmp dword ptr [edx*4+40BA0Fh]
$L533:
0040B997 68 78 0F 42 00 push offset string "1" (00420f78)
0040B99C E8 7F 57 FF FF call printf (00401120)
0040B9A1 83 C4 04 add esp,4
0040B9A4 EB 58 jmp $L543+1Ch (0040b9fe)
$L535:
0040B9A6 68 24 0F 42 00 push offset string "2" (00420f24)
0040B9AB E8 70 57 FF FF call printf (00401120)
0040B9B0 83 C4 04 add esp,4
0040B9B3 EB 49 jmp $L543+1Ch (0040b9fe)
$L537:
0040B9B5 68 2C 01 42 00 push offset string "3" (0042012c)
0040B9BA E8 61 57 FF FF call printf (00401120)
0040B9BF 83 C4 04 add esp,4
0040B9C2 EB 3A jmp $L543+1Ch (0040b9fe)
$L539:
0040B9C4 68 1C 00 42 00 push offset string "4" (0042001c)
0040B9C9 E8 52 57 FF FF call printf (00401120)
0040B9CE 83 C4 04 add esp,4
0040B9D1 EB 2B jmp $L543+1Ch (0040b9fe)
$L541:
0040B9D3 68 74 0F 42 00 push offset string "8" (00420f74)
0040B9D8 E8 43 57 FF FF call printf (00401120)
0040B9DD 83 C4 04 add esp,4
0040B9E0 EB 1C jmp $L543+1Ch (0040b9fe)
$L543:
0040B9E2 68 88 0F 42 00 push offset string "%d %d %d %d %d" (00420f88)
0040B9E7 E8 34 57 FF FF call printf (00401120)
0040B9EC 83 C4 04 add esp,4
0040B9EF EB 0D jmp $L543+1Ch (0040b9fe)
0040B9F1 68 18 02 42 00 push offset string "Error" (00420218)
0040B9F6 E8 25 57 FF FF call printf (00401120)
0040B9FB 83 C4 04 add esp,4
0040B9FE 5F pop edi
0040B9FF 5E pop esi
0040BA00 5B pop ebx
0040BA01 83 C4 44 add esp,44h
0040BA04 3B EC cmp ebp,esp
0040BA06 E8 95 57 FF FF call __chkesp (004011a0)
0040BA0B 8B E5 mov esp,ebp
0040BA0D 5D pop ebp
0040BA0E C3 ret
通过上图的汇编代码可以看到,顺序是并不影响大表的生成的。大表里面包含着各个case需要跳转到的地址。
同时汇编中,仍然存在着sub ecx,1的语句。

- 所以就算我们打乱了case后面常量的顺序,也是并不影响大表的生成
将case后面的值改成从100开始到109,观察汇编变化(观察值较大时是否生成大表).
那我们将case后面的常量改为较大的数,我们看编译器是否还为我们生成大表呢?
代码如下所示:
#include "stdafx.h"
void Function(int x)
{
switch(x)
{
case 100:
printf("100");
break;
case 101:
printf("101");
break;
case 102:
printf("102");
break;
case 103:
printf("103");
break;
case 104:
printf("104");
break;
case 105:
printf("105");
break;
case 106:
printf("106");
break;
case 107:
printf("107");
break;
case 108:
printf("108");
break;
case 109:
printf("109");
break;
default:
printf("Error");
break;
}
}
int main(void){
Function(101);
return 0;
}
反汇编代码如下:
Function:
0040B960 55 push ebp
0040B961 8B EC mov ebp,esp
0040B963 83 EC 44 sub esp,44h
0040B966 53 push ebx
0040B967 56 push esi
0040B968 57 push edi
0040B969 8D 7D BC lea edi,[ebp-44h]
0040B96C B9 11 00 00 00 mov ecx,11h
0040B971 B8 CC CC CC CC mov eax,0CCCCCCCCh
0040B976 F3 AB rep stos dword ptr [edi]
0040B978 8B 45 08 mov eax,dword ptr [ebp+8]
0040B97B 89 45 FC mov dword ptr [ebp-4],eax
0040B97E 8B 4D FC mov ecx,dword ptr [ebp-4]
0040B981 83 E9 64 sub ecx,64h
0040B984 89 4D FC mov dword ptr [ebp-4],ecx
0040B987 83 7D FC 09 cmp dword ptr [ebp-4],9
0040B98B 0F 87 A6 00 00 00 ja $L551+0Fh (0040ba37)
0040B991 8B 55 FC mov edx,dword ptr [ebp-4]
0040B994 FF 24 95 55 BA 40 00 jmp dword ptr [edx*4+40BA55h]
$L533:
0040B99B 68 8C 0F 42 00 push offset string "100" (00420f8c)
0040B9A0 E8 7B 57 FF FF call printf (00401120)
0040B9A5 83 C4 04 add esp,4
0040B9A8 E9 97 00 00 00 jmp $L551+1Ch (0040ba44)
$L535:
0040B9AD 68 84 0F 42 00 push offset string "101" (00420f84)
0040B9B2 E8 69 57 FF FF call printf (00401120)
0040B9B7 83 C4 04 add esp,4
0040B9BA E9 85 00 00 00 jmp $L551+1Ch (0040ba44)
$L537:
0040B9BF 68 80 0F 42 00 push offset string "102" (00420f80)
0040B9C4 E8 57 57 FF FF call printf (00401120)
0040B9C9 83 C4 04 add esp,4
0040B9CC EB 76 jmp $L551+1Ch (0040ba44)
$L539:
0040B9CE 68 7C 0F 42 00 push offset string "103" (00420f7c)
0040B9D3 E8 48 57 FF FF call printf (00401120)
0040B9D8 83 C4 04 add esp,4
0040B9DB EB 67 jmp $L551+1Ch (0040ba44)
$L541:
0040B9DD 68 78 0F 42 00 push offset string "1" (00420f78)
0040B9E2 E8 39 57 FF FF call printf (00401120)
0040B9E7 83 C4 04 add esp,4
0040B9EA EB 58 jmp $L551+1Ch (0040ba44)
$L543:
0040B9EC 68 24 0F 42 00 push offset string "105" (00420f24)
0040B9F1 E8 2A 57 FF FF call printf (00401120)
0040B9F6 83 C4 04 add esp,4
0040B9F9 EB 49 jmp $L551+1Ch (0040ba44)
$L545:
0040B9FB 68 2C 01 42 00 push offset string "106" (0042012c)
0040BA00 E8 1B 57 FF FF call printf (00401120)
0040BA05 83 C4 04 add esp,4
0040BA08 EB 3A jmp $L551+1Ch (0040ba44)
$L547:
0040BA0A 68 1C 00 42 00 push offset string "7" (0042001c)
0040BA0F E8 0C 57 FF FF call printf (00401120)
0040BA14 83 C4 04 add esp,4
0040BA17 EB 2B jmp $L551+1Ch (0040ba44)
$L549:
0040BA19 68 74 0F 42 00 push offset string "5" (00420f74)
0040BA1E E8 FD 56 FF FF call printf (00401120)
0040BA23 83 C4 04 add esp,4
0040BA26 EB 1C jmp $L551+1Ch (0040ba44)
$L551:
0040BA28 68 88 0F 42 00 push offset string "%d\n" (00420f88)
0040BA2D E8 EE 56 FF FF call printf (00401120)
0040BA32 83 C4 04 add esp,4
0040BA35 EB 0D jmp $L551+1Ch (0040ba44)
0040BA37 68 18 02 42 00 push offset string "Error" (00420218)
0040BA3C E8 DF 56 FF FF call printf (00401120)
0040BA41 83 C4 04 add esp,4
0040BA44 5F pop edi
0040BA45 5E pop esi
0040BA46 5B pop ebx
0040BA47 83 C4 44 add esp,44h
0040BA4A 3B EC cmp ebp,esp
0040BA4C E8 4F 57 FF FF call __chkesp (004011a0)
0040BA51 8B E5 mov esp,ebp
0040BA53 5D pop ebp
0040BA54 C3 ret
不难发现,就算我们把case的值改成100,只要它的数量达到一定数量,而且case后面的常量达到一定的值,编译器就会自动帮我生成大表。同时,细心一点的话可以发现,这里我们sub减去的是64h,64h转换成十进制的话是100.也就是减去100.即case的第一个数!而我们之前的代码也是减去case中的最小常量值.

得出结论:
- 满足case语句足够多+数值连续,大表永远会生成,因为大表的生成是基于地址滴~
将连续的10项中抹去1项或者2项,观察反汇编有无变化(观察大表空缺位置的处理).
当我们把case中的语句抹去4-5个的时候,大表会生成吗?大表会有别的变化吗?
C代码如下所示:
#include "stdafx.h"
void Function(int x)
{
switch(x)
{
case 100:
printf("100");
break;
case 101:
printf("101");
break;
case 106:
printf("106");
break;
case 107:
printf("107");
break;
case 108:
printf("108");
break;
case 109:
printf("109");
break;
default:
printf("Error");
break;
}
}
int main(void){
Function(101);
return 0;
}
Function反汇编代码如下所示:
Function:
0040B960 55 push ebp
0040B961 8B EC mov ebp,esp
0040B963 83 EC 44 sub esp,44h
0040B966 53 push ebx
0040B967 56 push esi
0040B968 57 push edi
0040B969 8D 7D BC lea edi,[ebp-44h]
0040B96C B9 11 00 00 00 mov ecx,11h
0040B971 B8 CC CC CC CC mov eax,0CCCCCCCCh
0040B976 F3 AB rep stos dword ptr [edi]
0040B978 8B 45 08 mov eax,dword ptr [ebp+8]
0040B97B 89 45 FC mov dword ptr [ebp-4],eax
0040B97E 8B 4D FC mov ecx,dword ptr [ebp-4]
0040B981 83 E9 64 sub ecx,64h
0040B984 89 4D FC mov dword ptr [ebp-4],ecx
0040B987 83 7D FC 09 cmp dword ptr [ebp-4],9
0040B98B 77 64 ja $L543+0Fh (0040b9f1)
0040B98D 8B 55 FC mov edx,dword ptr [ebp-4]
0040B990 FF 24 95 0F BA 40 00 jmp dword ptr [edx*4+40BA0Fh]
$L533:
0040B997 68 78 0F 42 00 push offset string "1" (00420f78)
0040B99C E8 7F 57 FF FF call printf (00401120)
0040B9A1 83 C4 04 add esp,4
0040B9A4 EB 58 jmp $L543+1Ch (0040b9fe)
$L535:
0040B9A6 68 24 0F 42 00 push offset string "2" (00420f24)
0040B9AB E8 70 57 FF FF call printf (00401120)
0040B9B0 83 C4 04 add esp,4
0040B9B3 EB 49 jmp $L543+1Ch (0040b9fe)
$L537:
0040B9B5 68 2C 01 42 00 push offset string "106" (0042012c)
0040B9BA E8 61 57 FF FF call printf (00401120)
0040B9BF 83 C4 04 add esp,4
0040B9C2 EB 3A jmp $L543+1Ch (0040b9fe)
$L539:
0040B9C4 68 1C 00 42 00 push offset string "7" (0042001c)
0040B9C9 E8 52 57 FF FF call printf (00401120)
0040B9CE 83 C4 04 add esp,4
0040B9D1 EB 2B jmp $L543+1Ch (0040b9fe)
$L541:
0040B9D3 68 74 0F 42 00 push offset string "108" (00420f74)
0040B9D8 E8 43 57 FF FF call printf (00401120)
0040B9DD 83 C4 04 add esp,4
0040B9E0 EB 1C jmp $L543+1Ch (0040b9fe)
$L543:
0040B9E2 68 88 0F 42 00 push offset string "\xd5\xe2\xca\xc7\xd2\xaa\xbc\xd3\xc3\xdc\xb5\xc4\xca\xfd\xbe\xdd" (00420f
0040B9E7 E8 34 57 FF FF call printf (00401120)
0040B9EC 83 C4 04 add esp,4
0040B9EF EB 0D jmp $L543+1Ch (0040b9fe)
0040B9F1 68 18 02 42 00 push offset string "Error" (00420218)
0040B9F6 E8 25 57 FF FF call printf (00401120)
0040B9FB 83 C4 04 add esp,4
0040B9FE 5F pop edi
0040B9FF 5E pop esi
0040BA00 5B pop ebx
0040BA01 83 C4 44 add esp,44h
0040BA04 3B EC cmp ebp,esp
0040BA06 E8 95 57 FF FF call __chkesp (004011a0)
0040BA0B 8B E5 mov esp,ebp
0040BA0D 5D pop ebp
0040BA0E C3 ret
可以观察到,我们从连续的10项中抹去了4-5项之后,编译器仍然会生成大表,我们再来看看大表里面的地址是否发生了变化?

通过调试加上对大表的观察,可以看到在大表中虽然向之前一样生成了众多case跳转地址的地址表。但是大表中,出现了众多重复的地址,即40B9F1H,出现了4次。而我们刚刚删掉了102-105,即刚好对应的大表中的连续重复4个地址。
所以在连续的case项中,如果抹去很多个case项时,大表会把空缺的地址都转变为default.我们可以这么理解,例如,原来的102假如对应的大表中的内存地址为0040BA17H,现在我抹去了这个102分支,此时102如果我们正向来看的话,此时程序会跳转到default语句,即在大表中,原先的102分支的地址也会被编译器改为default语句的地址.
得出结论:
- 在连续的多项case中,如果抹去足够多的case时,大表会把抹去的分支项原先所对应的地址全部给填充为default默认地址.
针对于多个case语句,而且不连续的常数呢?
C代码如下所示:
#include "stdafx.h"
void Function(int x)
{
switch(x)
{
case 100:
printf("100");
break;
case 101:
printf("101");
break;
case 110:
printf("110");
break;
case 3:
printf("3");
break;
case 1:
printf("1");
break;
default:
printf("Error");
break;
}
}
int main(void){
Function(101);
return 0;
}
Function反汇编代码如下:
Function:
0040B960 55 push ebp
0040B961 8B EC mov ebp,esp
0040B963 83 EC 44 sub esp,44h
0040B966 53 push ebx
0040B967 56 push esi
0040B968 57 push edi
0040B969 8D 7D BC lea edi,[ebp-44h]
0040B96C B9 11 00 00 00 mov ecx,11h
0040B971 B8 CC CC CC CC mov eax,0CCCCCCCCh
0040B976 F3 AB rep stos dword ptr [edi]
0040B978 8B 45 08 mov eax,dword ptr [ebp+8]
0040B97B 89 45 FC mov dword ptr [ebp-4],eax
0040B97E 8B 4D FC mov ecx,dword ptr [ebp-4]
0040B981 83 E9 01 sub ecx,1
0040B984 89 4D FC mov dword ptr [ebp-4],ecx
0040B987 83 7D FC 6D cmp dword ptr [ebp-4],6Dh
0040B98B 77 5B ja $L541+0Fh (0040b9e8)
0040B98D 8B 45 FC mov eax,dword ptr [ebp-4]
0040B990 33 D2 xor edx,edx #多了2个步骤.
0040B992 8A 90 1E BA 40 00 mov dl,byte ptr (0040ba1e)[eax]
0040B998 FF 24 95 06 BA 40 00 jmp dword ptr [edx*4+40BA06h]
$L533:
0040B99F 68 24 0F 42 00 push offset string "105" (00420f24)
0040B9A4 E8 77 57 FF FF call printf (00401120)
0040B9A9 83 C4 04 add esp,4
0040B9AC EB 47 jmp $L541+1Ch (0040b9f5)
$L535:
0040B9AE 68 2C 01 42 00 push offset string "101" (0042012c)
0040B9B3 E8 68 57 FF FF call printf (00401120)
0040B9B8 83 C4 04 add esp,4
$L537:
0040B9BB 68 1C 00 42 00 push offset string "110" (0042001c)
0040B9C0 E8 5B 57 FF FF call printf (00401120)
0040B9C5 83 C4 04 add esp,4
0040B9C8 EB 2B jmp $L541+1Ch (0040b9f5)
$L539:
0040B9CA 68 74 0F 42 00 push offset string "313" (00420f74)
0040B9CF E8 4C 57 FF FF call printf (00401120)
0040B9D4 83 C4 04 add esp,4
0040B9D7 EB 1C jmp $L541+1Ch (0040b9f5)
$L541:
0040B9D9 68 88 0F 42 00 push offset string "Null" (00420f88)
0040B9DE E8 3D 57 FF FF call printf (00401120)
0040B9E3 83 C4 04 add esp,4
0040B9E6 EB 0D jmp $L541+1Ch (0040b9f5)
0040B9E8 68 18 02 42 00 push offset string "Error" (00420218)
0040B9ED E8 2E 57 FF FF call printf (00401120)
0040B9F2 83 C4 04 add esp,4
0040B9F5 5F pop edi
0040B9F6 5E pop esi
0040B9F7 5B pop ebx
0040B9F8 83 C4 44 add esp,44h
0040B9FB 3B EC cmp ebp,esp
0040B9FD E8 9E 57 FF FF call __chkesp (004011a0)
0040BA02 8B E5 mov esp,ebp
0040BA04 5D pop ebp
0040BA05 C3 ret
从汇编代码中,我们可以很明显的发现比平常生成大表,多了几条汇编代码
xor edx,edx
mov dl,byte ptr (0040ba1e)[eax]
这里的mov dl,byte ptr(0040ba1e)[eax],指的是将ds为0040ba1eH,偏移地址为eax的内存单元的一个字节赋值给dl.
我们先来调试一下看看这个0040BA1EH,这个内存单元中存储了什么东西?

我们发现在内存单元0040BA1E中存储了00,05,01,05这种字节。如果把00赋值给dl的话。此时程序跳转的就是大表中的第一个地址,即40B9D9H处.如果把05赋值给dl的话,最终程序会跳转到14h+40BA06h,也就是40BA1Ah,即40B9E8H地址处。即Default语句处。也就是说,当我们的case语句足够多,case后的常量就算存在抹去的情况时,编译器会帮我们编写一张小表,这种小表的作用就是将我们大表空缺的地址,移动到小表,最后再通过偏移定位到default地址。
- 当我们的case语句足够多,连续的case语句被抹除的足够多后,编译器会以大表+小表的方式表示switch语句。
将case后面常量表达式改成毫不连续的值,观察反汇编变化.
C语言代码如下:
#include "stdafx.h"
void Function(int x)
{
switch(x)
{
case 100:
printf("100");
break;
case 1010:
printf("1010");
case 11110:
printf("11110");
break;
case 3019:
printf("3019");
break;
case 11927387:
printf("11927387");
break;
case 9:
printf("9");
break;
default:
printf("Error");
break;
}
}
int main(void){
Function(3019);
return 0;
}
Function反汇编代码如下:
Function:
0040B960 55 push ebp
0040B961 8B EC mov ebp,esp
0040B963 83 EC 44 sub esp,44h
0040B966 53 push ebx
0040B967 56 push esi
0040B968 57 push edi
0040B969 8D 7D BC lea edi,[ebp-44h]
0040B96C B9 11 00 00 00 mov ecx,11h
0040B971 B8 CC CC CC CC mov eax,0CCCCCCCCh
0040B976 F3 AB rep stos dword ptr [edi]
0040B978 8B 45 08 mov eax,dword ptr [ebp+8]
0040B97B 89 45 FC mov dword ptr [ebp-4],eax
0040B97E 81 7D FC CB 0B 00 00 cmp dword ptr [ebp-4],0BCBh
0040B985 7F 20 jg Function+47h (0040b9a7)
0040B987 81 7D FC CB 0B 00 00 cmp dword ptr [ebp-4],0BCBh
0040B98E 74 56 je Function+86h (0040b9e6)
0040B990 83 7D FC 09 cmp dword ptr [ebp-4],9
0040B994 74 6E je Function+0A4h (0040ba04)
0040B996 83 7D FC 64 cmp dword ptr [ebp-4],64h
0040B99A 74 1F je Function+5Bh (0040b9bb)
0040B99C 81 7D FC F2 03 00 00 cmp dword ptr [ebp-4],3F2h
0040B9A3 74 25 je Function+6Ah (0040b9ca)
0040B9A5 EB 6C jmp Function+0B3h (0040ba13)
0040B9A7 81 7D FC 66 2B 00 00 cmp dword ptr [ebp-4],2B66h
0040B9AE 74 27 je Function+77h (0040b9d7)
0040B9B0 81 7D FC 5B FF B5 00 cmp dword ptr [ebp-4],0B5FF5Bh
0040B9B7 74 3C je Function+95h (0040b9f5)
0040B9B9 EB 58 jmp Function+0B3h (0040ba13)
0040B9BB 68 1C 00 42 00 push offset string "207" (0042001c)
0040B9C0 E8 5B 57 FF FF call printf (00401120)
0040B9C5 83 C4 04 add esp,4
0040B9C8 EB 56 jmp Function+0C0h (0040ba20)
0040B9CA 68 94 0F 42 00 push offset string "1010" (00420f94)
0040B9CF E8 4C 57 FF FF call printf (00401120)
0040B9D4 83 C4 04 add esp,4
0040B9D7 68 8C 0F 42 00 push offset string "11110" (00420f8c)
0040B9DC E8 3F 57 FF FF call printf (00401120)
0040B9E1 83 C4 04 add esp,4
0040B9E4 EB 3A jmp Function+0C0h (0040ba20)
0040B9E6 68 80 0F 42 00 push offset string "102" (00420f80)
0040B9EB E8 30 57 FF FF call printf (00401120)
0040B9F0 83 C4 04 add esp,4
0040B9F3 EB 2B jmp Function+0C0h (0040ba20)
0040B9F5 68 74 0F 42 00 push offset string "5" (00420f74)
0040B9FA E8 21 57 FF FF call printf (00401120)
0040B9FF 83 C4 04 add esp,4
0040BA02 EB 1C jmp Function+0C0h (0040ba20)
0040BA04 68 88 0F 42 00 push offset string "Null" (00420f88)
0040BA09 E8 12 57 FF FF call printf (00401120)
0040BA0E 83 C4 04 add esp,4
0040BA11 EB 0D jmp Function+0C0h (0040ba20)
0040BA13 68 18 02 42 00 push offset string "Error" (00420218)
0040BA18 E8 03 57 FF FF call printf (00401120)
0040BA1D 83 C4 04 add esp,4
0040BA20 5F pop edi
0040BA21 5E pop esi
0040BA22 5B pop ebx
0040BA23 83 C4 44 add esp,44h
0040BA26 3B EC cmp ebp,esp
0040BA28 E8 73 57 FF FF call __chkesp (004011a0)
0040BA2D 8B E5 mov esp,ebp
0040BA2F 5D pop ebp
0040BA30 C3 ret
从上面的多个case语句以及毫不连续的值可以看出,编译器并没有生成大小表。反而是变成了类似于if...else这种汇编语句。但是jcc指令出现了je(相等就跳转),jg(大于就跳转)这种指令。
这种其实是编译器的一种二分法的一种算法优化,也就是以0BCBH为基准(十进制为3019),如果等于3019则跳转到0040b9a7H处,继续执行指令,如果大于3019则继续执行下面的jcc指令,这种针对于case后面常量数值差异很大,而且毫不连续的值,可以极大的提高查找的效率。
IDA中的Switch语句的识别.
第一个例子是针对于case数量很多,而且值是无规则的switch语句
C语言代码如下:
- 编译器:VC6++
- Debug32位版本
#include "stdafx.h"
void Function(int x)
{
switch(x)
{
case 100:
printf("100");
break;
case 1010:
printf("1010");
case 11110:
printf("11110");
break;
case 3019:
printf("3019");
break;
case 11927387:
printf("11927387");
break;
case 9:
printf("9");
break;
default:
printf("Error");
break;
}
}
int main(void){
Function(3019);
return 0;
}
用IDA32位打开如下图所示:
- IDA7.7

直接进入到401023函数继续分析.


可以看到在IDA中,对于这种毫不连续的值以及很多case语句的switch,IDA主要是以二分法式的代码进行识别。
以3019为基准,如果小于3019则跳转到针对于3019以下的数的switch语句中进行跳转。而针对于比3019大的数则是通过二分法的方法进行跳转~
第二个例子是针对于大表的switch语句逆向。
C语言代码如下,编译器版本与上面一样:
#include "stdafx.h"
void Function(int x)
{
switch(x)
{
case 1:
printf("1");
break;
case 2:
printf("2");
break;
case 3:
printf("3");
break;
case 4:
printf("4");
break;
case 5:
printf("5");
break;
case 6:
printf("6");
break;
default:
printf("Error");
break;
}
}
int main(void){
Function(1);
return 0;
}
然后用IDA32位打开该程序

可以看到在IDA的伪代码中,对于switch的常见有规律的case语句的识别还是非常清晰的。我们再来观察一下IDA中对于大表的识别。

根据上述两个图可以得知,在大表的识别中,IDA也给出了一个很好的方案,通过jpt_40B990作为基址,edx*4作为寻址的偏移地址来跳转到case语句需要跳转的地方去!
第三个例子是针对于大小表的switch语句逆向
C语言代码如下,编译环境与上面一样:
#include "stdafx.h"
void Function(int x)
{
switch(x)
{
case 100:
printf("100");
break;
case 101:
printf("101");
break;
case 110:
printf("110");
break;
case 3:
printf("3");
break;
case 1:
printf("1");
break;
default:
printf("Error");
break;
}
}
int main(void){
Function(101);
return 0;
}
IDA32位,打开如下所示:
int __cdecl sub_40B960(int a1)
{
int result; // eax
switch ( a1 )
{
case 1:
result = printf("1");
break;
case 3:
result = printf("3");
break;
case 100:
result = printf("100");
break;
case 101:
result = printf("101");
break;
case 110:
result = printf("110");
break;
default:
result = printf("Error");
break;
}
return result;
}
可以看到,跟平常我们写的switch没什么区别,IDA可以很好的还原出来,我们继续从汇编层面看一看大小表,IDA是如何处理的.
这里的大小表的话,IDA是根据byte_40BA20,也就是我们说的小表,对大表残缺的default的语句进行偏移地址,以及default的填充.
以上就是Switch语句的三种情况的反汇编以及在IDA中的识别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号