
k8s 理解Service工作原理
什么是service?
Service是将运行在一组 Pods 上的应用程序公开为网络服务的抽象方法。
简单来说K8s提供了service对象来访问pod。我们在《k8s网络模型与集群通信》中也说过k8s集群中的每一个Pod(最小调度单位)都有自己的IP地址,都有IP了访问起来还不简单?
其实不然,一是k8s中pod不是持久性的,摧毁重建将获得新的IP,客户端通过变更IP来访问显然不合理。二是需要多个副本间的负载均衡。所以此时Service就冒出来了。
那么今天我们就来学习一下service,看看它是如何工作的。
Service与endpoints、pod
当我们通过API创建/修改service对象时,endpoints控制器的informer机制 Listen到service对象,然后根据service的配置的选择器创建一个endpoints对象,此对象将pod的IP、容器端口做记录并存储到etcd,这样service只要看一下自己名下的endpoints就可以知道所对应pod信息了。
且看下图:
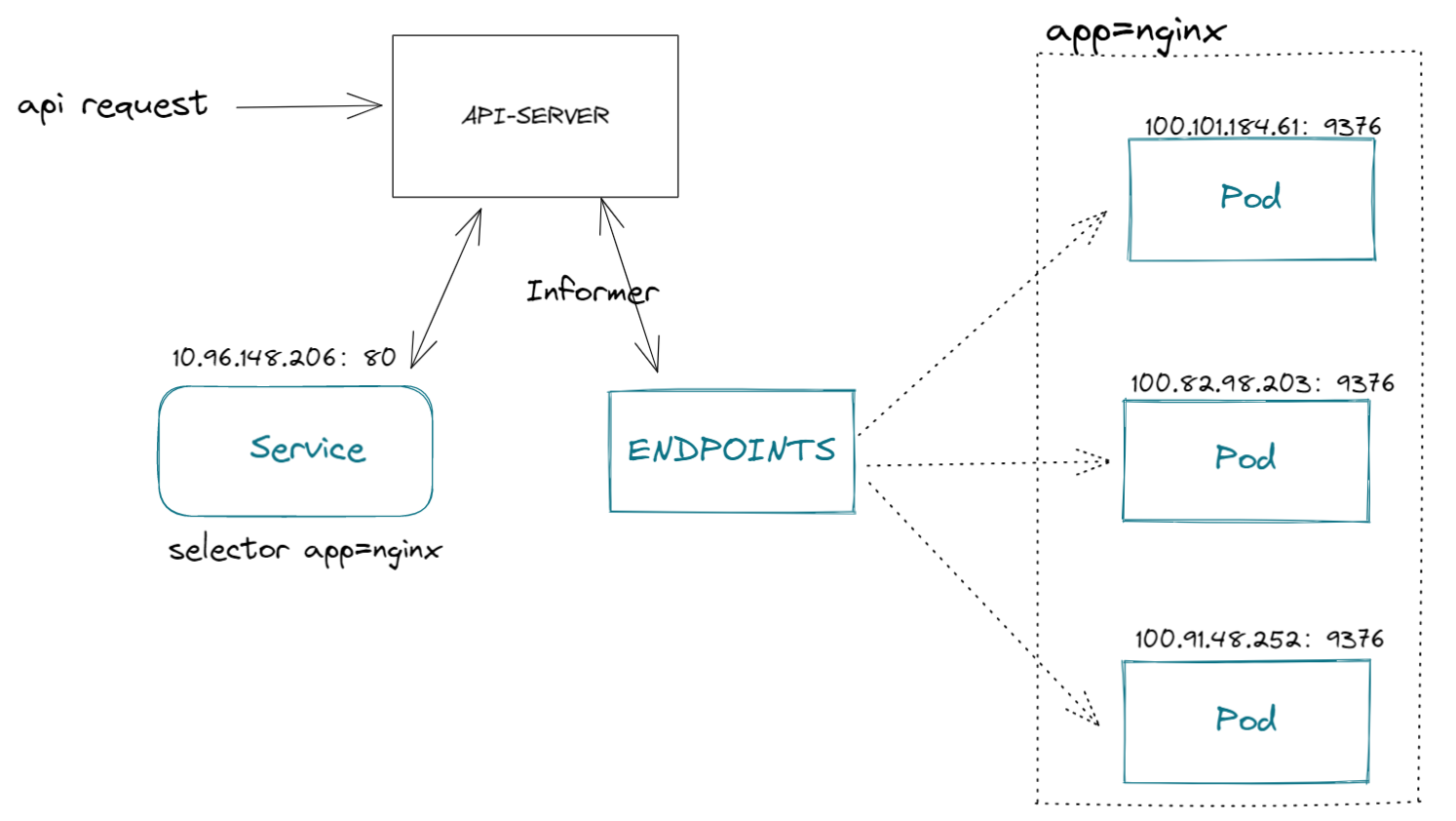
我们在实例来看一下,先稀疏平常创建一个Deployment
#deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-demo
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: mirrorgooglecontainers/serve_hostname
ports:
- containerPort: 9376
protocol: TCP
serve_hostname是k8s官方提供的debug镜像,一个返回hostname的web server。这样我们创建出了标签为app=nginx的三个pod,当我们访问pod的9376时会返回hostname。
接着是service清单,我们在service中指定了选择器为app=nginx
#service.yaml
apiVersion: v1
kind: Service
metadata:
name: service-demo
spec:
selector:
app: nginx
ports:
- name: default
protocol: TCP
#service port
port: 80
#container port
targetPort: 9376
这样我们获得不变的CLUSTER-IP 10.96.148.206的service

如果pod启动成功,则自动创建和service同名的endpoints记录下了三个pod的数据

service中选择器未指定标签时endpoints需要手动创建映射到service的网络地址如下:
apiVersion: v1
kind: Endpoints
metadata:
name: service
subsets:
- addresses:
- ip: 10.96.148.206
ports:
- port: 9376
此时当我们不断访问service的CLUSTER-IP时:
# curl 10.96.148.206:80
deployment-demo-7d94cbb55f-8mmxb
# curl 10.96.148.206:80
deployment-demo-7d94cbb55f-674ns
# curl 10.96.148.206:80
deployment-demo-7d94cbb55f-lfrm8
# curl 10.96.148.206:80
deployment-demo-7d94cbb55f-8mmxb
可以看到此时请求已被路由到后端pod,返回hostname,并且负载均衡方式是Round Robin即轮询模式。
通过上面介绍我们好像摸到了Service其中的门道,接下来是流量到底如何通过service进入pod的?
Service与kube-proxy
涉及到流量当然是kube-proxy登场了!
kube-proxy 是集群中每个节点上运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。用于处理单个主机子网划分并向外部世界公开服务。它跨集群中的各种隔离网络将请求转发到正确的 pod/容器。
kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如下图所示:
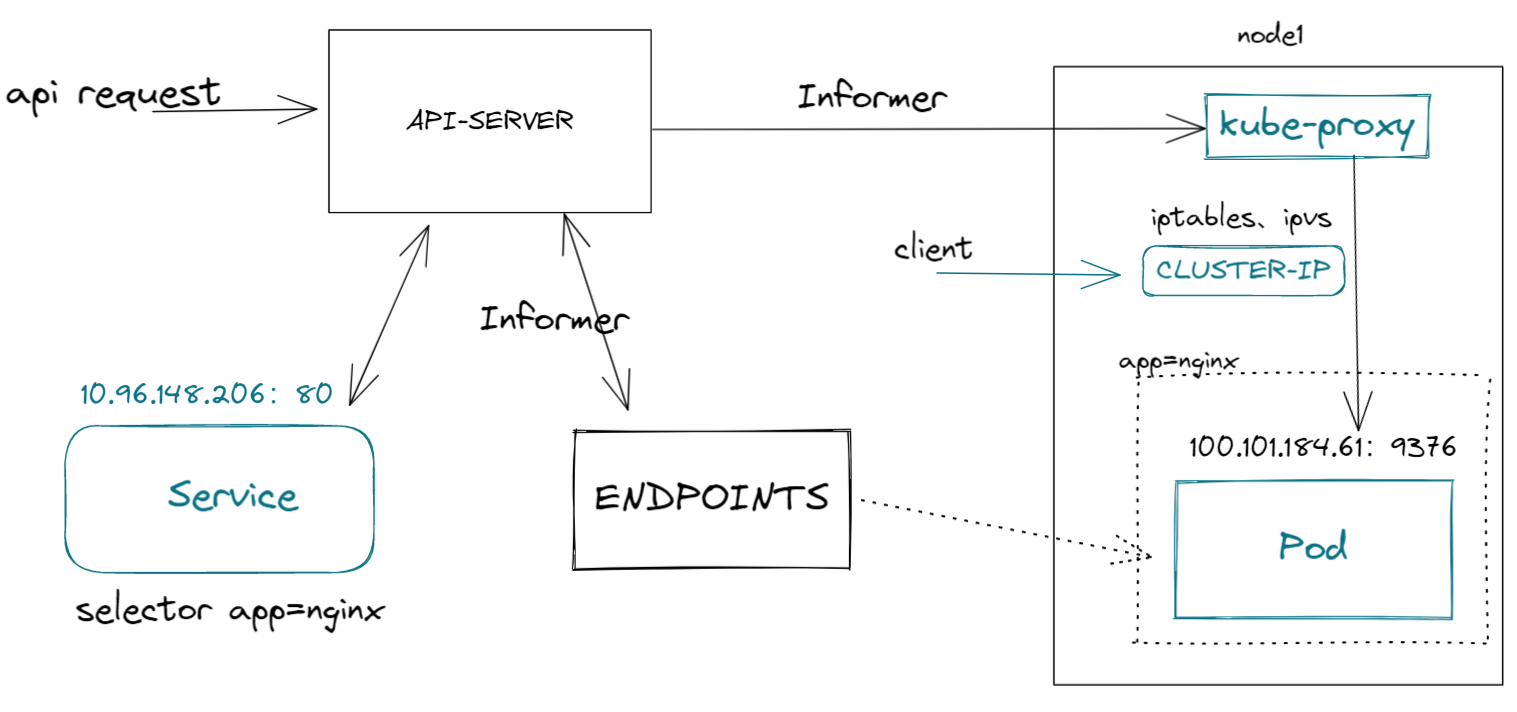
kube-proxy 通过 Informer知道了Service、endpoints对象的创建,然后把service身上的CLUSTER-IP 和端口已经端点信息拿出来,创建iptable NAT规则做转发或通过ipvs模块创建VS服务器,这样经过CLUSTER-IP的流量都被转发到后端pod。
iptables模式
我们先查看nat表的OUTPUT链,存在kube-proxy创建的KUBE-SERVICE链
iptables -nvL OUTPUT -t nat

在KUBE-SERVICES链中有一条目的地为10.96.148.206即CLUSTER-IP地址跳转到KUBE-SVC-EJUV4ZBKPDWOZNF4
iptables -nvL KUBE-SERVICES -t nat |grep service-demo

接着是查看这条链,以1/3的概率跳转到其中一条
iptables -nvL KUBE-SVC-EJUV4ZBKPDWOZNF4 -t nat

最后KUBE-SEP-BTFJGISFGMEBGVUF链终于找到了DNAT规则
iptables -nvL KUBE-SEP-BTFJGISFGMEBGVUF -t nat

即将请求通过DNAT发送到地址100.101.184.61:9376也就是我们其中一个Pod。
IPVS模式
与iptalbes模式相比,IPVS模式工作在内核态,在同步代理规则时具有更好的性能,同时提高网络吞吐量为大型集群提供了更好的可扩展性。
IPVS 模式在工作时,当我们创建了前面的 Service 之后,kube-proxy 首先会在宿主机上创建一个虚拟网卡kube-ipvs0,并为它分配 Service VIP 作为 IP 地址,如图
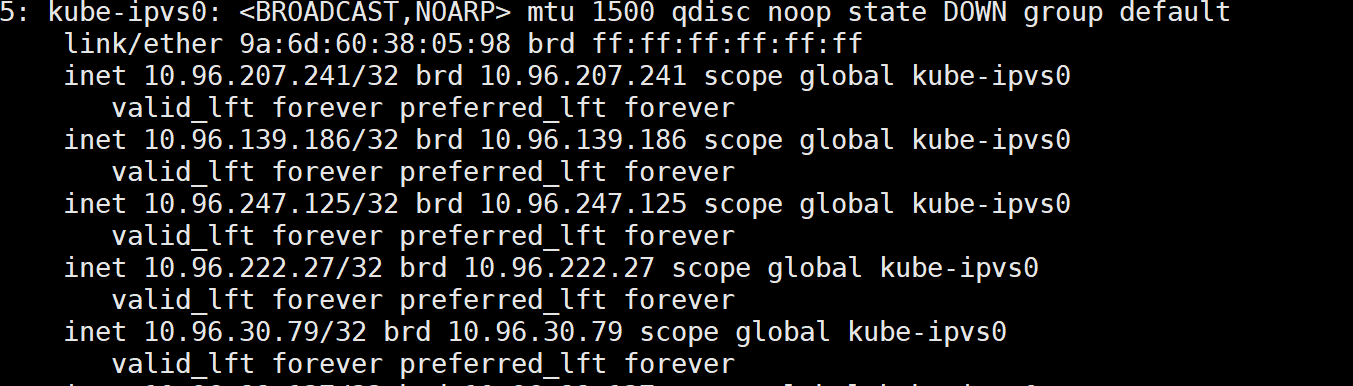
接着kube-proxy通过Linux的IPVS模块为这个 IP 地址添加三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式 来作为负载均衡策略。
通过ipvsadm查看
ipvsadm -ln |grep -C 5 10.96.148.206

可以看到虚拟server的IP即是Pod的地址,这样流量即向了目的地Pod。
以上我们先认识了Service这个API对象,接着讲到了service与endpoints和pod的关联,然后是service与kube-proxy的关系,以及kube-proxy的两种模式如何通过service的IP创建iptables、IPVS规则将流量转发到Pod。
希望小作文对你有些许帮助,如果内容有误请指正。
您可以随意转载、修改、发布本文,无需经过本人同意。【公号:容器云实践】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号