k8s网络模型与集群通信
在k8s中,我们的应用会以pod的形式被调度到各个node节点上,在设计集群如何处理容器之间的网络时是一个不小的挑战,今天我们会从pod(应用)通信来展开关于k8s网络的讨论。
小作文包含如下内容:
- k8s网络模型与实现方案
- pod内容器通信
- pod与pod通信
- pod与service通信
- 外网与service通信
k8s网络模型与实现方案
k8s集群中的每一个Pod(最小调度单位)都有自己的IP地址,即ip-per-pod模型。
在ip-per-pod模型中每一个pod在集群中保持唯一性,我们不需要显式地在每个 Pod 之间创建链接, 不需要处理容器端口到主机端口之间的映射。从端口分配、命名、服务发现、 负载均衡、应用配置和迁移的角度来看,Pod 可以被视作独立虚拟机或者物理主机。
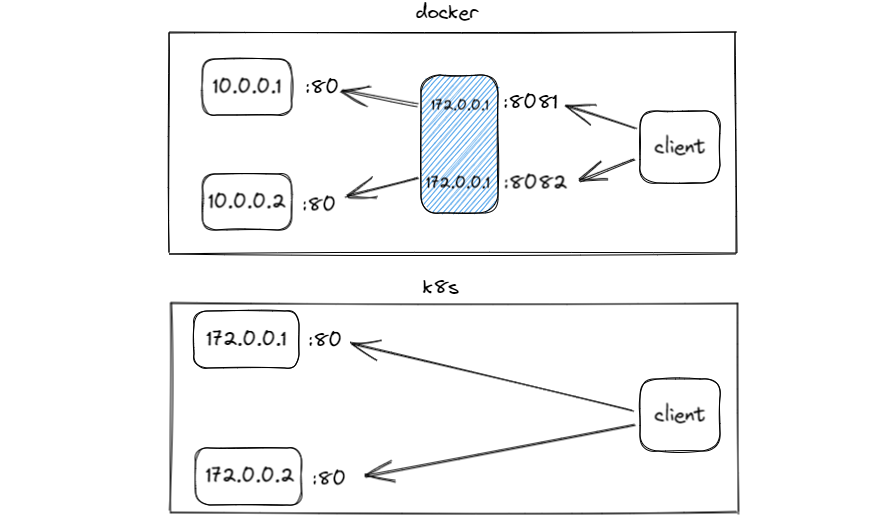
如下图,从表面上来看两个容器在docker网络与k8s网络中与client通信形式。
k8s是一套庞大的分布式系统,为了保持核心功能的精简(模块化)以及适应不同业务用户的网络环境,k8s通过CNI(Container Network Interface)即容器网络接口集成各种网络方案。这些网络方案必须符合k8s网络模型要求:
- 节点上的 Pod 可以不通过 NAT 和其他任何节点上的 Pod 通信
- 节点上的代理(比如:系统守护进程、kubelet)可以和节点上的所有Pod通信
备注:仅针对那些支持 Pods 在主机网络中运行的平台(比如:Linux):
- 那些运行在节点的主机网络里的 Pod 可以不通过 NAT 和所有节点上的 Pod 通信
如此操作,是不是有点像美团?将配送业务外包(CNI)给三方公司(实现方案),骑手是通过哪种飞机大炮(网络)送餐的我不管,只要符合准时、不撒漏(模型要求)等相关规矩这就是一次合格的配送。
CNI 做两件事,容器创建时的网络分配,和当容器被删除时释放网络资源。 常用的 CNI 实现方案有 Flannel、Calico、Weave以及各种云厂商根据自身网络推出的CNI插件如华为的 CNI-Genie、阿里云Terway。关于各实现方案的原理不是本次讨论重点,有机会单独写一篇。
pod内容器通信
Pod内容器非常简单,在同一个 Pod 内,所有容器共享存储、网络即使用同一个 IP 地址和端口空间,并且可以通过 localhost 发现对方。Pod 使用了一个中间容器 Infra,Infra 在 Pod 中首先被创建,而其他容器则通过 Join Network Namespace 的方式与 Infra 容器关联在一起。
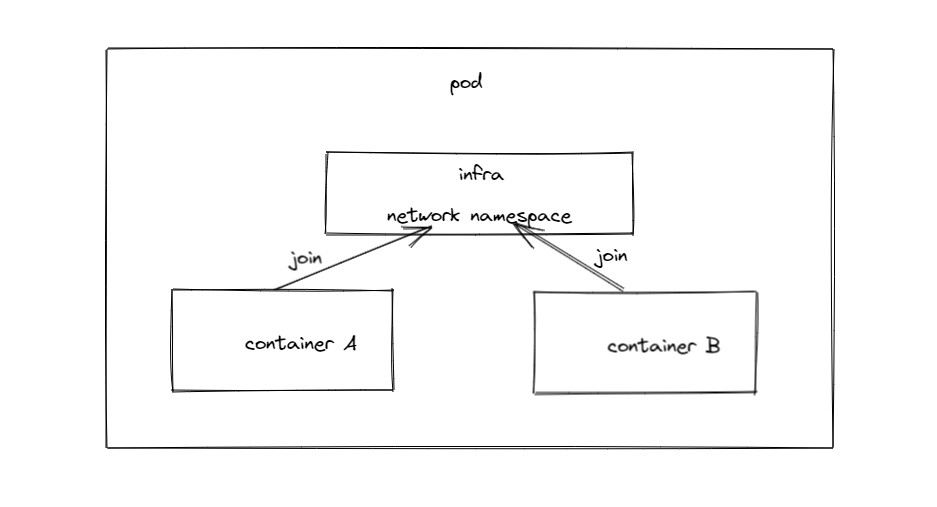
我们有一个pod包含busybox、nginx这两个容器
kubectl get pod -n training
NAME READY STATUS RESTARTS AGE
pod-localhost-765b965cfc-8sh76 2/2 Running 0 2m56s
在busybox中使用telnet连接nginx容器的 80端口看看。
kubectl exec -it pod-localhost-765b965cfc-8sh76 -c container-si1nrb -n training -- /bin/sh
# telnet localhost 80
Connected to localhost
一个pod有多个容器时可以通过-c指定进入的容器名(通过describe查看容器名称),显然通过localhost就可以轻松访问到同一个pod中的nginx容器80端口。这也是在许多关系密切的应用中通常会部署在同一个pod中。
pod与pod通信
- pod在同一主机
我们通过node选择器将两个pod调度到同一个node中
...
nodeSelector:
kubernetes.io/hostname: node2
...
两个容器分别获得一个IP地址,同样通过IP地址双方网络正常互通。
# kubectl get pod -o wide -n training
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-to-pod-64444686ff-w7c4g 1/1 Running 0 6m53s 100.82.98.206 node2 <none> <none>
pod-to-pod-busybox-7b9db67bc6-tl27c 1/1 Running 0 5m3s 100.82.98.250 node2 <none> <none>
# kubectl exec -it pod-to-pod-busybox-7b9db67bc6-tl27c -n training -- /bin/sh
/# telnet 100.82.98.206 80
Connected to 100.82.98.206
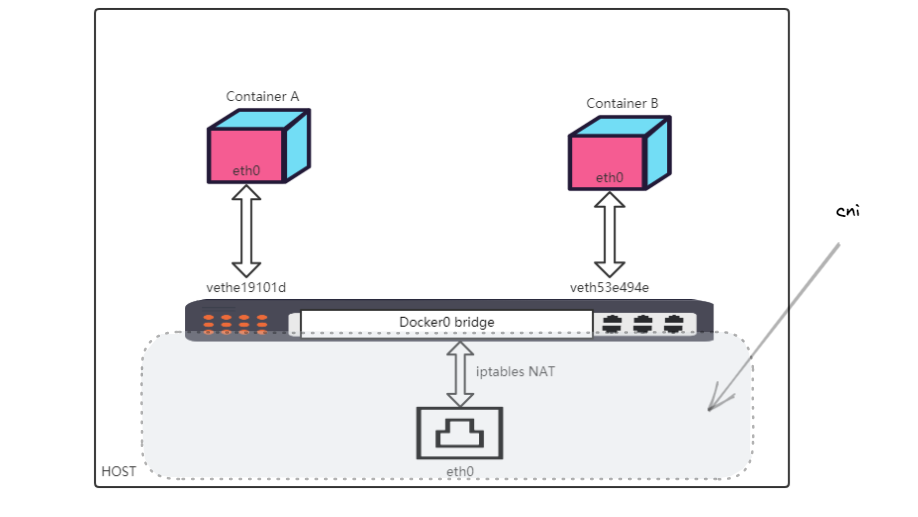
同一主机网络的pod互通和我们之前学习的docker bridge相似,通过linux网桥添加虚拟设备对veth pair连接容器和主机主机命名空间。具体可查看文章《docker容器网络bridge》。
我们把之前的图拿过来,在k8s中只不过把灰色部分替换成CNI方案实现。
- pod在不同主机
此时我们的pod分布如下:
kubectl get pod -o wide -n training
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-to-pod-64444686ff-w7c4g 1/1 Running 0 104m 100.82.98.206 node2 <none>
pod-to-pod-busybox-node2-6476f7b7f9-mqcw9 1/1 Running 0 42s 100.91.48.208 node3 <none>
# kubectl exec -it pod-to-pod-busybox-node2-6476f7b7f9-mqcw9 -n training -- /bin/sh
/ # telnet 100.82.98.206 80
Connected to 100.82.98.206
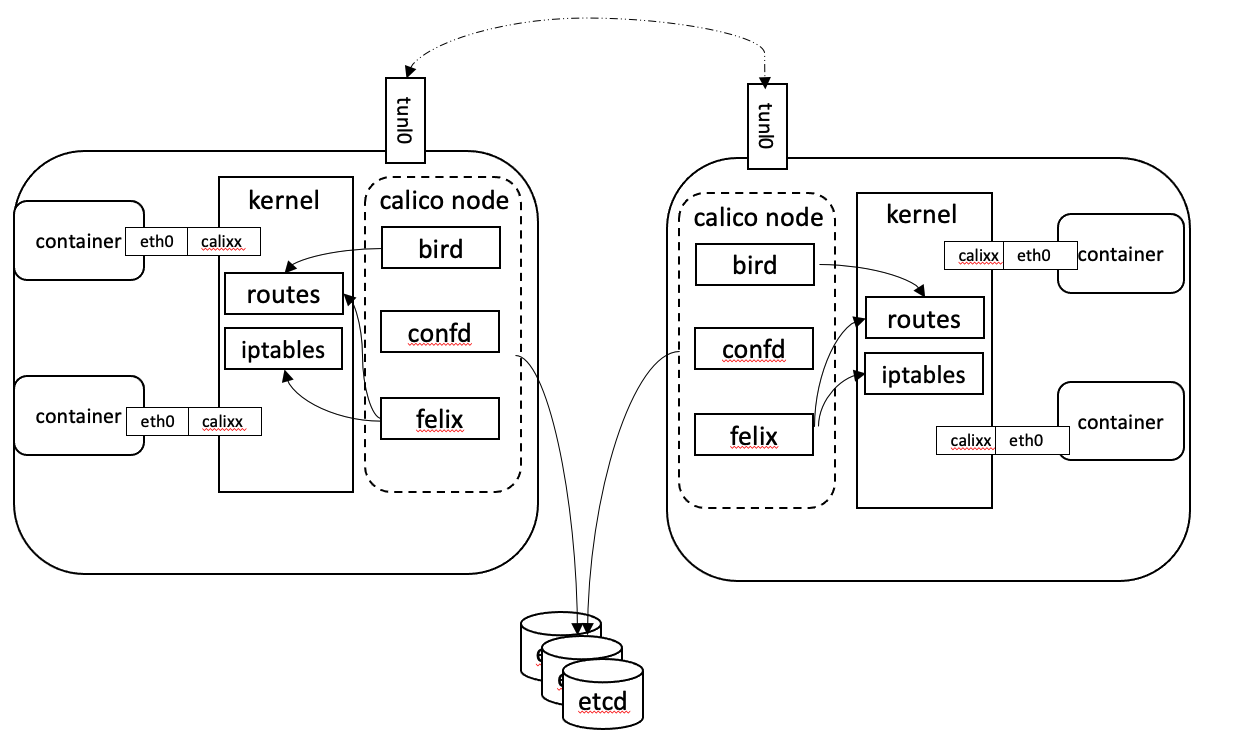
pod在不同主机的通信依赖于CNI插件,这里我们以Calico为例的做简单了解,从Calico架构图中可以看到每个node节点的自身依然采用容器网络模式,Calico在每个节点都利用Linux 内核实现了一个高效的虚拟路由器vRouter来负责数据转发。每个虚拟路由器将路由信息广播到网络中,并添加路由转发规则。同时基于iptables还提供了丰富的网络策略,实现k8s的Network Policy策略,提供容器间网络可达性限制的功能。
简单理解就是通过在主机上启动虚拟路由器(calico node),将每个主机作为路由器使用实现互联互通的网络拓扑。
Calico节点组网时可以直接利用数据中心的网络结构(L2或者L3),不需要额外的NAT、隧道或者Overlay Network,没有额外的封包解包,能够节约CPU运算,提高网络效率。
pod与service通信
我们知道在k8s中容器随时可能被摧毁,pod的IP显然不是持久的,会随着扩展或缩小应用规模、或者应用程序崩溃以及节点重启等而消失和出现。service 设计就是来处理这个问题。service可以管理一组 Pod 的状态,允许我们跟踪一组随时间动态变化的 Pod IP 地址。而客户端只需要知道service这个不变的虚拟IP就可以了。
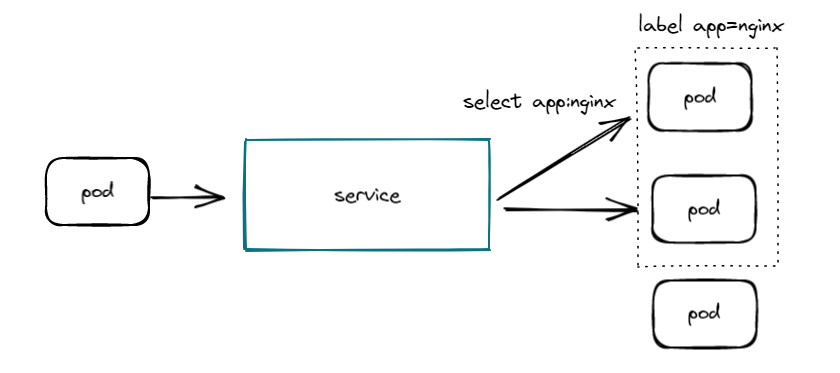
我们先来看看典型的service与pod使用,我们创建了一个service,标签选择器为app:nginx,将会路由到app=nginx标签的Pod上。
# kubectl get service -n training
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
training-service ClusterIP 10.96.229.238 <none> 8881/TCP 10m
Service对外暴露的端口8881,这样在集群的中的pod即可通过8881访问到与service 绑定的label为app=nginx的pod
kubectl run -it --image nginx:alpine curl --rm /bin/sh
/ # curl 10.96.229.238:8881
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
...
其实大多数时候在自动化部署服务时并不知道service ip,所以另一种常见方式通过DNS进行域名解析后,可以使用“ServiceName:Port”访问Service,可以自己尝试一下。
service 是如何做到服务发现的?
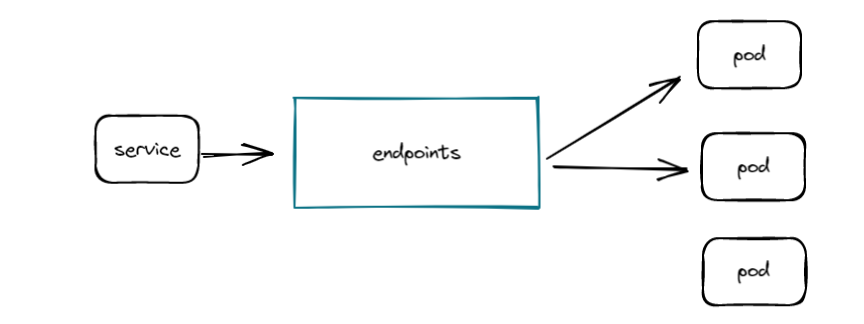
Endpoints是k8s中的一种资源对象,k8s通过Endpoints监控到Pod的IP,service又关联Endpoints从而实现Pod的发现。大致如下图所示,service的发现机制我们会在后面文章中做深入了解。
外网与service通信
其实所谓外网通信也是service的表现形式。
service几种类型和不同用途。
- ClusterIP:用于在集群内部互相访问的场景,通过ClusterIP访问Service,即我们上面所说的pod与service。
- NodePort:用于从集群外部访问的场景,通过节点上的端口访问Service。
- LoadBalancer:用于从集群外部访问的场景,其实是NodePort的扩展,通过一个特定的LoadBalancer访问Service,这个LoadBalancer将请求转发到节点的NodePort,而外部只需要访问LoadBalancer。
- None:用于Pod间的互相发现,这种类型的Service又叫Headless Service。
我们先来看NodePort:
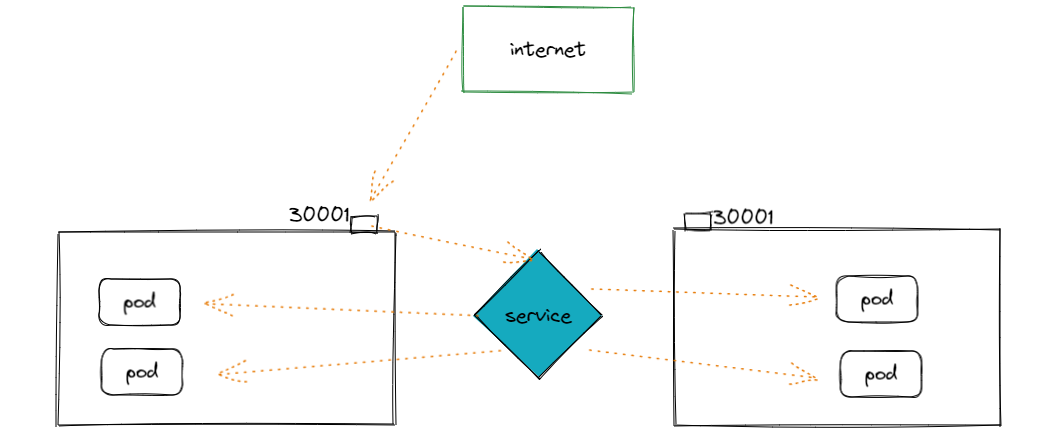
我们在service中指定type: NodePort创建出的service将会包含一个在所有node 开放的端口30678,这样我们访问任意节点IP:30678即可访问到我们的pod
# kubectl get service -n training
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
training-service NodePort 10.96.229.238 <none> 8881:30678/TCP 55m
# curl 192.168.1.86:30678
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
....
LoadBalancer类型和它名字一样,为负载均衡而生。它的结构如下图所示,
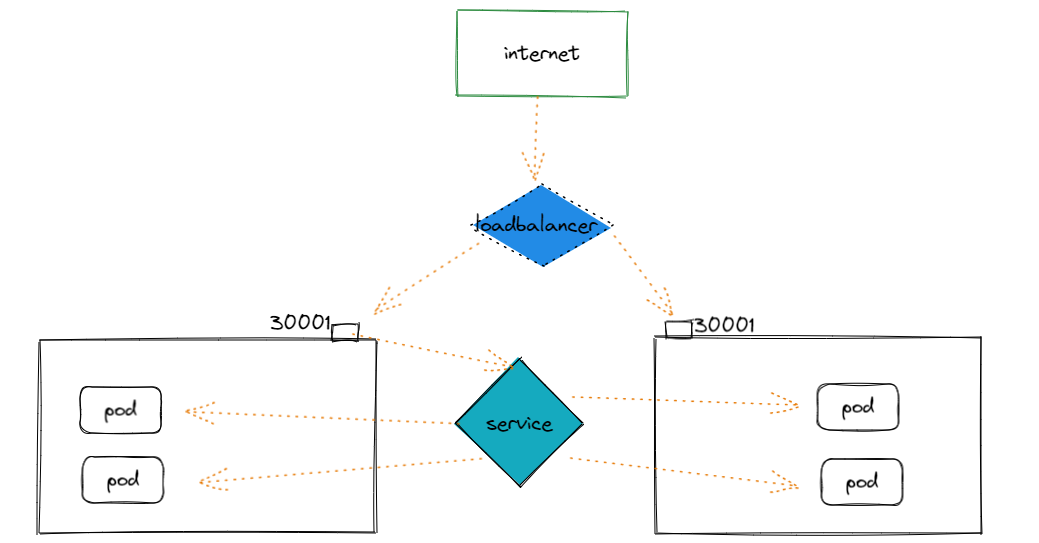
LoadBalancer本身不是属于Kubernetes的组件,如果使用云厂商的容器服务。通常会提供一套他们的负载均衡服务比如阿里云ACK的SLB、华为云的ELB等等。Service是基于四层TCP和UDP协议转发的,而k8s 另外一种资源对象Ingress可以基于七层的HTTP和HTTPS协议转发,可通过域名和路径做到更细粒度的划分,这是后话。
希望小作文对你有些许帮助,如果内容有误请指正。
您可以随意转载、修改、发布本文,无需经过本人同意。 通过博客阅读:iqsing.github.io

 浙公网安备 33010602011771号
浙公网安备 33010602011771号