用Python实时获取steam特惠游戏数据
前言
Steam是由美国电子游戏商Valve于2003年9月12日推出的数字发行平台,被认为是计算机游戏界最大的数码发行平台之一,Steam平台是全球最大的综合性数字发行平台之一。玩家可以在该平台购买、下载、讨论、上传和分享游戏和软件。

而每周的steam会开启了一轮特惠,可以让游戏打折,而玩家就会购买心仪的游戏
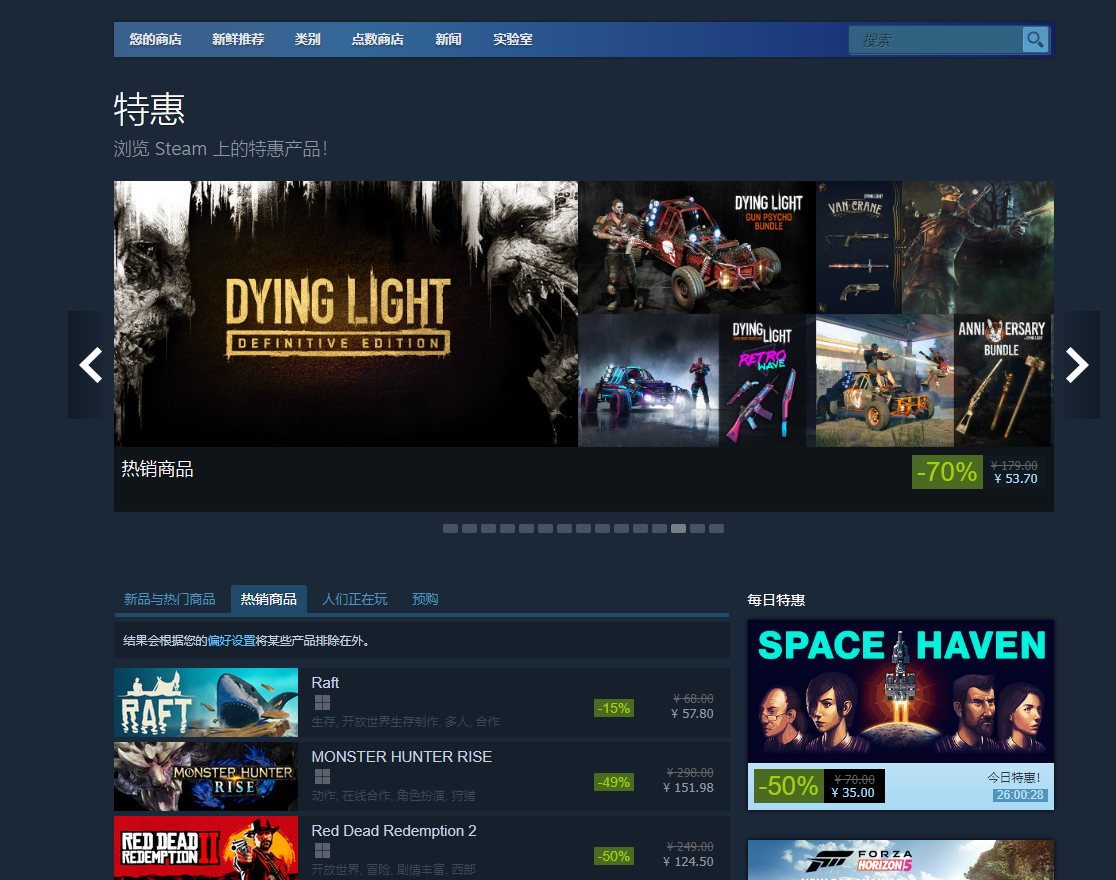
传说每次有大折扣,无数的玩家会去购买游戏,可以让G胖亏死

所以,我就在想,可不可以用Python收集steam所有每周特惠游戏的数据
对于本篇文章有疑问的同学可以加【资料白嫖、解答交流群:753182387】
- Python 3.8
- Pycharm
import random
import time
import requests
import parsel
import csv
模块可以pycharm里直接安装,输入pip install XXX(模块名)就行
url = f'https://store.steampowered.com/contenthub/querypaginated/specials/TopSellers/render/?query=&start=1&count=15&cc=TW&l=schinese&v=4&tag='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
html_data = response.json()['results_html']
print(html_data)
这样网页源代码就获取到了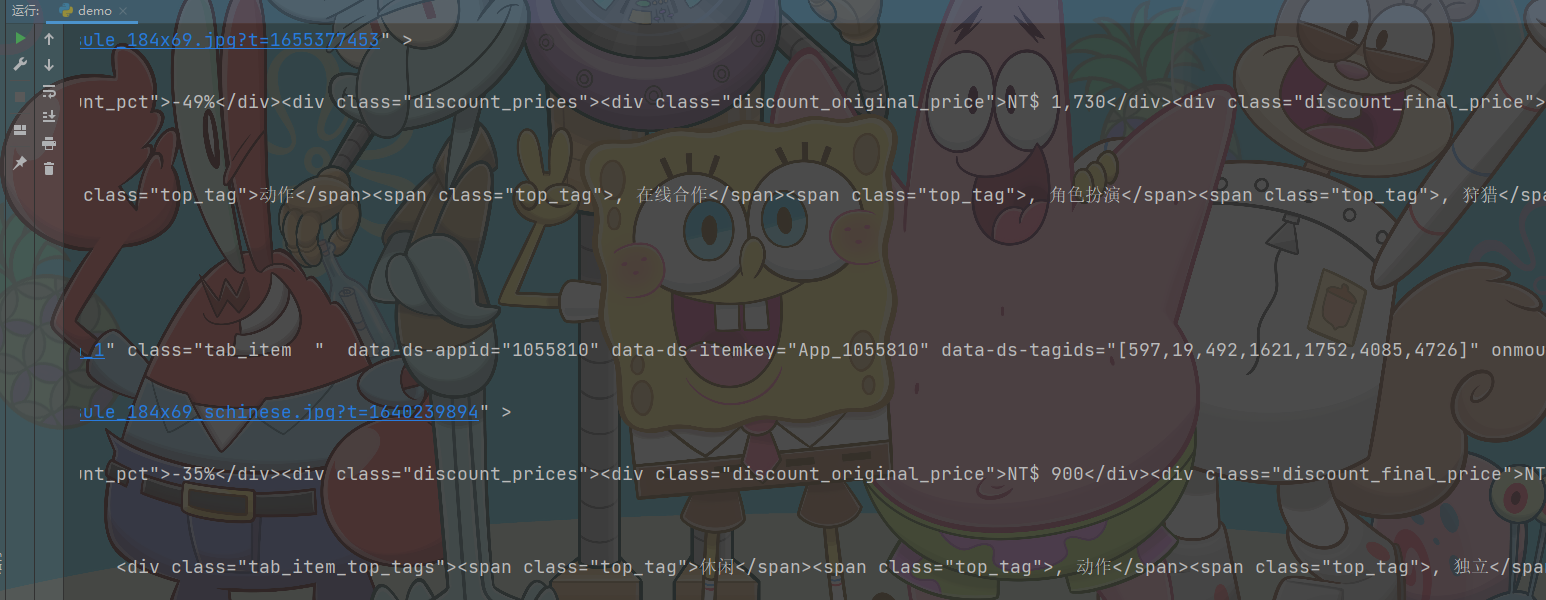
selector = parsel.Selector(html_data)
lis = selector.css('a.tab_item')
for li in lis:
href = li.css('::attr(href)').get()
title = li.css('.tab_item_name::text').get()
tag_list = li.css('.tab_item_top_tags .top_tag::text').getall()
tag = ''.join(tag_list)
price = li.css('.discount_original_price::text').get()
price_1 = li.css('.tab_item_discount .discount_final_price::text').get()
discount = li.css('.tab_item_discount .discount_pct::text').get()
print(title, tag, price, price_1, discount, href)
先把数据保存进字典里面
dit = {
'游戏': title,
'标签': tag,
'原价': price,
'售价': price_1,
'折扣': discount,
'详情页': href,
}
csv_writer.writerow(dit)
最后保存到csv里
f = open('游戏_1.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'游戏',
'标签',
'原价',
'售价',
'折扣',
'详情页',
])
csv_writer.writeheader()
前言
Steam是由美国电子游戏商Valve于2003年9月12日推出的数字发行平台,被认为是计算机游戏界最大的数码发行平台之一,Steam平台是全球最大的综合性数字发行平台之一。玩家可以在该平台购买、下载、讨论、上传和分享游戏和软件。

而每周的steam会开启了一轮特惠,可以让游戏打折,而玩家就会购买心仪的游戏

传说每次有大折扣,无数的玩家会去购买游戏,可以让G胖亏死

不过,由于种种原因,我总会错过一些想玩的游戏的特惠价!!!
所以,我就在想,可不可以用Python收集steam所有每周特惠游戏的数据
代码部分
开发环境
- Python 3.8
- Pycharm
先导入本次所需的模块
import random
import time
import requests
import parsel
import csv
模块可以pycharm里直接安装,输入pip install XXX(模块名)就行

请求数据
url = f'https://store.steampowered.com/contenthub/querypaginated/specials/TopSellers/render/?query=&start=1&count=15&cc=TW&l=schinese&v=4&tag='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
获取请求的数据
html_data = response.json()['results_html']
print(html_data)
这样网页源代码就获取到了

解析数据
selector = parsel.Selector(html_data)
lis = selector.css('a.tab_item')
for li in lis:
href = li.css('::attr(href)').get()
title = li.css('.tab_item_name::text').get()
tag_list = li.css('.tab_item_top_tags .top_tag::text').getall()
tag = ''.join(tag_list)
price = li.css('.discount_original_price::text').get()
price_1 = li.css('.tab_item_discount .discount_final_price::text').get()
discount = li.css('.tab_item_discount .discount_pct::text').get()
print(title, tag, price, price_1, discount, href)

保存数据
先把数据保存进字典里面
dit = {
'游戏': title,
'标签': tag,
'原价': price,
'售价': price_1,
'折扣': discount,
'详情页': href,
}
csv_writer.writerow(dit)
最后保存到csv里
f = open('游戏_1.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'游戏',
'标签',
'原价',
'售价',
'折扣',
'详情页',
])
csv_writer.writeheader()
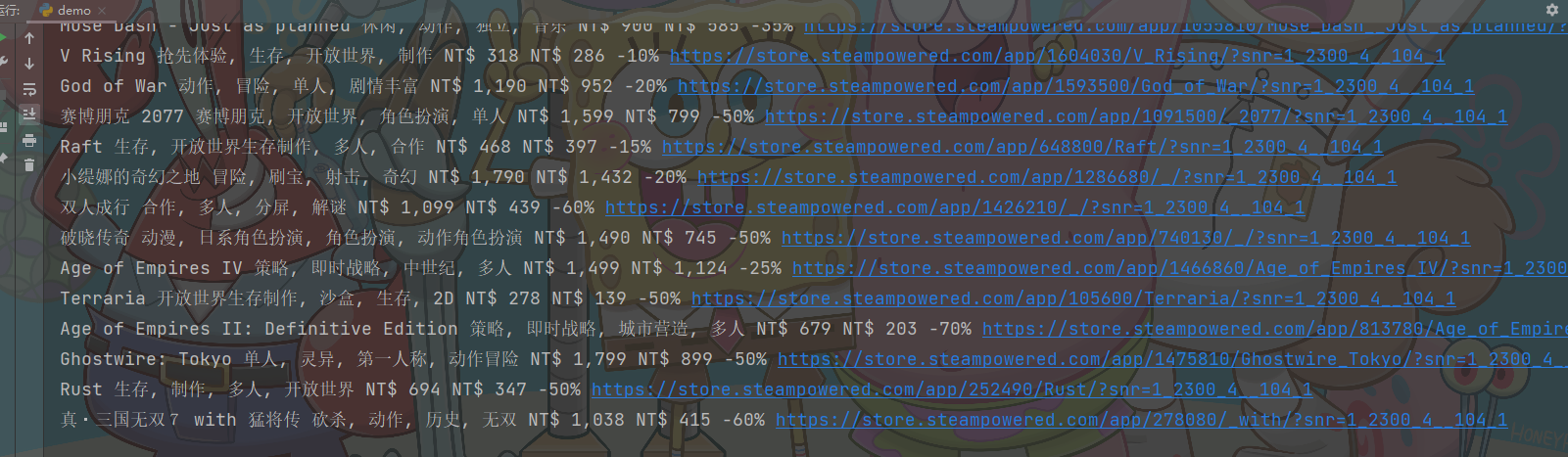
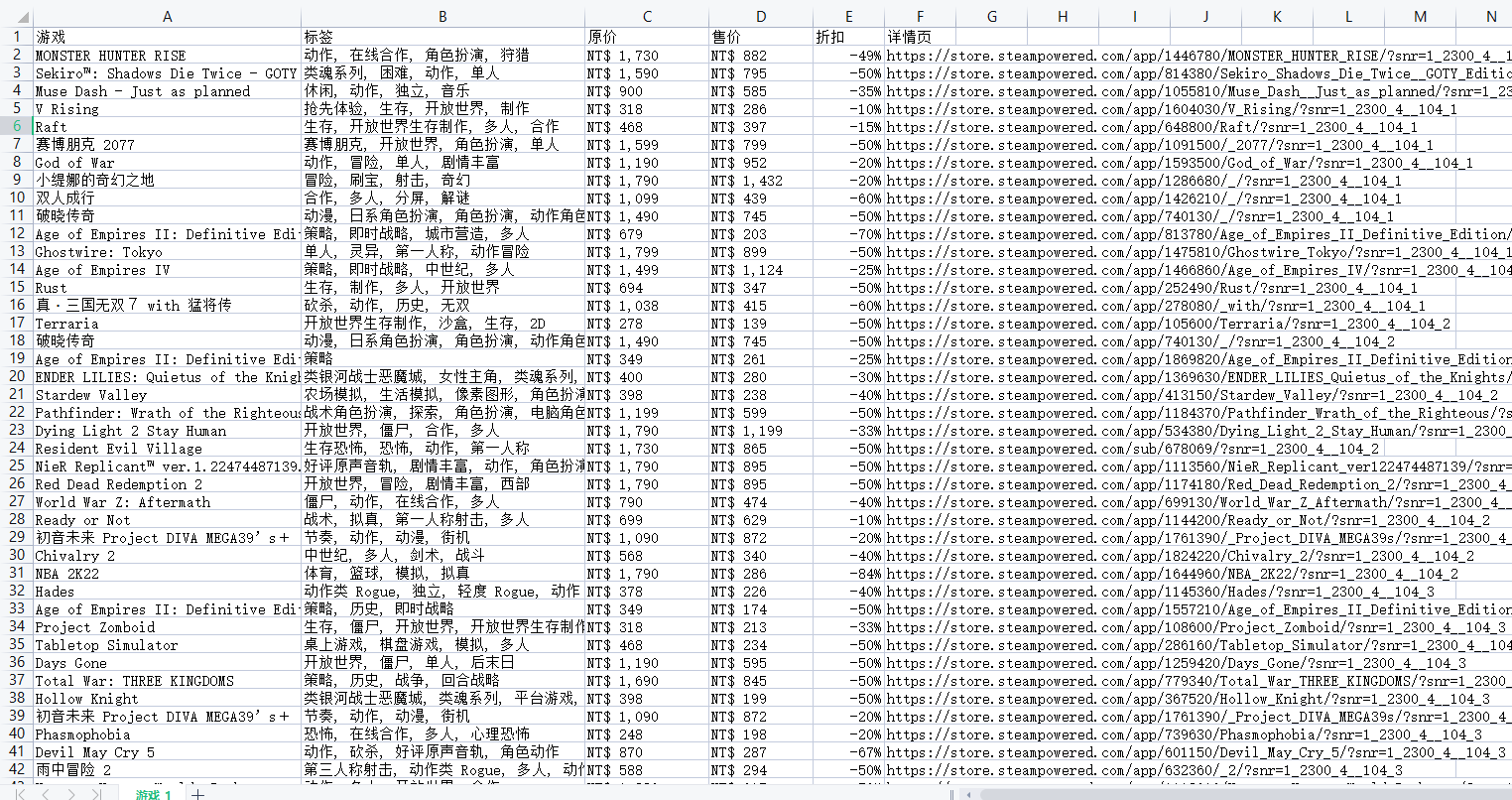
最后结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号