【Python爬虫】尺度太大了!爬一个专门看小姐姐的网站,写一段紧张刺激的代码(附源码)
前言
今天我们通过Python爬取小姐姐图片网站上的美图,零基础学会通用爬虫,当然我们还可以实现多线程爬虫,加快爬虫速度
- python 3.6
- pycharm
- requests >>> pip install requests
- re
- time
- concurrent.futures
爬取单个相册内容:
- 找到目标 https://https://www.kanxiaojiejie.com/img/6509
- 发送请求 (人为操作: 访问网站)
- 获取数据 (HTML代码 就是服务器返回的数据)
- 数据提取 (筛选里面的内容)
HTML网页代码 - 保存数据 (把图片下载下来)


import requests import parsel import re import os page_html = requests.get('https://www.kanxiaojiejie.com/page/1').text pages = parsel.Selector(page_html).css('.last::attr(href)').get().split('/')[-1] for page in range(1, int(pages) + 1): print(f'==================正在爬取第{page}页==================') response = requests.get(f'https://www.kanxiaojiejie.com/page/{page}') data_html = response.text # 提取详情页 zip_data = re.findall('<a href="(.*?)" target="_blank"rel="bookmark">(.*?)</a>', data_html) for url, title in zip_data: print(f'----------------正在爬取{title}----------------') if not os.path.exists('img/' + title): os.mkdir('img/' + title) resp = requests.get(url) url_data = resp.text selector = parsel.Selector(url_data) img_list = selector.css('p>img::attr(src)').getall() for img in img_list: img_data = requests.get(img).content img_name = img.split('/')[-1] with open(f"img/{title}/{img_name}", mode='wb') as f: f.write(img_data) print(img_name, '爬取成功!!!') print(title,'爬取成功!!!')

import requests # 第三方模块 pip install requests import re # 正则表达式模块 内置模块 import time import concurrent.futures import os import parsel
def get_response(html_url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36' } # 为什么这里要 requests.get() post() 请求会更安全... response = requests.get(url=html_url, headers=headers) return response
def save(title, img_url): img_data = requests.get(img_url).content img_name = img_url.split('/')[-1] with open("img\\" + title + '\\' + img_name, mode='wb') as f: f.write(img_data)
def parse_1(data_html): zip_data = re.findall('<a href="(.*?)" target="_blank"rel="bookmark">(.*?)</a>', data_html, re.S) return zip_data
def parse_2(html_data): selector = parsel.Selector(html_data) img_list = selector.css('p>img::attr(src)').getall() return img_list
def mkdir_img(title): if not os.path.exists('img\\' + title): os.mkdir('img\\' + title)
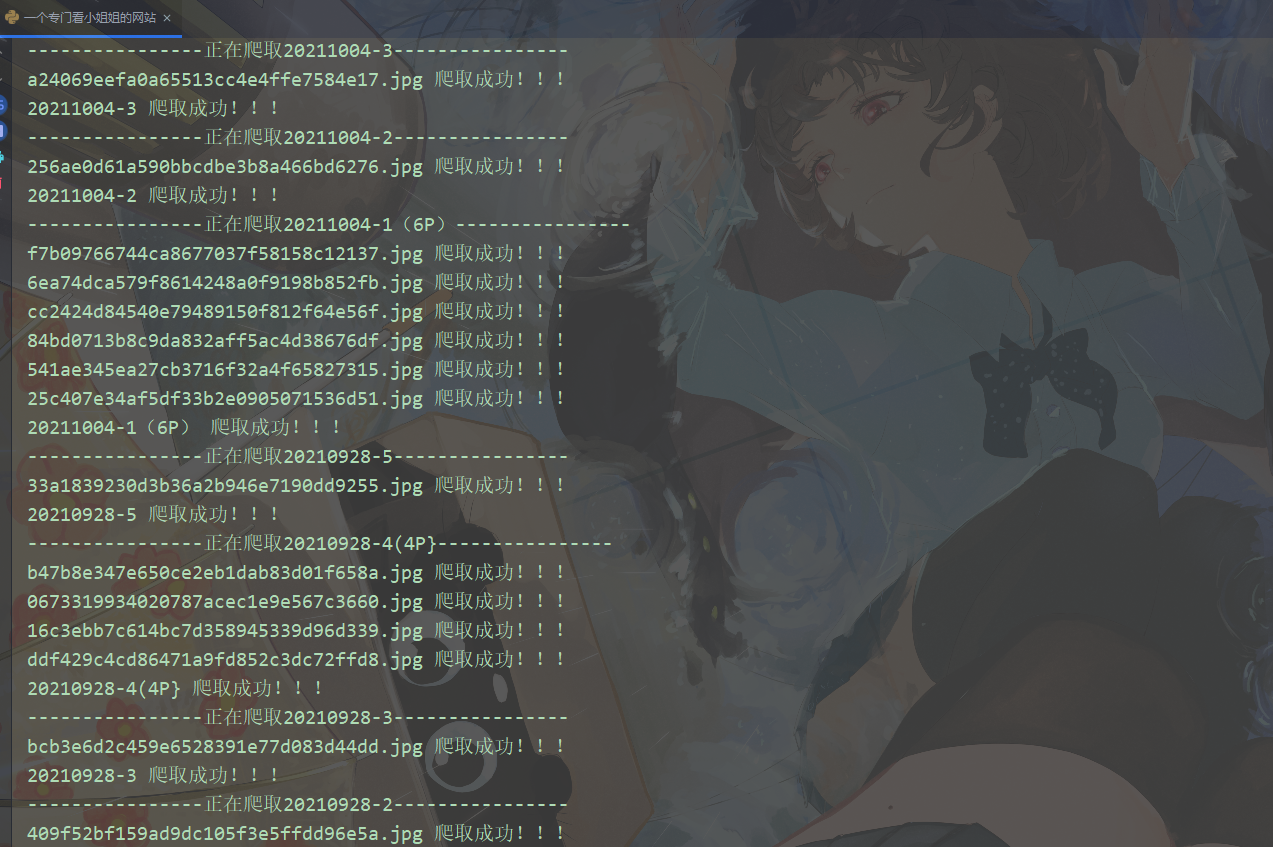
def main(html_url): html_data = requests.get(html_url).text zip_data = parse_1(html_data) for url, title in zip_data: mkdir_img(title) html_data_2 = get_response(url).text img_list = parse_2(html_data_2) for img in img_list: save(title, img) print(title, '爬取成功!!!')
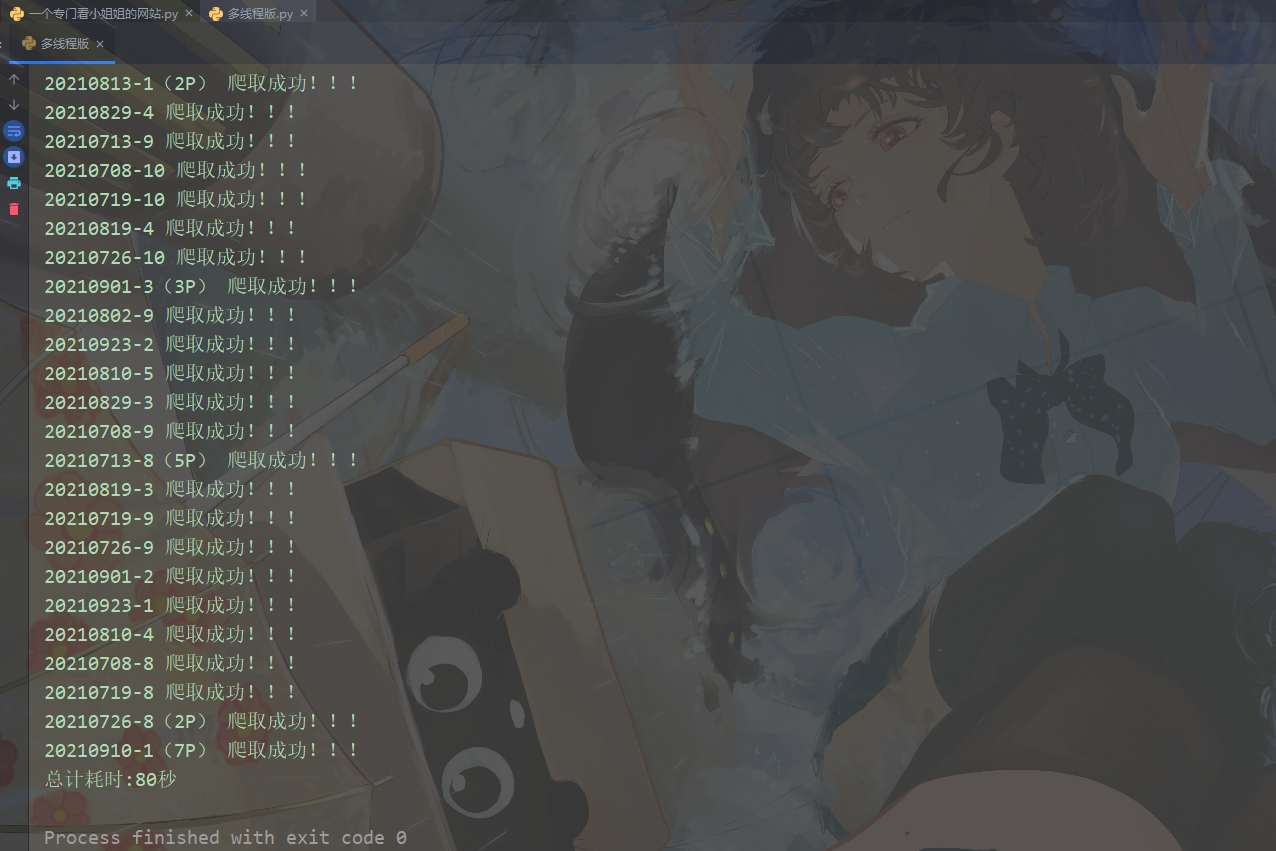
if __name__ == '__main__': time_1 = time.time() exe = concurrent.futures.ThreadPoolExecutor(max_workers=10) for page in range(1, 11): url = f'https://www.kanxiaojiejie.com/page/{page}' exe.submit(main, url) exe.shutdown() time_2 = time.time() use_time = int(time_2) - int(time_1) print(f'总计耗时:{use_time}秒')