Python爬虫+数据可视化:爬取美团烤肉数据,并进行数据可视化展示结果,让你国庆节旅游精准定位美食
环境介绍:
- python 3.6
- pycharm 安装包 安装教程 使用教程 激活码 插件(翻译插件/汉化插件/主题)
- Jupyter Notebook
- 动态数据抓包演示
- json数据解析
- requests模块的使用
- 保存csv
- 发送请求, 对于找到数据包发送请求
- 获取数据, 根据服务器给你返回的response数据来的
- 解析数据, 提取我们想要的内容数据
- 保存数据, 保存到csv文件
import requests # 数据请求 第三方模块 pip install requests import pprint # 格式化输出模块 import csv # csv模块 import time # 时间模块
url = 'https://apimobile.meituan.com/group/v4/poi/pcsearch/70' data = { 'uuid': '6e481fe03995425389b9.1630752137.1.0.0', 'userid': '266252179', 'limit': '32', 'offset': page, 'cateId': '-1', 'q': '烤肉', 'token': '4MJy5kaiY_0MoirG34NJTcVUbz0AAAAAkQ4AAF4NOv8TNNdNqymsxWRtJVUW4NjQFW35_twZkd49gZqFzL1IOHxnL0s4hB03zfr3Pg', } # 请求头: 把python代码进行伪装成浏览器 [披着羊皮的狼] 封IP 就用IP代理更换IP # 请求头 都是可以从开发者工具里面直接复制粘贴 # ser-Agent: 浏览器的基本信息 # Referer: 防盗链 告诉服务器我们发送的请求是哪里来的 比如: 西游记唐僧[来自动土大唐的和尚][唐朝比较盛世] headers = { 'Referer': 'https://chs.meituan.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36' } # 发送请求 response = requests.get(url=url, params=data, headers=headers)
for index in result: # pprint.pprint(index) # f'{}' 字符串格式化 index_url = f'https://www.meituan.com/meishi/{index["id"]}/' # ctrl + D dit = { '店铺名称': index['title'], '店铺评分': index['avgscore'], '评论数量': index['comments'], '人均消费': index['avgprice'], '所在商圈': index['areaname'], '店铺类型': index['backCateName'], '详情页': index_url, } csv_writer.writerow(dit) print(dit)
f = open('烤肉数据1.csv', mode='a', encoding='utf-8', newline='') csv_writer = csv.DictWriter(f, fieldnames=[ '店铺名称', '店铺评分', '评论数量', '人均消费', '所在商圈', '店铺类型', '详情页', ]) csv_writer.writeheader() # 写入表头

import pandas as pd import numpy as np from pyecharts.charts import * from pyecharts import options as opts from pyecharts.globals import ThemeType #引入主题 df = pd.read_csv('烤肉数据.csv',encoding='utf-8',engine="python") df.sample(5)

import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置加载的字体名 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 fig,axes=plt.subplots(2,1,figsize=(12,12)) sns.regplot(x='人均消费',y='店铺评分',data=df,color='r',marker='+',ax=axes[0]) sns.regplot(x='评论数量',y='店铺评分',data=df,color='g',marker='*',ax=axes[1])

df2 = df.groupby('所在商圈')['店铺名称'].count() df2 = df2.sort_values(ascending=True)[-10:] df2 = df2.round(2) c = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND)) .add_xaxis(df2.index.tolist()) .add_yaxis("",df2.tolist()).reversal_axis() #X轴与y轴调换顺序 .set_global_opts(title_opts=opts.TitleOpts(title="商圈烤肉店数量top10",subtitle="数据来源:美团",pos_left = 'center'), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小 yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小 ) .set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right')) ) c.render_notebook()

df4 = df.groupby('评分类型')['店铺名称'].count() df4 = df4.sort_values(ascending=False) regions = df4.index.tolist() values = df4.tolist() c = ( Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND)) .add("", [z for z in zip(regions,values)]) .set_global_opts(title_opts=opts.TitleOpts(title="不同评分类型店铺数量",subtitle="数据来源:美团",pos_top="-1%",pos_left = 'center')) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18)) ) c.render_notebook()

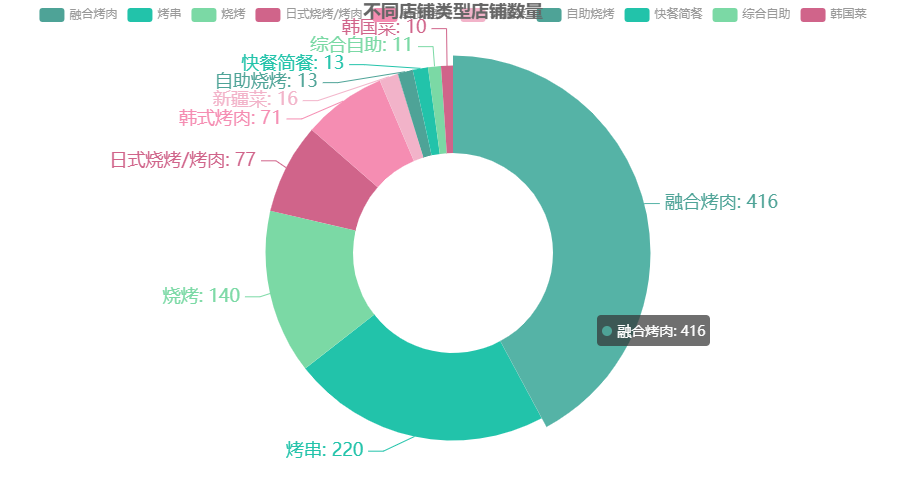
df6 = df.groupby('店铺类型')['店铺名称'].count() df6 = df6.sort_values(ascending=False)[:10] df6 = df6.round(2) regions = df6.index.tolist() values = df6.tolist() c = ( Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND)) .add("", [i for i in zip(regions,values)],radius=["40%", "75%"]) .set_global_opts(title_opts=opts.TitleOpts(title="不同店铺类型店铺数量",pos_top="-1%",pos_left = 'center')) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}",font_size=18)) ) c.render_notebook()
df6 = df.groupby('店铺类型')['店铺评分'].mean() df6 = df6.sort_values(ascending=True) df6 = df6.round(2) df6 = df6.tail(10) c = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND)) .add_xaxis(df6.index.tolist()) .add_yaxis("",df6.tolist()).reversal_axis() #X轴与y轴调换顺序 .set_global_opts(title_opts=opts.TitleOpts(title="不同店铺类型评分",subtitle="数据来源:美团",pos_left = 'center'), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小 yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小 ) .set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right')) ) c.render_notebook()

df7 = df.groupby('店铺类型')['评论数量'].sum() df7 = df7.sort_values(ascending=True) df7 = df7.tail(10) c = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND)) .add_xaxis(df7.index.tolist()) .add_yaxis("",df7.tolist()).reversal_axis() #X轴与y轴调换顺序 .set_global_opts(title_opts=opts.TitleOpts(title="不同店铺类型评论人数",subtitle="数据来源:美团",pos_left = 'center'), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小 yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小 ) .set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right')) ) c.render_notebook()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号