
Python爬虫案例:逆向分析xx音乐请求参数(支持下载SQ超品音质)
前言
现在的音乐平台,很多歌曲,要开VIP才能听,这没什么。
但是都开会员了,下载歌曲还要另外收费,这我就不能忍了
是你们逼我动手的
- requests
- urllib.parse
- prettytable 打印表格 控制台 输出的表格变好看
- 版本:anaconda5.2.0 (python3.6.5)
- 编辑器: pycharm
# 发送网络请求的第三方模块 import requests # 格式化打印的内置模块 import pprint import prettytable as pt
url = f'http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={searchKey}&pn=1&rn=30'
遭遇到了反爬,添加一些伪装,让酷我音乐认为我当前是一个浏览器

headers = { # 辨别 用户的身份 'Cookie': 'Hm_lvt_cdb524f42f0ce19b1fasd071123a4797=1631621725; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1631621725; _ga=GA1.2.861666777.1631621725; _gid=GA1.2.433324540.1631621725; _gat=1; kw_token=6YMC3KUGVVO', # 指定请求资源的域名 'Host': 'www.kuwo.cn', # 认证令牌 'csrf': '6YMC3KUGVVO', # 防盗链: 用来跟踪web请求来自哪个页面 是从哪个网站上面来的 'Referer': 'http://www.kuwo.cn/search/list?key=%E5%91%A8%E7%9D%B0%E4%BC%A6', # 浏览器的基本信息 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36' } requests.get(url, headers=headers).json()
key:关键词,用url解码歌手名字
searchKey = input('请输入你要下载的歌手或者歌曲名:') 取值,并表格式输出内容 json_data = requests.get(url, headers=headers).json() song_list = json_data['data']['list'] info_list = [] # 歌曲信息 (rid 歌曲名字 歌手名称) count = 0 # 歌曲序号 tb = pt.PrettyTable() # 实例化一个对象 tb.field_names = ['序号', '歌名', '歌手', '专辑'] for song in song_list: album = song['album'] # 专辑名称 artist = song['artist'] # 歌手名称 name = song['name'] # 歌曲名字 rid = song['rid'] # 歌曲id info_list.append([rid, name, artist]) # 音乐下载要用的列表 tb.add_row([count, name, artist, album]) # 表格多行追加 count += 1 print(tb)

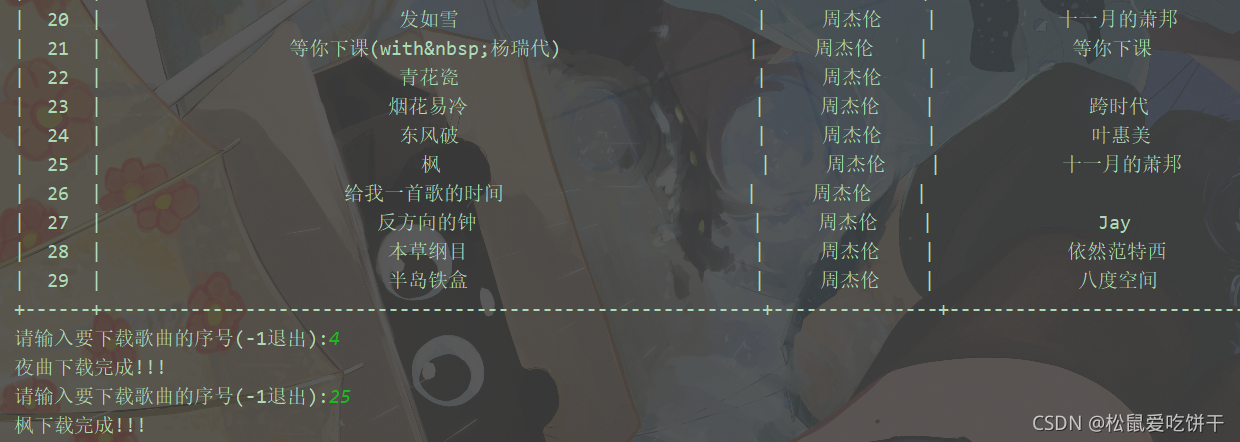
while True: input_index = eval(input('请输入要下载歌曲的序号(-1退出):')) if input_index == -1: break download_info = info_list[input_index] song_info_url = f'https://www.kuwo.cn/url?rid={download_info[0]}&type=convert_url3&br=320kmp3' music_url = requests.get(song_info_url, headers=headers).json()['url'] music_data = requests.get(music_url).content with open(f'C:/Users/Administrator/Desktop/新建文件夹/{download_info[1]}-{download_info[2]}.mp3', mode='wb') as f: f.write(music_data) print(f'{download_info[1]}下载完成!!!')
标签:
Python案例教学



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)