最新!Python爬虫项目案例讲解一步步教你爬取淘宝商品数据
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
完整代码可以加Python学习交流群:1039649593 找管理员免费领取
前言
随着互联网时代的到来,人们更加倾向于互联网购物,某宝又是电商行业的巨头,在某宝平台中有很多商家数据,今天带大家使用python+selenium工具获取这些公开的商家数据
环境介绍:
- python 3.6
- pycharm
- selenium
- csv
- time
- random
这次的受害者:淘宝购物平台
1. 创建一个浏览器对象
from selenium import webdriver driver = webdriver.Chrome()
2. 执行自动化页面操作
driver.get('https://www.taobao.com/') driver.maximize_window() # 最大化浏览器 driver.implicitly_wait(10) # 设置浏览器的隐式等待, 智能化的等待
到这一步,你就可以自己运行代码看看可不可以自动打开你的浏览器进入淘宝的首页
3. 根据关键字搜索商品, 解决登录
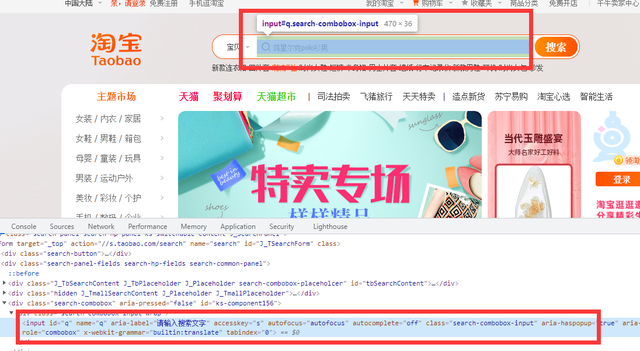
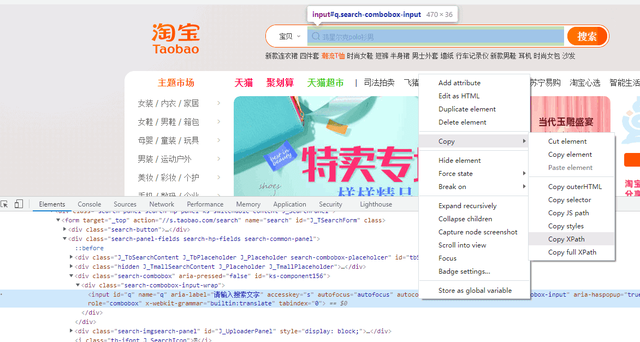
复制它的xpath,用xpath语法提取页面标签的元素
def search_product(keyword): # 输入框的标签对象 driver.find_element_by_xpath('//*[@id="q"]').send_keys(keyword) word = input('请输入你要搜索商品的关键字:')
运行代码

前面搞定了搜索框的,现在来写点击搜索按钮的,同样复制它的xpath
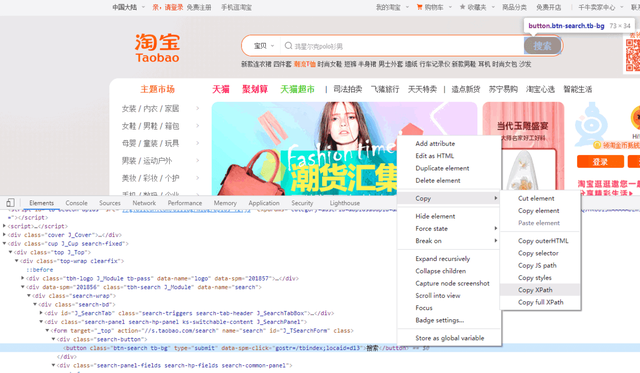
# 为了避免被检测 import time # 时间模块 内置模块 time.sleep(random.randint(1, 3)) # 随机休眠1到3秒 driver.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click()
4. 解决登录
点击了搜索按钮以后,会弹出登录界面给你,那就继续解决登录
driver.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys(TAO_USERNAME) time.sleep(random.randint(1, 2)) driver.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys(TAO_PASSWORD) time.sleep(random.randint(1, 2)) driver.find_element_by_xpath('//*[@id="login-form"]/div[4]/button').click()
5. 解析数据
获取目标数据的div标签
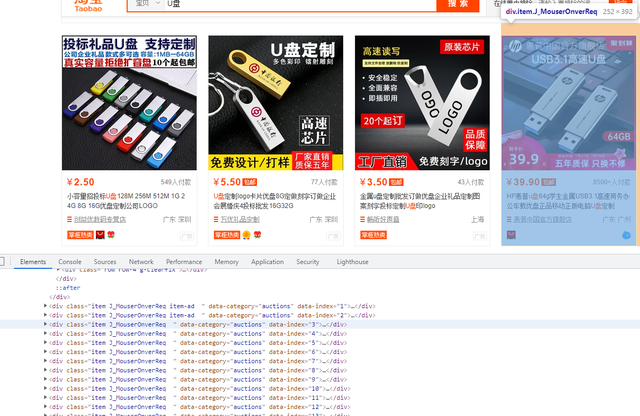
def parse_data(): # 所有div标签 divs = driver.find_elements_by_xpath('//div[@class="grid g-clearfix"]/div/div')
用for循环遍历取值
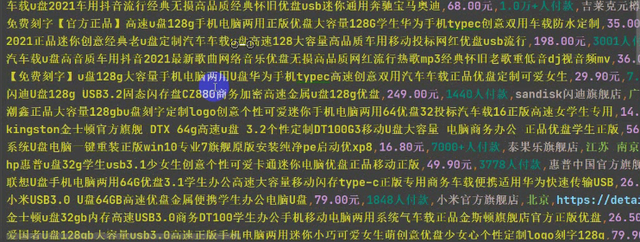
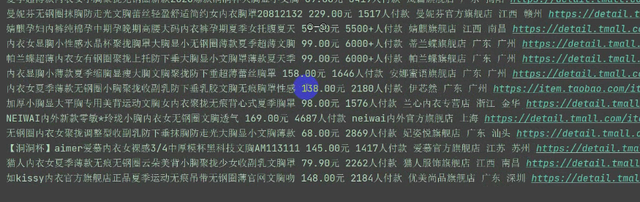
for div in divs: # 二次提取 title = div.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text price = div.find_element_by_xpath('.//strong').text + '元' # 商品价格 # 手写 deal = div.find_element_by_xpath('.//div[@class="deal-cnt"]').text # 付款人数 # 手写 name = div.find_element_by_xpath('.//div[@class="shop"]/a/span[2]').text # 店铺名称 # 手写 location = div.find_element_by_xpath('.//div[@class="location"]').text # 店铺地址 # 手写 detail_url = div.find_element_by_xpath('.//div[@class="pic"]/a').get_attribute('href') # 详情页地址 # 手写 print(title, price, deal, name, location, detail_url)
运行代码,可以看到获取的数据了

6. 最后一步,保存数据
import csv with open('淘宝.csv', mode='a', encoding='utf-8', newline='') as f: csv_write = csv.writer(f) # 实例化csv模块写入对象 csv_write.writerow([title, price, deal, name, location, detail_url])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号