
kafka基础知识
转:https://blog.csdn.net/weixin_45943729/article/details/105771846
消息队列-Kafka
一、消息队列(MQ)
消息队列是存储数据的一个中间件,可以理解为一个容器。
消息:传输数据的基本单位。
消息从源被发往队列中,消费者可以拉取消息进行消费,如果消费者目前没有消费的打算,则消息队列会保留消息,直到消费者有消费的打算。
1.异步
源中的消息发往消息队列之后,省略了之后业务的响应,消息队列直接进行回执。后续的业务直接订阅消息队列进行消费。
2.解耦
将多种耦合的业务流程进行解耦,当某个业务挂了之后,其他业务并不影响。
3.平峰
源中的数据峰值特别高的时候直接打到消费者,可能把服务器打挂了,这是不可取的。所以设置一个消息队列中间件可以进行平峰,来缓存消息。
二、Kafka
Kafka是一个基于发布订阅模式的消息队列,发布到消息队列里的一条消息可以被多个消费者进行消费。
1、Kafka架构
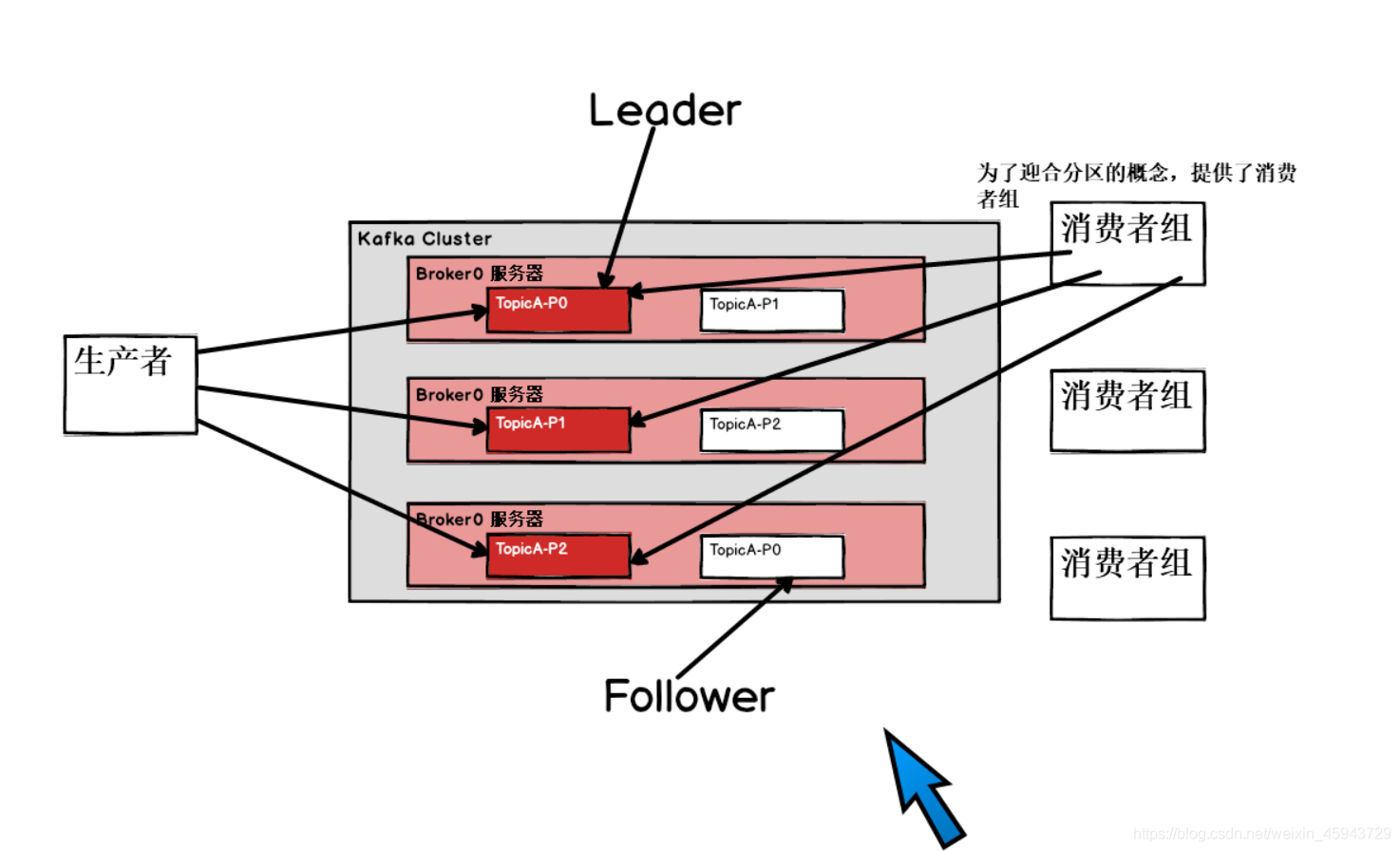
1)生产者:Producer 消息队列的生产者,向Kafka的topic里打入数据。
2)消费者:Consumer 消息队列的消费者,消费Kafka的topic里的数据。
3)消费者组:为了配合topic里数据分区的概念,就具有了消费者组,每一个分区的数据,由一个消费者组的一个消费者专门消费。消费者组就是一个订阅者。
4)Broker:一台Kafka服务器就是一个Broker,一个Broker里面可以存放多个不同的topic。
5)Topic:就是一个队列,生产者和消费者面向的是同一个topic。
6)Partition:一个topic可以分布到多个服务器上(broker)上,topic内部又会分成多个Partition,实际上写读数据都是对partition进行操作。
7)Replication:为了数据的安全可靠,Kafka提供了副本机制,节点上的partition配置了副本,每一个partition都具有leader和follower。
8)Leader:分区副本的主,生产者发送的对象和消费者消费数据的对象都是partition的leader。
9)Follower:实时从leader进行数据同步,当Leader挂了后,会从Follower里面选取新的Leader。
2、Kafka工作机制
生产者产生消息,以及消费者消费消息对应的都是topic。
topic是一个逻辑上的概念,而物理上,数据的处理的对象都是partition。
每一个partition都对应一个log文件,log里面存储的是producer生产的数据。producer生产的数据会不断的追加到log文件的末端。
每一条数据都有自己的offset,消费者在进行消费时,都会实时的记录自己消费到哪有一个offset,当挂掉之后,可以继续从上一个offset进行恢复。
3、Kafka存储文件
上述说到,每一个partition都对应着一个log,生产者生产的消息不断的追加log文件的末尾。为了防止log文件过大,Kafka使用分片和索引的机制,将每一个partition分为多个segment,每一个segment对应两个文件 .log和.index文件。
.index 文件存储大量的索引信息,.log文件存储大量的数据,索引文件元数据指的是对应.log文件中偏移量的地址。也就是说索引文件存储的是偏移量信息,通过索引文件中的偏移量可以对.log文件找到确切的数据。
4、Kafka分区策略
4.1 生产者分区策略:
1)指明partition分区下,按照指明的指进行分区,
2)没有指明partition情况下,但是有key值,按照key的hash值与partition分区数进行取余进行分区,
3)没有指明partition,也没有key值,按照轮询。
4.2 消费者分区策略:
1)轮询,
2)range。
5、数据可靠性保证
5.1 生产者是如何做到发送的数据如何保证精准发送到topic中呢?
topic里每个partition收到生产者发送的数据后,都需要向生产者发送回执ack
,如果生产者接受到ack后,在进行下一轮的发送。
否则会进行重新发送,所以会出现重复发送数据的现象。
5.2 什么时候进行回执呢?
保证follower与leader同步完成后,发送回执。
副本同步策略:
1)半数以上的follower完成同步,发送回执。
2)全部的follower完成同步,发送回执,
Kafka选择的是第二种
5.3 ack的应答机制
对于一些不是很重要的数据,可靠性要求不是很高,准许少量数据的丢失,没有必要等待follower全部同步完成之后,才进行下一步的操作。
1)ack = 0 ,producer不用等待ack。
2)ack = 1,producer等待ack,partition的leader落盘成功后返回ack。如果在leader发送回执之前,leader挂掉的化,会丢数据。
3)ack = -1 producer等待ack,partition的leader和follower全部落盘才会进行回执。
5.4 数据的不重复保障
1)Exactly once
当ack级别设置为-1时,会保证数据的不丢失,但会造成数据的重复。而ack的级别设置为0时,会保证数据的不重复,但不会保证数据的丢失。
Kafka通过幂等性,生产者不论发送多少条数据,都只会持久化一条。开启幂等性的producer会在初始化时候就分配一个PID,broker端可以跟去PID以及分区信息进行记录(<PID, Partition, SeqNumber>),只持久化一条数据。
但是PID重启就会发生变化,并且只能保证本分区内是Exactly once的。
2)Producer事物
为了实现跨分区的事物,全局设置了一个唯一Transaction ID,将producer的PID与TransID绑定。如果producer挂掉重启,通过TransID可以获取之前PID。
3)Consumer事物
对消费者来说,做到精准一次性消费,不重复消费数据就是最好的。所以offset的维护是Consumer消费数据是必须考虑的问题。
5.5 Kafka高效读写
1)producer在进行写数据的时候,是追加log文件的,顺序写磁盘,减少了寻址时间。
消费者来说,做到精准一次性消费,不重复消费数据就是最好的。所以offset的维护是Consumer消费数据是必须考虑的问题。
5.5 Kafka高效读写
1)producer在进行写数据的时候,是追加log文件的,顺序写磁盘,减少了寻址时间。
2)zero copy 零拷贝,不经过应用层,直接写数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号