关于HTTP请求走私攻击
0x00:写在前面
膜拜了国内译者分析翻译了BlackHat的一篇议题(HTTP Desync Attacks: Smashing into the Cell Next Door)
收获满满,正好结合一道CTF题目将此知识点进行巩固
[RoarCTF 2019]Easy Calc
复现地址:https://buuoj.cn/challenges
0x01:HTTP请求走私漏洞
在当前的网络环境中,不同的服务器以不同的姿势去实现RFC标准(包含了关于Internet的几乎所有重要的文字资料)
总体来说在网络中数据包的传输格式都是严格遵守着协议来规划的。但正是因为细微的差异性,对同一个HTTP请求,不同的服务器可能会产生不同的处理结果,安全风险就在此处产生了。
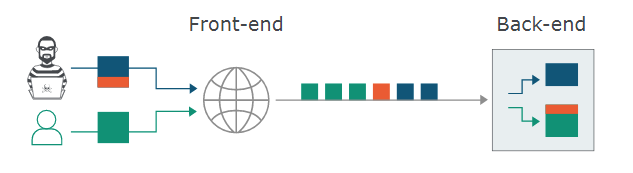
首先学习一下数据包传输遵守的协议-HTTP 1.1协议
在远古时期(HTTP1.0)之前的协议中,客户端每进行一次HTTP请求,就需要和服务器进行一次TCP交互(三次握手),基于当时的网络环境并不像如今web页面由多种网络资源组成,在当时仍然够用。但如今肯定是太消耗服务器资源,不适用当前的环境。所以HTTP1.0/1出现了。
这里介绍两个重要协议特性Keep-Alive&Pipeline
keep-alive肯定不陌生,在数据包中经常可以看到connection:close/keep-allive
所谓 Keep-Alive,就是在HTTP请求中增加一个特殊的请求头 Connection: Keep-Alive,告诉服务器,接收完这次HTTP请求后,不要关闭TCP链接,后面对相同目标服务器的HTTP请求,重用这一个TCP链接,这样只需要进行一次TCP握手的过程,可以减少服务器的开销,节约资源,还能加快访问速度。当然,这个特性在 HTTP1.1中是默认开启的。
Pipeline,在这里呢,客户端可以像流水线一样发送自己的HTTP请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端。
HTTP Pipelining(管线化)字段,它是将多个http请求批量提交,而不用等收到响应再提交的异步技术。如下图就是使用Pipelining和非Pipelining
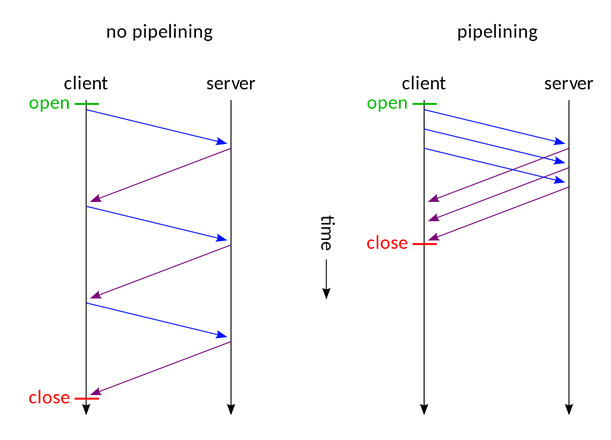
这意味着前端与后端必须短时间内对每个数据包的边界大小达成一致,否则,攻击者就可以构造发送一个特殊的数据包,在前端看来它是一个请求,但在后端却被解释为了两个不同的HTTP请求。
为了提高用户体验。很多站主选择CDN来进行加速,CDN原理类似nginx的反向代理,在源站前面加上一层反向代理服务器,当用户请求一些静态资源时,直接由代理服务器进行分配相关的资源服务器
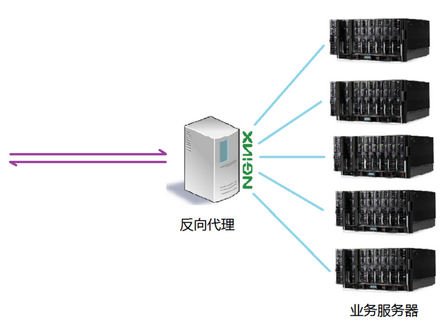
因为Keep-alive的特性,为了缓解服务器压力,一般来说,反向代理服务器与后端的源站服务器之间,会重用TCP链接。这也很容易理解,用户的分布范围是十分广泛,建立连接的时间也是不确定的,这样TCP链接就很难重用,而代理服务器与后端的源站服务器的IP地址是相对固定。
当我们向代理服务器发送一个精心构造的HTTP请求时,由于两者服务器的实现方式不同,可能代理服务器认为这是一个HTTP请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分,就算是走私的请求,当该部分对正常用户的请求造成了影响之后,就实现了HTTP走私攻击。
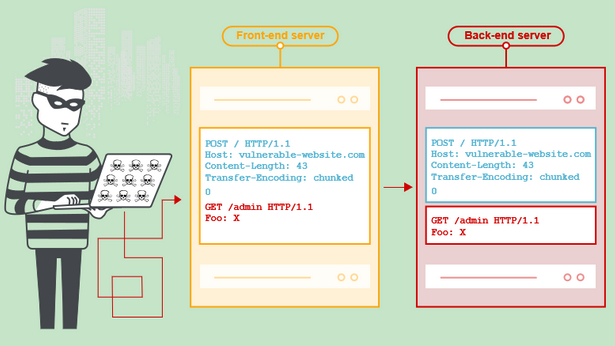
0x02:HTTP走私攻击的四种攻击方式
1:CL不为0(Content-length不为0)
所有不携带请求体的HTTP请求都有可能受此影响。这里用GET请求举例。
前端代理服务器允许GET请求携带请求体;后端服务器不允许GET请求携带请求体,它会直接忽略掉GET请求中的Content-Length头,不进行处理。这就有可能导致请求走私。
构造请求示例:
GET / HTTP/1.1\r\n Host: test.com\r\n Content-Length: 44\r\n GET / secret HTTP/1.1\r\n Host: test.com\r\n \r\n
\r\n是换行的意思,windows的换行是\r\n,unix的是\n,mac的是\r
漏洞触发
前端服务器收到该请求,读取Content-Length,判断这是一个完整的请求。
然后转发给后端服务器,后端服务器收到后,因为它不对Content-Length进行处理,由于Pipeline的存在,后端服务器就认为这是收到了两个请求,分别是:
第一个:
GET / HTTP/1.1\r\n Host: test.com\r\n
第二个
GET / secret HTTP/1.1\r\n Host: test.com\r\n
随即第二个请求造成了HTTP请求走私,成功被利用。
2:CL-CL
有些服务器不会严格的实现该规范,假设中间的代理服务器和后端的源站服务器在收到类似的请求时,都不会返回400错误。
但是中间代理服务器按照第一个Content-Length的值对请求进行处理,而后端源站服务器按照第二个Content-Length的值进行处理。
POST / HTTP/1.1\r\n Host: test.com\r\n Content-Length: 8\r\n Content-Length: 7\r\n 12345\r\n a
触发过程
中间代理服务器获取到的数据包的长度为8,将上述整个数据包原封不动的转发给后端的源站服务器。
而后端服务器获取到的数据包长度为7。当读取完前7个字符后,后端服务器认为已经读取完毕,然后生成对应的响应,发送出去。而此时的缓冲区去还剩余一个字母a,对于后端服务器来说,这个a是下一个请求的一部分,但是还没有传输完毕。
如果此时有一个其他的正常用户对服务器进行了请求:
GET /index.html HTTP/1.1\r\n Host: test.com\r\n
因为代理服务器与源站服务器之间一般会重用TCP连接。所以正常用户的请求就拼接到了字母a的后面,当后端服务器接收完毕后,它实际处理的请求其实是:
aGET /index.html HTTP/1.1\r\n Host: test.com\r\n
这时,恰巧被拼接上的数据包即会返回aGET request method not found报错。
3:CL-TE
CL-TE,就是当收到存在两个请求头的请求包时,前端代理服务器只处理Content-Length请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding请求头。
POST / HTTP/1.1\r\n Host: test.com\r\n ...... Connection: keep-alive\r\n Content-Length: 6\r\n Transfer-Encoding: chunked\r\n \r\n 0\r\n \r\n a
连续发送几次请求就可以获得响应。
触发过程
由于前端服务器处理Content-Length,所以这个请求对于它来说是一个完整的请求,请求体的长度为6,也就是
0\r\n \r\n a
当请求包经过代理服务器转发给后端服务器时,后端服务器处理Transfer-Encoding,当它读取到
0\r\n \r\n
认为已经读取到结尾了。
但剩下的字母a就被留在了缓冲区中,等待下一次请求。当我们重复发送请求后,发送的请求在后端服务器拼接成了类似下面这种请求:
aPOST / HTTP/1.1\r\n Host: test.com\r\n ... ...
服务器在解析时就会产生报错了,从而造成HTTP请求走私。
4:TE-CL
TE-CL,就是当收到存在两个请求头的请求包时,前端代理服务器处理Transfer-Encoding请求头,后端服务器处理Content-Length请求头。
POST / HTTP/1.1\r\n Host: test.com\r\n ...... Content-Length: 4\r\n Transfer-Encoding: chunked\r\n \r\n 12\r\n aPOST / HTTP/1.1\r\n \r\n 0\r\n \r\n
触发过程
前端服务器处理Transfer-Encoding,当其读取到
0\r\n \r\n
认为是读取完毕了。
此时这个请求对代理服务器来说是一个完整的请求,然后转发给后端服务器,后端服务器处理Content-Length请求头,因为请求体的长度为4.也就是当它读取完
12\r\n
就认为这个请求已经结束了。后面的数据就认为是另一个请求:
aPOST / HTTP/1.1\r\n \r\n 0\r\n \r\n
成功报错,造成HTTP请求走私。
0x03:CTF题目考点
在CTF中目前遇到的题目考查点是利用HTTP走私绕waf

题目是一个计算的框,查看源代码得知了calc.php页面,访问得知

通过测试得知,上图只是一个简单的过滤,后台仍然存在waf过滤了字母
那么此时就可以用到HTTP走私来进行bypass
构造前

构造后

如上图所示,添加两个Content-Length即可进行HTTP走私
效果类似第一个Content-Length相当于欺骗waf 我是一个POST表单,顺利通过后传到后台服务器进行处理,成功解析Phpinfo页面。
0x04:总结
虽然HTTP走私漏洞实际挖掘漏洞过程中很少涉及
触发条件苛刻
但不失为一种好的突破方式,日常测试中可以加两个Content-Length观察返回包
作为开发和安全运维人员来说,要严格遵守RFC协议所制定的标准方可避免走私漏洞的存在。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号