
论文泛读 A Novel Ensemble Learning-based Approach for Click Fraud Detection in Mobile Advertising [1/10]
title:新的基于集成学习的移动广告作弊检测
导语:基于buzzcity数据集,我们提出了对点击欺诈检测是基于一组来自现有属性的新功能的一种新方法。根据所得到的精度、召回率和AUC对所提出的模型进行评估。最后的模型基于6种不同的学习算法。我们用刚才说的三种指标,来证明模型是稳定的。我们的最终模型在训练、验证和测试数据集上显示了改进的结果,从而证明了它对不同数据集的普遍性。
1.Introduction 导入
大部分都是废话
1.1 Problem Formulation 问题构建
数据是用的buzzcity的数据,数据格式:http://www.dnagroup.org/PDF/FDMADataDescription.pdf
一个二分类问题,检测流量方publisher是是否在作弊。(实际上训练集里面有三种label,作弊,未作弊,和不确定)
衡量标准:resulting precision, recall and the area under the ROC curve,准确率,召回率,和AUC
2 Data Preprocessing and Feature Creation 数据预处理和特征工程
2.1 数据预处理:
先找出有用的特征,所有的数据为iplong, agent, partner id, campaign ID, country, time-at, category, referrer in the clicktable and partner id, address, bank account and label in the partner table,去掉无用的,比如partner address, bank account。
合并两个表(publisher database and click database)
2.2 特征提取:
借鉴了google反作弊的特征选择,以及其他的传统方向。
对于时间而言:作弊的方法一般有,第一种通常会使用各种技巧伪装自己的活动,例如生成非常稀疏的点击序列、IP地址的更改、从不同国家的计算机发出点击等等。另一些坚持只在给定时间间隔内产生最大点击次数的传统方法。针对这些,我们会选择1 min, 5 min, 1 hours, 3hours and 6 hours.的时间间隔,来统计他们的总点击次数,最大点击数、平均点击数、偏度和方差。
实际上我们就只会对于每一个时间间隔,统计平均值,最大值,方差,偏度

对于IP而言:构造五种特征:
1.最大同IP点击:一个IP地址最多的点击数量
2.IP数量:就对于每一个流量方,点击它广告的IP数量
3.每个IP的平均点击数量
4.熵的计算:IP点击的熵
5.方差:IP点击数量的方差
有些作弊是采用在一些ip上进行大量的点击,所以导致方差变高。
剩下的特征都差不多处理方式,类似于IP,一共创造了41种特征,链接在下面:http://www.dnagroup.org/PDF/FDMAFeatures.pdf
2.3 特征选择
特征选择用了三种方法:主成分分析(PCA)、公共空间模式(CSP)和wrapper subset evaluation
https://en.wikipedia.org/wiki/Principal_component_analysis
https://en.wikipedia.org/wiki/Common_spatial_pattern
wrapper subset evaluation是贪心的选择出一些特征集合来进行训练,用10-fold来进行衡量
3.Experimental Configuration 实验配置
3.1 Datasets
三个集合,训练集,从训练集拆出来的验证集,测试集。
训练集中,click database有3173834个实例,每个实例表示一个点击。publisher database有3081个,并且有标签标识是否在作弊。
验证集:2689005个点击,3064个publisher
测试集:2598815点击, 2112 publisher.
3.2 Platform and Tools Used
i7cpu,8G内存。特征的预处理用的matlab,数据存储用的mysql,模型训练用的WEKA。
3.3 Methods Used 方法使用
论文在这儿,说了一堆废话,他尝试了很多模型,发现决策树最厉害,所以我们就用决策树了。
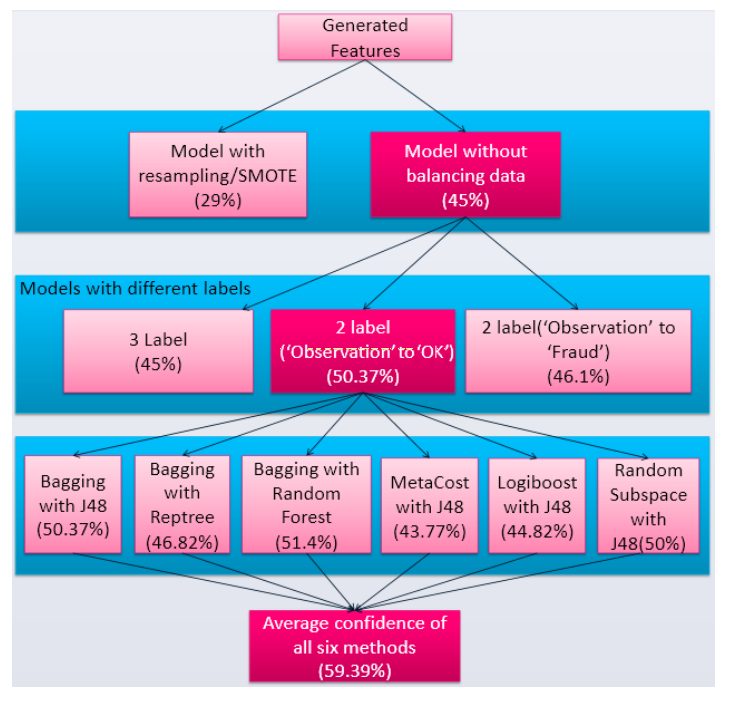
在我们的数据中数据有2.336的作弊者、2.596的不确定和95.068的未作弊,我们面临数据倾斜的问题。为了解决这个问题,我们用了smote算法来拟合出更多的反例。
用了Bagging Metacost还有 logiboost来进行集成学习。
4 Results
用acc作为衡量标准,模型为:
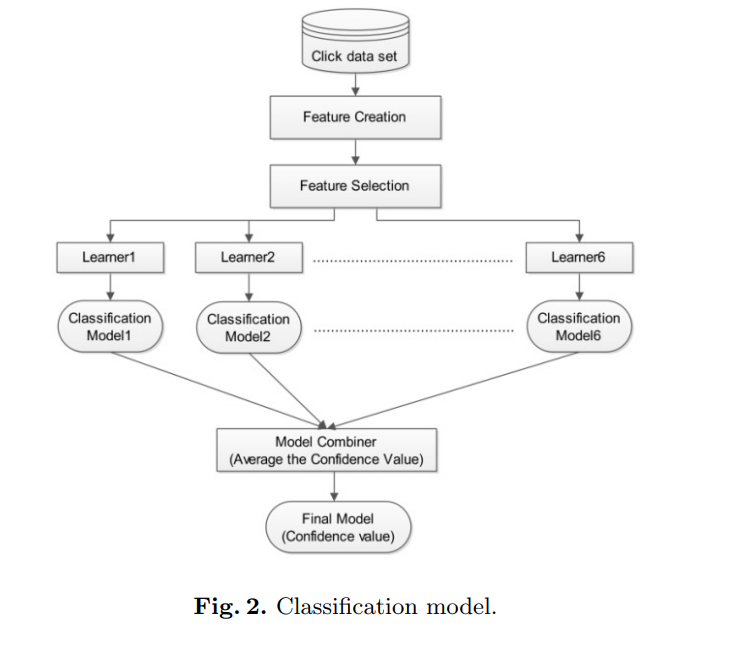
最后将6个模型取平均,就得到了最后的答案。

基础模型,总共就上面三种之一。
然后作者给我们展现了,如果你不做某个环节,你就亏了的故事。
5 Discussions and Conclusion
作者总结出,作弊者一般采用更换代理,点击间隔在1min~6hour之间的一些方法来作弊。
作者表示以后应该多用一些特征处理方法,比如做一些交叉特征来处理。
特征工程方面:
样本不均匀:过抽样和欠抽样,smote。或者构建小的数据集,类似随机森林。
在模型融合方面:作者太过于粗糙,实际上还有stacking,blending等方法https://mlwave.com/kaggle-ensembling-guide/

