
零碎笔记: jvm垃圾回收器之G1收集器(关键词:记忆集,卡表)--链接到jvm书,面试笔记
@
G1采用标记-整理
初步介绍:
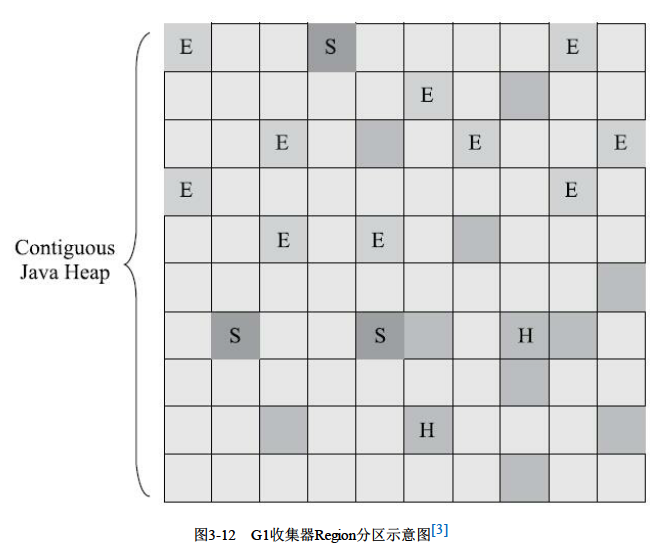
G1收集器主要有初始标记,并发标记,最终标记和筛选删除四部分,G1收集器主要的特点就是它虽然理论上还有新生代和老年代概念,但是却将内存分为若干个大小相等的region,会有一个优先回收列表,回收掉回收收益最大的那个region。
G1收集器是一款在server端运行的垃圾收集器,专门针对于拥有多核处理器和大内存的机器,在JDK 7u4版本发行时被正式推出,在JDK9中更被指定为官方GC收集器。它满足高吞吐量的同时满足GC停顿的时间尽可能短。
一些关键问题如何处理?
G1将堆内存“化整为零”的“解题思路”,一些问题如何处理:
跨Region引用对象?
问题1: 将Java堆分成多个独立Region后,Region里面存在的跨Region引用对象如何解决?
使用记忆集避免全堆作为GC Roots扫描
这部分在分代收集和记忆集里有讲
简述分代收集理论:
根据弱,强分带假说,设置新生代,老年代...根据跨带引用假说在新生代上建立记忆集,记录老年代哪些部分有引用, gc这部分即可.
简述记忆集
记忆集是一种用于记录从非收集区域指向收集区域的指针集合的抽象数据结构
记忆集记录精读
不考虑效率和成本,最简单的实现可以用非收集区域中所有含跨代引用的对象数组..但空间开销大,成本高.
在垃圾收集的场景中,收集器只需要通过记忆集判断出某一块非收集区域是否存在有指向了收集区域的指针,故选择更粗狂的颗粒记录,可供选择的有 字节精读,对象精读,卡精读(卡表).
·
卡精度:每个记录精确到一块内存区域,该区域内有对象含有跨代指针.
第三种“卡精度”所指的是用一种称为“卡表”(Card Table)的方式去实现记忆集[
卡表就是记忆集的一种具体实现,它定义了记忆集的记录精度、与堆内存的映射关系等。卡表最简单的形式可以只是一个字节数组.
下图是卡表作为字节数组的示意图,
问题2: 并发标记阶段如何保证收集线程与用户线程互不干扰地运行?
这里首先要解决的是用户线程改变对象引用关系时,必须保证其不能打破原本的对象图结构,导致标记结果出现错误,
该问题的解决办法笔者已经抽出独立小节来讲解过(见3.4.6节):CMS收集器采用增量更新算法实现,而G1收集器则是通过原始快照(SATB)算法来实现的
什么是原始快照?--见链接
原始快照的理解: 如果删除黑色 指向白色的引用, 同上面, 也是先记下,回头再gc扫描.
原始快照用来解决:可达性分析的"对象消失"问题.
原始快照要破坏的是第二个条件,当灰色对象要删除指向白色对象的引用关系时,就将这个要删
除的引用记录下来,在并发扫描结束之后,再将这些记录过的引用关系中的灰色对象为根,重新扫描
一次。这也可以简化理解为,无论引用关系删除与否,都会按照刚刚开始扫描那一刻的对象图快照来
进行搜索。

