
空洞卷积
参考:https://www.cnblogs.com/houjun/p/10275215.html
https://www.jianshu.com/p/f743bd9041b3
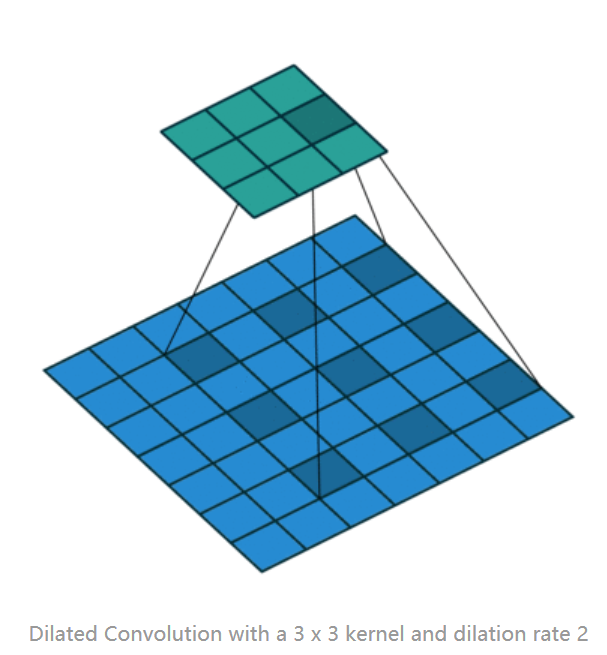
正常卷积运算
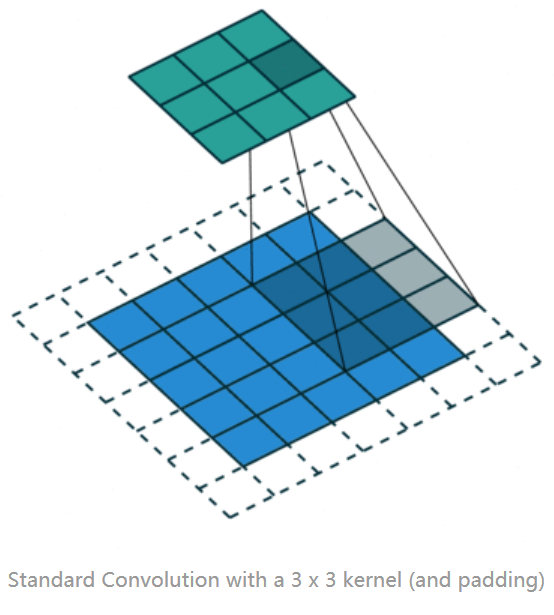
二、提出的原因
Deep CNN 对于其他任务还有一些致命性的缺陷。较为著名的是 up-sampling 和 pooling layer 的设计。
主要问题有:
1、Up-sampling / pooling layer (e.g. bilinear interpolation) is deterministic. (参数不可学习)
2、内部数据结构丢失;空间层级化信息丢失。
3、小物体信息无法重建 (假设有四个pooling layer 则 任何小于 2^4 = 16 pixel 的物体信息将理论上无法重建。)
在这样问题的存在下,语义分割问题一直处在瓶颈期无法再明显提高精度, 而 dilated convolution 的设计就良好的避免了这些问题。
三、膨胀卷积的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者自然语言处理中需要较长的sequence信息依赖的问题中,都能很好的应用。
1 tf.nn.atrous_conv2d(value,filters,rate,padding,name=None)
value:输入的卷积图像,[batch, height, width, channels]。
filters:卷积核,[filter_height, filter_width, channels, out_channels],通常NLP相关height设为1。
rate:正常的卷积通常会有stride,即卷积核滑动的步长,而膨胀卷积通过定义卷积和当中穿插的rate-1个0的个数,实现对原始数据采样间隔变大。
padding:”SAME”:补零 ; ”VALID”:丢弃多余的
膨胀后的卷积核尺寸:
膨胀的卷积核尺寸 = 膨胀系数 * (原始卷积核尺寸 - 1) + 1
kd = k +(k-1)·(r-1),其中kd是膨胀后的卷积核大小,k是原卷积核大小,r是膨胀系数
膨胀卷积感受野:
[(n-1)*(ksize+1)+ksize]×[(n-1)*(ksize+1)+ksize],n = 膨胀系数
空洞卷积的叠加感受野计算方法,下面来介绍一下空洞卷积的感受野变化(卷积核大小为 ,stride=1,下面的卷积过程后面的以前面的为基础):
1-dilated conv:rate=1的卷积其实就是普通 因此
(
)卷积因此感受野为
2-dilated conv:rate=2可以理解为将卷积核变成了 ,因此
(
)感受野大小为
。
4-dilated conv:rate=4可以理解为将卷积核变成了 因此
(
)感受野大小为 15×15
可以看到将卷积以上面的过程叠加感受野变化会指数增长,感受野公式为 2i+2−1,for i = 0,1,2,3,4
四、空洞卷积工作原理
二维

(a)图对应3x3的1-dilated conv,和普通的卷积操作一样,(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,
只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,
但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,
所以1-dilated和2-dilated合起来就能达到7x7的conv),(c)图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。
对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
a,b,c三张图都是以前面结果为基础,a的感受野是3x3,b以a图进行卷积,b本身感受野为5x5(以原图进行卷积,图b示黑色正方形区域)加上以a的3x3感受野变成7x7,即,b图的红点对应a图的卷积结果,对应原图9x9像素。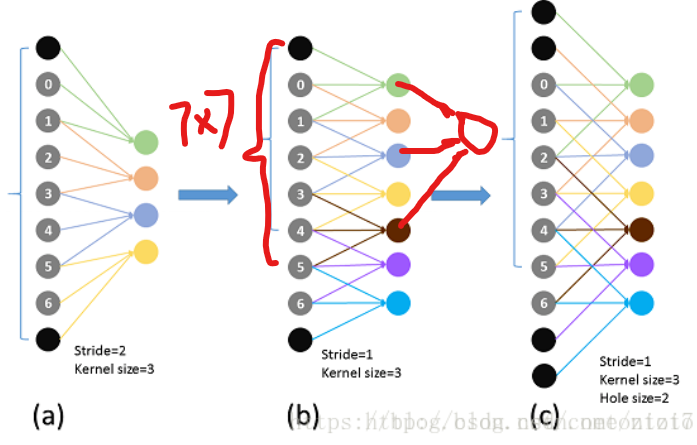
(a)为k=3,stride=2 的普通卷积;(b)为k=3,stride=1的卷积;(c)为k=3,stride=1,dilation=2的空洞卷积,这里虽然卷积核长度仍为3,但每隔2个点采样一次(也可以理解为长度为5但其中两个位置权重为0)
以一维图b红色笔所示k=3,stride=1,dilation=1的卷积 + k=3,stride=1,dilation=2的空洞卷积之后每个feature maps像素对应叠加感受野是7x7。同理二维也一样。五、问题
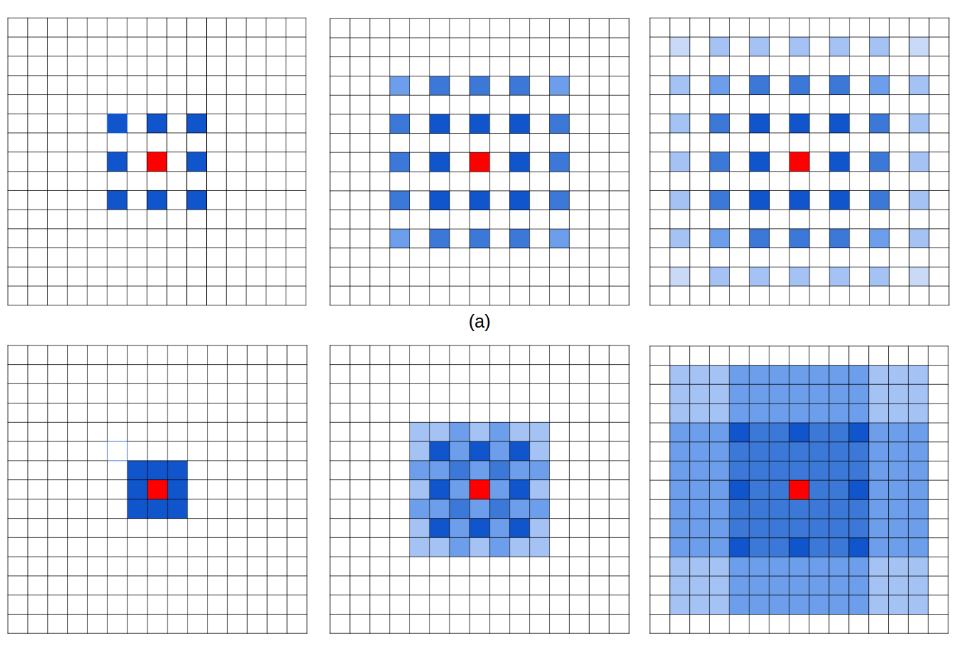
图2.网格问题的图示。 从左到右:像素(用蓝色标记)有助于通过三个内核大小为3×3的卷积层计算中心像素(用红色标记)。 (a)所有卷积层都具有膨胀率= 2.(b)随后的卷积层的膨胀率分别为r = 1,2,3。
我们发现我们的 kernel 并不连续,也就是并不是所有的 pixel 都用来计算了,因此这里将信息看做 checker-board 的方式会损失信息的连续性。这对 pixel-level dense prediction 的任务来说是致命的。
我们将其称为“网格化”(图2):对于空洞卷积层L中的像素p,对像素p有贡献的信息来自来自以p为中心的层L-1中的附近kd×kd区域。。由于扩张卷积在卷积核中引入零,因此从kd×kd区域参与计算的实际像素仅为k×k,
它们之间的间隙为r-1。如果k = 3,r = 2,则该区域中仅25个像素中的9个用于计算(图2(a))。由于所有层具有相等的膨胀率r,那么对于顶部扩张卷积层L中的像素p,有助于计算p值的最大可能位置数是(w'×h')/ r2
其中w' ,h'分别是底部扩张卷积层的宽度和高度。结果,像素p只能以棋盘方式查看信息,并且在信息中丢失大部分(当r = 2时至少75%)。当由于额外的下采样操作而在较高层中变大时,来自输入可能非常稀疏,
这可能不利于学习,因为1)本地信息完全丢失; 2)信息可能在很远的距离上无关紧要。网格效应的另一个结果是第L层的r×r区域附近的像素从完全不同的“网格”集接收信息,这可能损害本地信息的一致性。
2、Long-ranged information might be not relevant.
六、解决办法-通向标准化设计:Hybrid Dilated Convolution (HDC)
在这里,我们提出一个简单的解决方案 - 混合扩张卷积(HDC),以解决这个理论问题。 假设我们有N个卷积层,内核大小为K×K,扩展率为[r1,...,ri,...,rn],HDC的目标是让一系列卷积运算的感受野的最终大小完全覆盖一个正方形 区域没有任何孔或缺少边缘。
第一个特性是,叠加卷积的 dilation rate 不能有大于1的公约数。比如 [2, 4, 6] 则不是一个好的三层卷积,依然会出现 gridding effect。
第二个特性是,我们将 dilation rate 设计成 锯齿状结构,例如 [1, 2, 5, 1, 2, 5] 循环结构。
第三个特性是,我们需要满足一下这个式子:
其中 是 i 层的 dilation rate 而
是指在 i 层的最大dilation rate,那么假设总共有n层的话,默认
。假设我们应用于 kernel 为 k x k 的话,我们的目标则是
,这样我们至少可以用 dilation rate 1 即 standard convolution 的方式来覆盖掉所有洞。
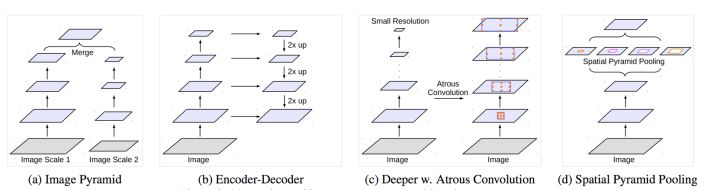
仅仅在一个卷积分支网络下使用 dilated convolution 去抓取多尺度物体是一个不正统的方法。比方说,我们用一个 HDC 的方法来获取一个大(近)车辆的信息,然而对于一个小(远)车辆的信息都不再受用。假设我们再去用小 dilated convolution 的方法重新获取小车辆的信息,则这么做非常的冗余。基于港中文和商汤组的 PSPNet 里的 Pooling module (其网络同样获得当年的SOTA结果),ASPP 则在网络 decoder 上对于不同尺度上用不同大小的 dilation rate 来抓去多尺度信息,每个尺度则为一个独立的分支,在网络最后把他合并起来再接一个卷积层输出预测 label。这样的设计则有效避免了在 encoder 上冗余的信息的获取,直接关注与物体之间之内的相关性。
改进了ASPP包含:
 即,当output_stride=16时,包括一个1×1 convolution和3×3 convolutions,其中3×3 convolutions的rates=(6,12,18),(所有的filter个数为256,并加入batch normalization)。需要注意的是,当output_stride=8时,rates将加倍;
即,当output_stride=16时,包括一个1×1 convolution和3×3 convolutions,其中3×3 convolutions的rates=(6,12,18),(所有的filter个数为256,并加入batch normalization)。需要注意的是,当output_stride=8时,rates将加倍;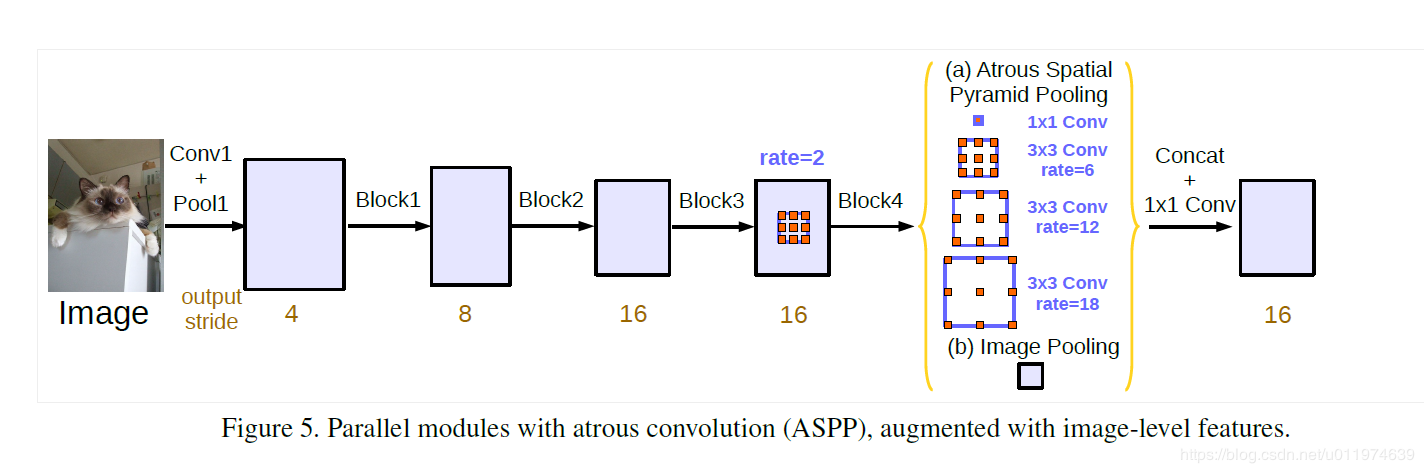
参考:https://blog.csdn.net/u011974639/article/details/79144773
https://blog.csdn.net/gzq0723/article/details/80153848


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· Deepseek官网太卡,教你白嫖阿里云的Deepseek-R1满血版
· 2分钟学会 DeepSeek API,竟然比官方更好用!
· .NET 使用 DeepSeek R1 开发智能 AI 客户端
· DeepSeek本地性能调优
· autohue.js:让你的图片和背景融为一体,绝了!