
vgg16复现进行图片识别
一、结构
上图就是复现vgg16的全部文件,data文件夹是测试图像,这次复现只是调用别人训练好的模型来识别图片。vgg16.py复现了vgg16的网络结构,并导入了别人训练好的模型参数,utils.py为输入图片预处理的程序,Nclasses.py则是我们给定的每个图像的标签,以及对应的索引值,app.py是我们的调用文件,进行图像识别。
二、代码详解
1、vgg16.py
1 import tensorflow as tf 2 import numpy as np 3 import os 4 import time 5 import matplotlib.pyplot as plt 6 from Nclasses import labels 7 8 VGG_MEAN = [103.939,116.779,123.68] #样本RGB的平均值 9 10 class Vgg16: 11 def __init__(self,vgg16_npy_path=None): 12 if vgg16_npy_path is None: 13 vgg16_npy_path = os.path.join(os.getcwd(),'vgg16.npy') # os.getcwd() 方法用于返回当前工作目录。 14 print(vgg16_npy_path) 15 # 遍历键值对,导入模型参数 16 self.data_dict = np.load(vgg16_npy_path,encoding='latin1').item() # 这里加载vgg16.npy的参数 17 # 遍历data_dict中的每个键 18 for i in self.data_dict: 19 print(i) 20 #前向传播模型 21 def inference(self,images): 22 start_time = time.time() # 获取前向传播的开始时间 23 print('build model started') 24 ## 逐像素乘以 255.0(根据原论文所述的初始化步骤) 25 images_scaled = images * 255 26 # 从 GRB 转换色彩通道到 BGR,也可使用 cv 中的 GRBtoBGR 27 #tf.split()将图像里的rgb通道分离 28 red,green,blue = tf.split(images_scaled,num_or_size_splits=3,axis=3) 29 # 逐样本减去每个通道的像素平均值,这种操作可以移除图像的平均亮度值,该方法常用在灰度图像上 30 bgr = tf.concat(values=[ 31 blue-VGG_MEAN[0], 32 green-VGG_MEAN[1], 33 red-VGG_MEAN[2] 34 ],axis=3) 35 36 37 #构建vgg网络结构 38 ## 接下来构建 VGG 的 16 层网络(包含 5 段卷积, 3 层全连接),并逐层根据命名空间读取网络参数 39 # 第一段卷积,含有两个卷积层,后面接最大池化层,用来缩小图片尺寸 40 # 传入命名空间的 name,来获取该层的卷积核和偏置,并做卷积运算,最后返回经过经过激活函数后的值 41 conv1_1 = self.conv_layer(bgr,'conv1_1') 42 conv1_2 = self.conv_layer(conv1_1,'conv1_2') 43 # 根据传入的 pooling 名字对该层做相应的池化操作 44 pool1 = self.max_pool(conv1_2,'pool1') 45 46 #第二层卷积层 47 # 下面的前向传播过程与第一段同理 48 # 第二段卷积,同样包含两个卷积层,一个最大池化层 49 conv2_1 = self.conv_layer(pool1,'conv2_1') 50 conv2_2 = self.conv_layer(conv2_1,'conv2_2') 51 pool2 = self.max_pool(conv2_2,'pool2') 52 # 第三段卷积,包含三个卷积层,一个最大池化层 53 conv3_1 = self.conv_layer(pool2,'conv3_1') 54 conv3_2 = self.conv_layer(conv3_1,'conv3_2') 55 conv3_3 = self.conv_layer(conv3_2,'conv3_3') 56 pool3 = self.max_pool(conv3_3,'pool3') 57 # 第四段卷积,包含三个卷积层,一个最大池化层 58 conv4_1 = self.conv_layer(pool3,'conv4_1') 59 conv4_2 = self.conv_layer(conv4_1,'conv4_2') 60 conv4_3 = self.conv_layer(conv4_2,'conv4_3') 61 pool4 = self.max_pool(conv4_3,'pool4') 62 # 第五段卷积,包含三个卷积层,一个最大池化层 63 conv5_1 = self.conv_layer(pool4, 'conv5_1') 64 conv5_2 = self.conv_layer(conv5_1, 'conv5_2') 65 conv5_3 = self.conv_layer(conv5_2, 'conv5_3') 66 pool5 = self.max_pool(conv5_3, 'pool5') 67 # 第六层全连接 68 #全连接层 69 fc6 = self.fc_layer(pool5,'fc6') # 根据命名空间 name 做加权求和运算 70 fc6_relu = tf.nn.relu(fc6) 71 fc7 = self.fc_layer(fc6_relu,'fc7') 72 fc7_relu = tf.nn.relu(fc7) 73 fc8 = self.fc_layer(fc7_relu,'fc8') 74 # 经过最后一层的全连接后,再做 softmax 分类,得到属于各类别的概率 75 self.out = tf.nn.softmax(fc8,name='prediction') 76 77 # 清空本次得到的模型参数字典,结束前向传播的时间 78 self.data_dict = None 79 print(("build model finished: %ds" % (time.time() - start_time))) 80 81 #创建卷积层函数,卷积核、偏置都从vgg16.npy中获取 82 def conv_layer(self,conv_in,name): 83 with tf.variable_scope(name): # 根据命名空间找到对应卷积层的网络参数 84 conv_W = tf.constant(self.data_dict[name][0],name= name + '_filter') # 读到该层的卷积核 85 conv_biase = tf.constant(self.data_dict[name][1],name= name + '_biases') # 读到偏置项 86 conv = tf.nn.conv2d(conv_in,conv_W,strides=[1,1,1,1],padding='SAME') # 卷积计算 87 return tf.nn.relu(tf.nn.bias_add(conv,conv_biase)) # 加上偏置,并做激活计算 88 89 #最大池化层 90 def max_pool(self,input_data,name): 91 return tf.nn.max_pool(input_data,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME',name=name) 92 93 #平均池化层 94 def avg_pool(self, input_data, name): 95 return tf.nn.avg_pool(input_data, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name=name) 96 97 # 定义全连接层的前向传播计算 98 def fc_layer(self,input_data,name): 99 fc_W = tf.constant(self.data_dict[name][0],name=name + '_Weight') 100 fc_b = tf.constant(self.data_dict[name][1],name=name + '_b') 101 102 shape = input_data.get_shape().as_list() #获得输入的维度信息列表 103 dim =1 104 for i in shape[1:]: 105 dim *= i # 将每层的维度相乘,即,长*宽*通道数 106 # 改变特征图的形状,也就是将得到的多维特征做拉伸操作,只在进入第六层全连接层做该操作 107 input_data = tf.reshape(input_data,[-1,dim]) 108 109 return tf.nn.bias_add(tf.matmul(input_data,fc_W),fc_b) # 对该层输入做加权求和,再加上偏置 110 111 # 定义百分比转换函数 112 def percent(self,value): 113 return '%.2f%%' % (value * 100) 114 #判断图片类别函数 115 def test(self,file_path,prob): 116 #定义一个figure画图窗口,并指定窗口的名称,也可以设置窗口的大小 117 fig = plt.figure(u"Top-5 预测结果") 118 synset = [l.strip() for l in open(file_path).readlines()] 119 120 # argsort函数返回的是数组值从小到大的索引值 121 # np.argsort 函数返回预测值(probability 的数据结构[[各预测类别的概率值]])由小到大的索引值, 122 # 并取出预测概率最大的五个索引值 123 top5 = np.argsort(prob)[-1:-6:-1] 124 #print(pred) 125 126 # 定义两个 list---对应的概率值和实际标签(zebra) 127 values = [] 128 bar_label = [] 129 # 输出概率组大的5种可能性,并且和标签一一列举 130 for n, i in enumerate(top5): 131 print("n:", n) 132 print("i:", i) 133 values.append(prob[i])# 将索引值对应的预测概率值取出并放入 values 134 bar_label.append(labels[i]) # 根据索引值取出对应的实际标签并放入 bar_label 135 # 属于这个类别的概率 136 print(i, ":", labels[i], "----", self.percent(prob[i])) # 打印属于某个类别的概率 137 # 柱状图处理 138 ax = fig.add_subplot(111) # 将画布划分为一行一列,并把下图放入其中 139 # bar()函数绘制柱状图,参数 range(len(values)是柱子下标, values 表示柱高的列表(也就是五个预测概率值, 140 # tick_label 是每个柱子上显示的标签(实际对应的标签), width 是柱子的宽度, fc 是柱子的颜色) 141 ax.bar(range(len(values)), values, tick_label=bar_label, width=0.5, fc='g') 142 ax.set_ylabel(u'probabilityit') # 设置横轴标签 143 ax.set_title(u'Top-5') # 添加标题 144 for a, b in zip(range(len(values)), values): 145 # 在每个柱子的顶端添加对应的预测概率值, a, b 表示坐标, b+0.0005 表示要把文本信息放置在高于每个柱子顶端 146 # 0.0005 的位置, 147 # center 是表示文本位于柱子顶端水平方向上的的中间位置, bottom 是将文本水平放置在柱子顶端垂直方向上的底端 148 # 位置, fontsize 是字号 149 ax.text(a, b + 0.0005, self.percent(b), ha='center', va='bottom', fontsize=7) 150 plt.savefig('.result.jpg') # 保存图片 151 plt.show()# 弹窗展示图像
这一部分我们创建了VGG16网络结构的前向传播,包括卷积核、偏置、池化层以及全连接层,这里需要说一下的是全连接层的建立,这里我们创建全连接层首先需要读取到该层的维度信息列表,然后我们要改变特征图的形状,在第六层将得到的多维特征进行拉伸操作,使其符合全连接层的输入即可,这里的shape中有元素[-1],表示将该维度打平到一维,实现降维的目的。
2、utils.py
from skimage import io, transform import numpy as np import matplotlib.pyplot as plt import tensorflow as tf from pylab import mpl import os mpl.rcParams['font.sans-serif']=['SimHei'] # 正常显示中文标签 mpl.rcParams['axes.unicode_minus']=False # 正常显示正负号 def load_image(path): fig = plt.figure('Center and Resize') img = io.imread(path) # 根据传入的路径读入图片 img = img / 255.0 # 将像素归一化到[0,1] ax0 = fig.add_subplot(131) ax0.set_xlabel(u'原始图片') # 添加子标签 ax0.imshow(img) ## 图像处理部分 #把图片的宽和高减去最短的边,并且求均值,取出切分出的中心图像 short_edge = min(img.shape[:2]) # 找到该图像的最短边 y = int((img.shape[0] - short_edge) // 2) x = int((img.shape[1] - short_edge)// 2) crop_img = img[y:y + short_edge,x:x + short_edge] #取出切分出的中心图像 ax1 = fig.add_subplot(132) ax1.set_xlabel(u"中心图片") ax1.imshow(crop_img) #中心图像resize为224, 224 resized_img = transform.resize(crop_img,(224,224)) ax2 = fig.add_subplot(133) ax2.set_xlabel('切分图片') # 添加子标签 ax2.imshow(resized_img) #plt.show() img_read = resized_img.reshape((1,224,224,3)) # shape [1, 224, 224, 3] return img_read def load_data(): imgs = {'tiger':[],'kittycat':[]} for k in imgs.keys(): dir = './data/' + k for file in os.listdir(dir): if not file.lower().endswith('.jpg'): continue try: resized_img = load_image(os.path.join(dir,file)) except OSError: continue imgs[k].append(resized_img) # [1, height, width, depth] * n if len(imgs[k]) == 2: # only use 400 imgs to reduce my memory load break return imgs['tiger'],imgs['kittycat']
这部分对输入图片进行处理,裁剪,缩放等,以满足网络输入的需要,主要的思路是将图像归一化后进行处理,实现结果如下图所示:

3、app.py
1 import numpy as np 2 import tensorflow as tf 3 import matplotlib.pyplot as plt 4 import vgg16 5 import utils 6 #待检测图像输入,并进行预处理 7 batch = utils.load_image(r'E:\vgg16\for_transfer_learning\data\kittycat/000129037.jpg') 8 9 #定义一个figure画图窗口,并指定窗口的名称,也可以设置窗口的大小 10 fig = plt.figure(u"Top-5 预测结果") 11 print('Net built') 12 with tf.Session() as sess: 13 # 定义一个维度为[?,224,224,3],类型为 float32 的 tensor 占位符 14 images = tf.placeholder(tf.float32, [None, 224, 224, 3]) 15 feed_dict = {images: batch} 16 #类Vgg16实例化出vgg 17 vgg = vgg16.Vgg16() 18 # 调用类的成员方法 inference(),并传入待测试图像,这也就是网络前向传播的过程 19 vgg.inference(images) 20 ## 将一个 batch 的数据喂入网络,得到网络的预测输出 21 probability = sess.run(vgg.out, feed_dict=feed_dict) 22 23 vgg.test('./synset.txt',probability[0])
这部分对上述程序进行调用,对图像进行识别,我们要做的是调用VGG16的网络结构,然后计算概率,输出概率最大的五种可能性,并且和标签一一对应,最后用柱状图画下来,表达出结果.
三、测试
运行app.py,把batch里的图片目录换成你想识别的图片目录即可

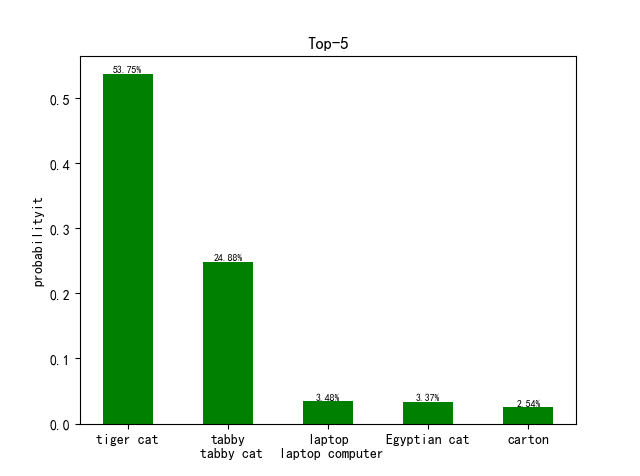
第一组

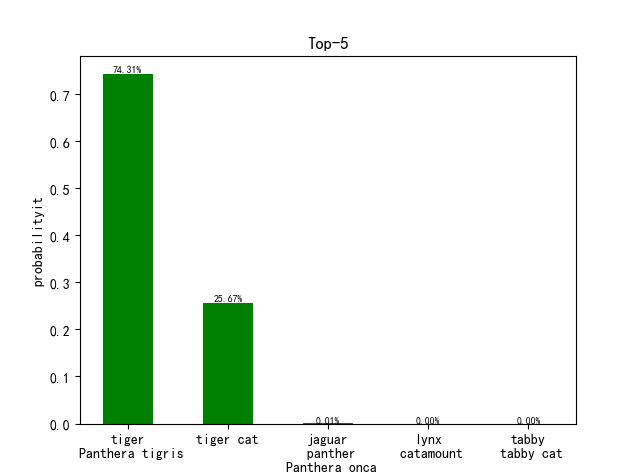
第二组


 浙公网安备 33010602011771号
浙公网安备 33010602011771号