如何使用YOLOv8训练自己的实例分割模型
1. 准备数据集
1.1 将coco json格式的标签文件转换为.txt格式
准备文件夹如下:
而VOCdevkit文件夹中如下
json2txt.py文件中放入以下代码并运行。
import json
import os
import argparse
from tqdm import tqdm
def convert_label_json(json_dir, save_dir, class_id_mapping):
json_paths = os.listdir(json_dir)
for json_path in tqdm(json_paths):
path = os.path.join(json_dir, json_path)
with open(path, 'r') as load_f:
json_dict = json.load(load_f)
image_id_to_annotations = {} # Collect annotations per image
for annotation in json_dict['annotations']:
image_id = annotation['image_id']
if image_id not in image_id_to_annotations:
image_id_to_annotations[image_id] = []
image_id_to_annotations[image_id].append(annotation)
for image_info in json_dict['images']:
image_id = image_info['id']
h, w = image_info['height'], image_info['width']
annotations = image_id_to_annotations.get(image_id, [])
if len(annotations) == 0:
continue
txt_filename = image_info['file_name'].replace('.jpg', '.txt')
txt_path = os.path.join(save_dir, txt_filename)
txt_file = open(txt_path, 'w')
for annotation in annotations:
category_id = annotation['category_id']
label_index = class_id_mapping.get(category_id, -1)
if label_index == -1:
continue
segmentation = annotation['segmentation'][0] # Get the first segmentation polygon
normalized_segmentation = [coord / w if idx % 2 == 0 else coord / h for idx, coord in enumerate(segmentation)]
normalized_segmentation_str = ' '.join(map(str, normalized_segmentation))
label_str = f"{label_index} {normalized_segmentation_str}\n"
txt_file.write(label_str)
txt_file.close()
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='json convert to txt params')
parser.add_argument('--json-dir', type=str, default=r"VOCdevkit\json", help='json path dir')
parser.add_argument('--save-dir', type=str, default=r"VOCdevkit\txt", help='txt save dir')
args = parser.parse_args()
class_id_mapping = {1: 0} # Mapping category_id to label index
json_dir = args.json_dir
save_dir = args.save_dir
convert_label_json(json_dir, save_dir, class_id_mapping)
1.2 划分训练集、验证集、测试集
split_data.py文件中放入以下代码并运行。
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
import argparse
# 检查文件夹是否存在
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def main(image_dir, txt_dir, save_dir):
# 创建文件夹
mkdir(save_dir)
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
img_train_path = os.path.join(images_dir, 'train')
img_test_path = os.path.join(images_dir, 'test')
img_val_path = os.path.join(images_dir, 'val')
label_train_path = os.path.join(labels_dir, 'train')
label_test_path = os.path.join(labels_dir, 'test')
label_val_path = os.path.join(labels_dir, 'val')
mkdir(images_dir);
mkdir(labels_dir);
mkdir(img_train_path);
mkdir(img_test_path);
mkdir(img_val_path);
mkdir(label_train_path);
mkdir(label_test_path);
mkdir(label_val_path);
# 数据集划分比例,训练集80%,验证集10%,测试集10%,按需修改
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
total_txt = os.listdir(txt_dir)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_dir, name + '.jpg')
srcLabel = os.path.join(txt_dir, name + '.txt')
if i in train:
dst_train_Image = os.path.join(img_train_path, name + '.jpg')
dst_train_Label = os.path.join(label_train_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = os.path.join(img_val_path, name + '.jpg')
dst_val_Label = os.path.join(label_val_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = os.path.join(img_test_path, name + '.jpg')
dst_test_Label = os.path.join(label_test_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
"""
python split_datasets.py --image-dir my_datasets/color_rings/imgs --txt-dir my_datasets/color_rings/txts --save-dir my_datasets/color_rings/train_data
"""
parser = argparse.ArgumentParser(description='split datasets to train,val,test params')
parser.add_argument('--image-dir', type=str, default=r"VOCdevkit\images", help='image path dir')
parser.add_argument('--txt-dir', type=str, default=r"VOCdevkit\txt", help='txt path dir')
parser.add_argument('--save-dir', default=r"VOCdevkit\Dataset", type=str, help='save dir')
args = parser.parse_args()
image_dir = args.image_dir
txt_dir = args.txt_dir
save_dir = args.save_dir
main(image_dir, txt_dir, save_dir)
运行过后会在Dataset文件夹中产生如下子文件夹,文件夹中存放着对应内容。至此数据集准备完毕。
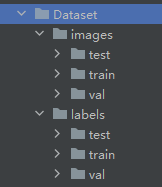
2. 新建data.yaml文件
放入以下内容。并修改文件路径和class name
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: yolo train data=coco.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco ← downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: \split # dataset root dir
train: \split\images\train # train images (relative to 'path') 118287 images
val: \split\images\val # val images (relative to 'path') 5000 images
test: \split\images\test # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
names:
0: pothole
3. 修改default.yaml文件
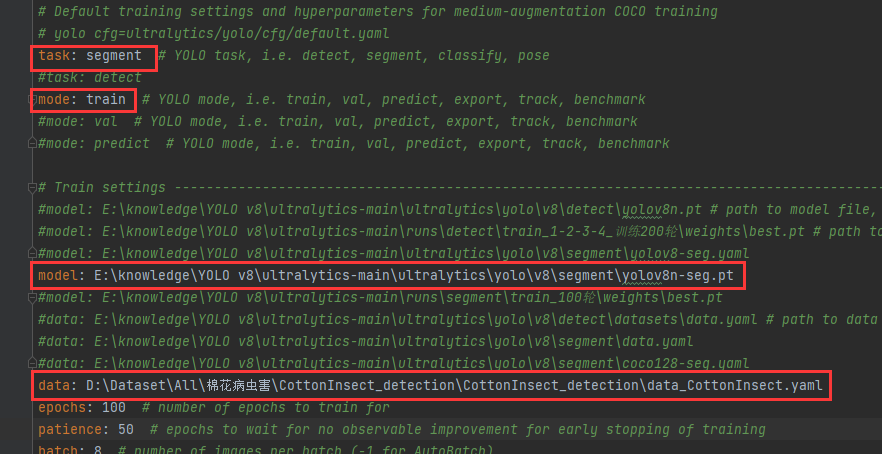
找到YOLO v8\ultralytics-main\ultralytics/yolo/cfg文件路径下的default.yaml文件并打开
task设置为segment;
mode设置为train;
model后设置为预训练模型yolov8n-seg.pt的文件路径;
预训练模型需到官网下载 https://docs.ultralytics.com/tasks/segment/
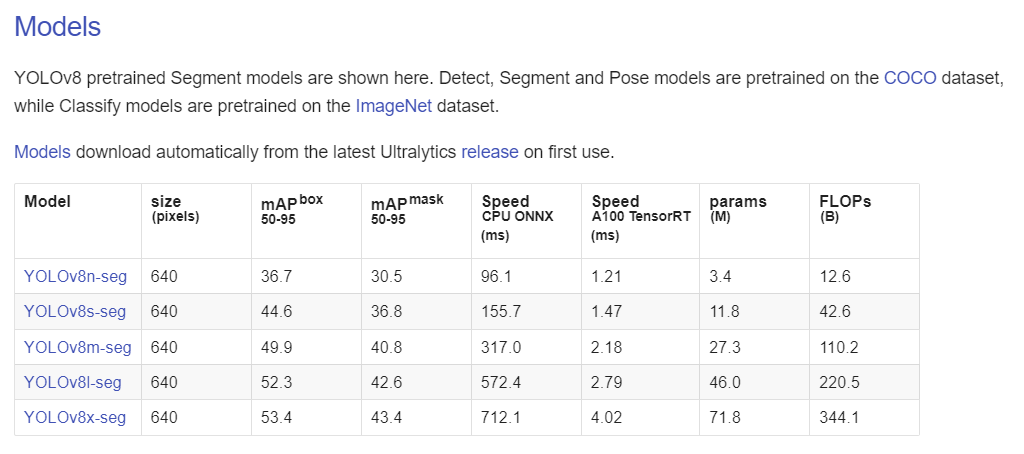
data后设置为《2.新建data.yaml文件》中所述的data.yaml文件的绝对路径;
epoch设置为自己所需的训练轮数;
batch根据自己电脑配置进行设置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号